Backend | Database Scale Out
後端處理中心的 Database Scale Out 是一個重要的議題,相較於 Web Application 無狀態的水平擴展, Database 的水平擴展會困難的多,Database 需要維持 ACID 的特性。
1. Overview
CAP Theorem (Consistency, Availability, Partition Tolerance)
既然在多個節點上使用 Database 也就是分散式儲存,對於分散式儲存的設計來說核心原則就是 CAP Theorem,也就是說在分散式系統中,無法同時滿足一致性 (Consistency)、可用性 (Availability) 和分區容錯性 (Partition Tolerance),只能選擇其中的兩個特性來優先考慮。
ACID 是 Database 在關聯式資料庫中維持資料一致性和可靠性的四個基本特性,分別是:
- Atomicity (原子性): 交易中的所有操作要麼全部完成,要麼全部不完成
- 如果交易中的任何一個操作失敗,整個交易都會被回滾,資料庫將保持不變
- 交易沒有中間狀態,要麼完全成功,要麼完全失敗
- Consistency (一致性): 交易必須使資料庫從一個一致的狀態轉換到另一個一致的狀態
- 當前一個交易完成後,資料庫應該處於一致的狀態,下一個交易開始前,資料庫也應該處於一致的狀態
- Isolation (隔離性): 交易的執行不應該受到其他交易的干擾
- 交易應該像是獨立執行的一樣,即使多個交易同時執行,也不應該互相干擾
- Durability (持久性): 一旦交易完成,對資料庫的修改應該是永久性的,即使系統崩潰也不會丟失
如果要把 Database 分散到多個節點上,要維持上面所說的特性非常困難,尤其是在分散式系統中, 網路延遲、節點失效、資料同步等問題都會對 ACID 的維持造成挑戰。
Database 遵從 ACID 代表優先考慮資料庫的一致性而非可用性,當然也可以遵從 BASE,優先考慮可用性,資料只保證最終會達到一致性, 因此可能會有不一致的狀態存在,但這樣就不適合用在需要強一致性的場景,例如金融交易系統。
BASE (Basically Available, Soft state, Eventual consistency) 強調系統的可用性和彈性,而不是強一致性
我們可以說 BASE 是選擇 CAP 中的 AP 模式,而 ACID 是選擇 CP 模式
2. Master-Slave Replication
從資料庫的行為來看,可以分為讀取和寫入兩種操作,Master-Slave 就是針對這兩種需求的明確分工
Master-Slave Replication 是一種常見的資料庫擴展策略,其中 Master 節點負責處理所有的寫入操作, 而 Slave 節點則負責處理讀取操作。在常見的 CRUD 操作中,讀取操作通常比寫入操作更頻繁, 因此這種架構可以有效地分散讀取負載,提高系統的整體性能。
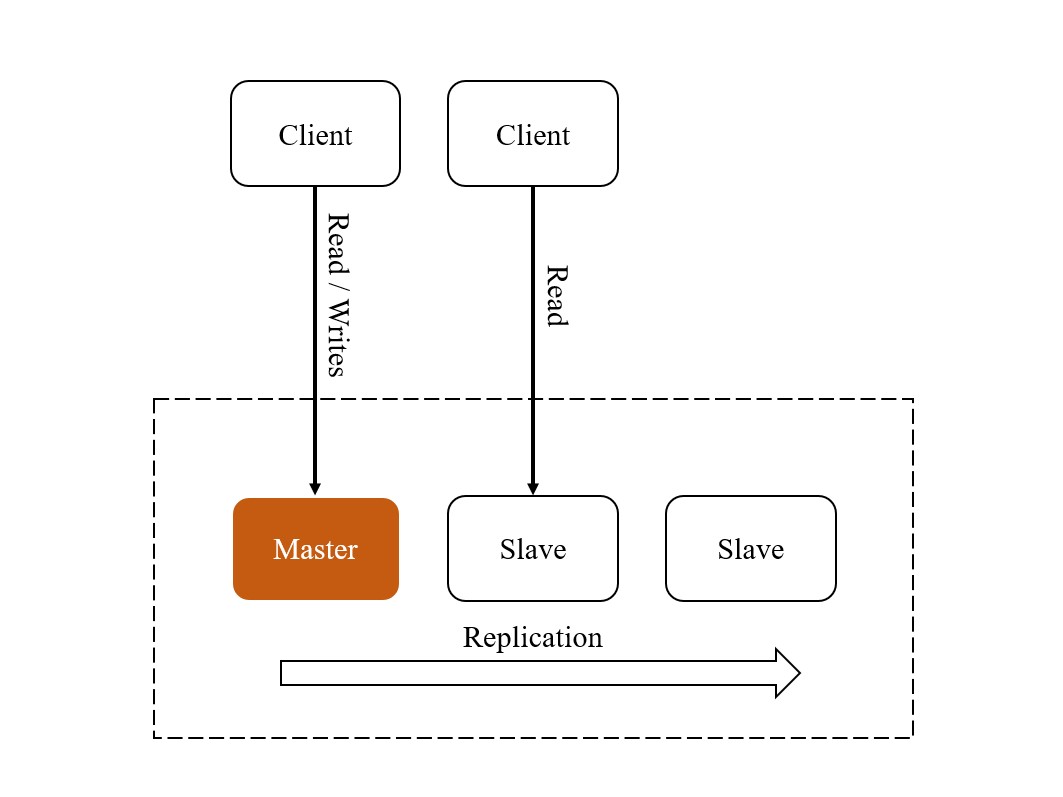
當 Master 故障或不可用時,Slave 節點可以被提升為新的 Master 節點,以確保系統的可用性
Advantages:
- 架構相對來說簡單,是比較容易實現的 Database Scale Out 策略
- 所有節點的資料都是相同的,不需要修改資料模型
Disadvantages:
- 寫入依然受限於 Master 節點的性能,無法真正實現寫入的水平擴展
- Slave 節點的資料是從 Master 節點複製過來因此可能會是 Replication Lag 的狀態
Use Cases:
- 適用於讀取操作遠多於寫入操作的場景
- 例如: 不需要即時性的查詢,統計報表、歷史資料查詢等
在 MariaDB 通常使用 Binlog 來實現 Master-Slave Replication,Master 節點會將所有的寫入操作記錄在 Binlog 中,Slave 節點則會定期從 Master 節點拉取 Binlog 並執行其中的操作,以保持資料的一致性。
2.1 Master-Master Replication
既然 Master-Slave 的架構中寫入依然受限於 Master 節點的性能,那麼我們可以考慮讓多個 Master 節點同時處理寫入操作,這就是 Master-Master Replication
雖然概念上多個 Master 好像就能解決寫入的瓶頸問題,但實際上 Master-Master Replication 的實現非常複雜, 多個 Writer 之間的資料同步和衝突解決是一個非常大的挑戰,尤其是在高併發的場景下,資料衝突的機率會大大增加。
- 多個 Master 節點之間的資料一致性非常困難,通常會違背 ACID 的特性或是為了同步而提高寫入的延遲
- 越多的 Master 節點,只會導致延遲越高,資料衝突的機率越大
在 Master-Slave 保持同步只要保持 Slave 從 Master 拉取 Binlog 就可以了,但在 Master-Master 的架構中有可能產生資料衝突, 例如兩個 Master 節點同時寫入相同的資料,這就需要一個機制來解決衝突,這是一大挑戰。如果處理得不好有可能效能比單一 Master 節點還差。
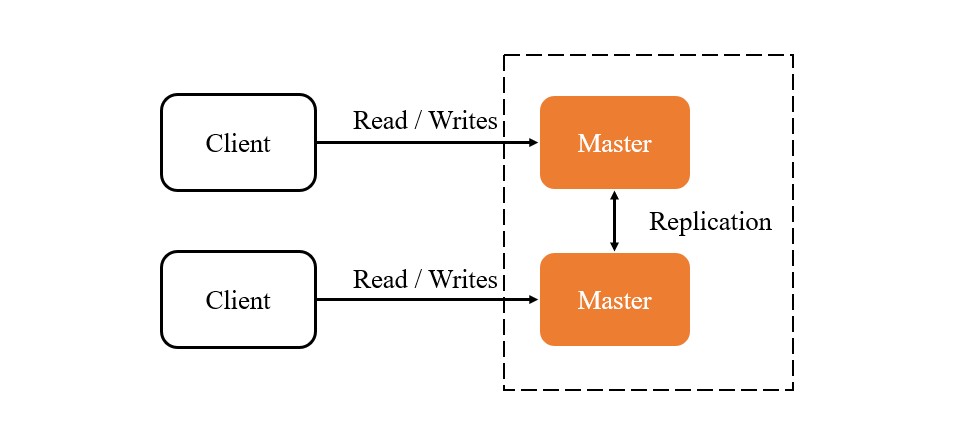
加入越多的 Master 節點,資料衝突的機率就會越大,延遲也會越高
對於 Master-Master Replication 或者 Master-Slave Replication 的架構來說,都會有以下的缺點:
- 在 Copy 還沒完成之前如果節點故障了,有可能喪失資料
- 有越多 Replication 節點,要複製的資料就越多,延遲也會越高
- 如果 Master 節點的寫入量非常大,Slave 節點可能會無法跟上 Master 的寫入速度,導致 Replication Lag 的問題
- 在現代資料庫通常已支援 Multi-Threaded 並行複製來減少 Replication Lag 的問題,但在高併發的場景下仍然可能會有延遲
- Slave 也可能為了處理資料同步的問題導致當下無法提供太多的讀取服務
雖然透過增加 Replication 節點可以提升系統的可用性與讀取能力,但這並不代表系統可以無限制地擴展,增加過多的 Replication 節點可能會導致系統的性能下降
後續我們將這種以 Replication 為基礎的 Database Scale Out 策略稱為 (M/S/R) 架構,因為它的核心概念就是 Master-Slave Replication
3. Federated Database
上面的兩種方法都是以 Replication 的方式來實現 Database Scale Out,這種方式始終無法避免 CAP 中的 CP, 只要增加了 Replication 節點,就會增加資料同步的複雜度和延遲,所以如果想要降低資料同步的複雜度和延遲,我們可以考慮其他方式來分散資料庫的負載。
Federated Database (聯邦式資料庫系統) 將多個獨立的資料庫組合成一個邏輯資料庫
Federated 的核心概念是依照功能來區分資料庫,例如一個線上購物平台可能有:
- User Database: 儲存使用者的資料
- 帳號、密碼、個人資訊 …
- Product Database: 儲存商品的資料
- 名稱、價格、庫存 …
- Order Database: 儲存訂單的資料
- 訂單編號、商品清單、訂單狀態 …
而在這些獨立的資料庫下,還可以使用 Master-Slave 的架構來進行 Replication,以提升讀取的性能。 這樣的策略是避免 Centralized Database 的瓶頸問題,將資料分散到不同的資料庫中,讓每個資料庫專注於處理特定的功能, 同時有機會做到多個資料庫平行寫入 (Writer in parallel),例如特定情境下只需要改變 User Database 的資料, 就不需要等待 Product Database 或 Order Database 的資料同步完成,這樣就可以提升吞吐量。
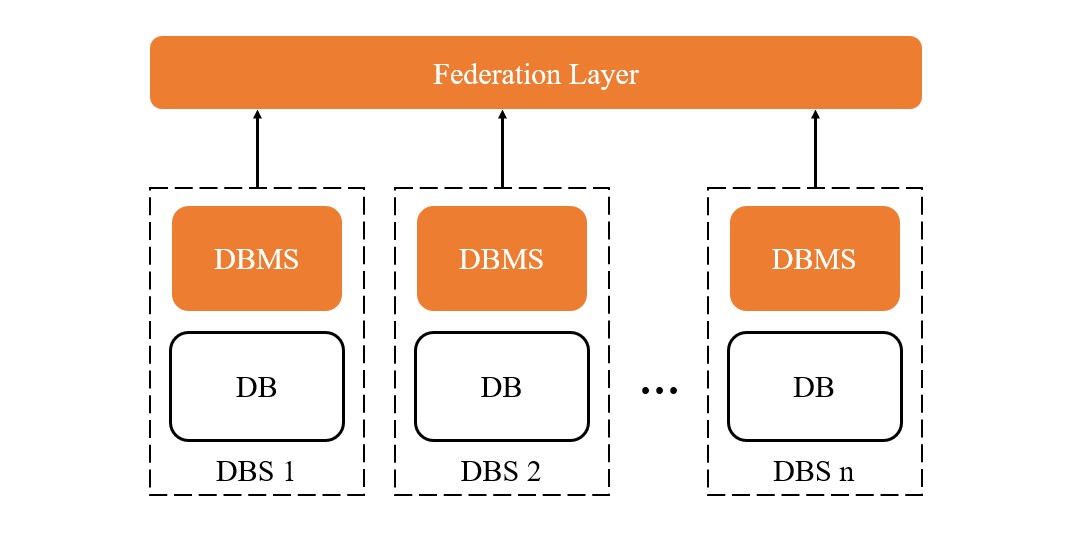
Advantages:
- 依照 Domain 來分散資料庫的負載,讓每個資料庫專注於處理特定的功能
- 可以做到多個資料庫平行寫入,提升吞吐量
- 在低藕荷的情況下,吞吐量可以隨著資料庫的增加而線性提升
- 避免單一資料庫的瓶頸問題,提升系統的可用性和擴展性
- 降低資料同步的複雜度和延遲,因為每個資料庫只需要處理特定的功能,資料之間的依賴性較低
- 故障隔離性較好,當某個資料庫發生故障時,不會影響到其他資料庫的運作
- 符合 Domain-Driven Design 的原則,讓資料庫的設計更符合業務需求
- 也可以說是一種 Microservices 的資料庫設計
- 資料庫之間可以異質化,例如加入 NoSQL 的資料庫來處理特定的資料類型,提升系統的彈性和適應性
Disadvantages:
- 跨資料庫 JOIN 的效率非常差,無法像單一資料庫那樣進行高效的 JOIN 操作,這可能會導致查詢性能的下降
- 例如
JOIN user, order, product
- 例如
- 如果要實現 ACID 的特性,跨資料庫的交易會非常複雜,因為需要確保多個資料庫之間的資料一致性,這可能會導致性能的下降
- 2-Phase Commit (2PC), Saga Pattern
- 查詢效能不穩定,因為跨資料庫的查詢需要進行資料傳輸和整合,這可能會導致查詢的延遲和不穩定性
- 最慢的資料庫會成為整個查詢的瓶頸,導致查詢性能的下降
- 在中間層進行資料整合的過程中,需要使用 CPU / Memory 來處理資料
- 系統複雜性增加,因為需要管理多個資料庫的運作和維護
- Query Routing, Schema Mapping, Service Boundary, Failure handling, Observability …
- 資料模型的設計要更加謹慎
- 必須避免大量的 Cross-domain dependency
- 常見策略是 denormalization / data duplication 在不同的資料庫中儲存相同的資料,但會增加資料同步的成本
在單一資料庫中做 JOIN 是非常高效的,最大的問題是如果資料量大,在 JOIN 之前勢必得將資料庫抓取至某個節點上進行 JOIN 的操作, 這樣資料傳輸就是無法避免的成本消耗,如何設計 JOIN 的策略也是一個重要的議題
Use Cases:
- Business Logic 可以明確區分 Domain 的場景
- 多數請求只需要存取特定資料庫的場景,例如 User Database 的請求只需要存取 User Database 的資料
- 不需要大量的 JOIN 操作,例如 OLAP (Online Analytical Processing) 的場景
- 不需要 Strong Consistency 的場景,例如金融核心業務就不適合使用 Federated Database 的架構
本質上 Federated Database 是用系統複雜度 (Complexity) 與一致性 (Consistency) 來換取寫入分流 (Write Scalability) 與解耦合 (Decoupling)
4. Sharding
Sharding 是另一種常見的 Database Scale Out 策略,與 Federated Database 不同的是,Sharding 是將資料水平切分 (Horizontal Partitioning), 將資料分散到多個節點上,所以每個節點上都會有相同的資料模型
Sharding (分片) 與 Federated Database 很類似,最主要的差異是 Sharding 是同質化的分散,例如我們有一個 User Database, 我們可以依照 User ID 來將資料分散到不同的 Shard 上,例如:
- Shard 1: User ID 1-1000
- Shard 2: User ID 1001-2000
- Shard 3: User ID 2001-3000
這樣可以讓每個 Shard 專注於處理特定範圍的資料,提升系統的可用性和擴展性,同時也可以做到多個 Shard 平行寫入,提升吞吐量。 常見的作法是依照用戶的地理位址或者姓名、ID 來作為 Sharding 的依據。
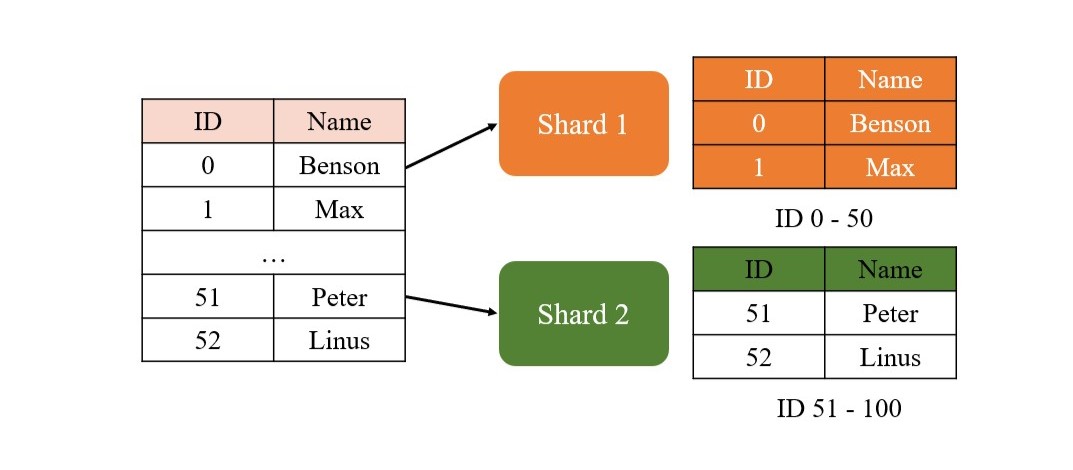
Sharding 的核心挑戰在於如何設計一個好的 Shard key,這需要對業務和資料的特性有深入的理解,選擇一個好的 Shard key 可以讓資料分布均勻, 提升系統的性能和可用性
Advantages:
- 水平擴展能力強,可以隨著 Shard 的增加而線性提升系統的性能
- 如果每個 Shard 的資料量較小,可以提升寫入與查詢的性能
- 儲存成本低,可以分散儲存資料到多個節點上,避免單一節點的儲存大量資料
- 同時每個 Shard 都可以配合 (M/S/R) 的架構來提升讀取的性能
- Less Replication,因為每個 Shard 的資料量較小,可以減少 Replication 的成本和延遲
Disadvantages:
- 跨 Shard 的 JOIN 非常複雜,因為資料分散在不同的 Shard 上,這可能會導致查詢性能的下降
- 這是 Federated Database 和 Sharding 共同的問題,跨節點的 JOIN 都會有性能的問題
- Shard key 設計困難,選擇一個好的 Shard key 是非常重要的,因為它會影響到資料的分布和查詢的性能
- 可能會導致資料分布不均,某些 Shard 的負載過重,而其他 Shard 的負載過輕,這會導致性能的下降
- 例如台灣人姓氏分布不均,如果以姓氏作為 Shard key,可能會導致熱門姓氏的 Shard 負載過重
- Resharding 的成本高,當資料量增加或者 Shard key 的設計不合理時,可能需要進行 Resharding,也就是重新分配資料到不同的 Shard 上,這是一個非常複雜和昂貴的過程
- 需要停機維護,或者使用 Online Resharding 的方式來減少停機時間,但仍然會有性能的影響
Use Cases:
- 資料量極大的場景,單機資料庫無法承受的場景
- 需要高寫入性能的場景,例如社交媒體平台、線上遊戲等
- 查詢有明確的 Shard key 的場景,例如用戶 ID、地理位置等
- 同樣不適合需要大量 Cross-Shard JOIN 的場景,例如 OLAP 的場景
- 在 Strong Consistency 不重要的場景,例如社交媒體平台的貼文和留言等
要注意 Shard 適合的是單一資料表資料量太大,如果確定瓶頸在某個資料表的話,才適合使用 Sharding 的策略,如果是整個資料庫的負載過重, 可能就不適合使用 Sharding 的策略,反而是 Federated Database 的策略比較適合
4.1 Rebalancing
Sharding 的一大挑戰就是當資料量增加或者 Shard key 的設計不合理時,可能需要進行 Rebalancing,也就是重新分配資料到不同的 Shard
Rebalancing 最主要的目的就是讓資料分布更均勻,Shard 有可能因為 Key 設計或者運行一段時間後,由於資料分布不均導致 Shard 成為新的瓶頸, Rebalancing 就是將資料重新分配到不同的 Shard 上,讓每個 Shard 的負載更均勻,提升系統的性能和可用性。
即使最初 Key 設計得再好,隨著時間的推移,資料庫在運行中其內容也會發生變化,這可能會導致資料分布不均,因此 Rebalancing 是 Sharding 架構中不可避免的一個過程
這些 Rebalance 方法這裡用分類策略來簡單非為兩類:
- Static Rebalancing:
- 分類規則是固定的,如果 Shard 改變要重新設計資料分布
- 例如使用 Hash 來決定資料要如何分布,當 Hash 改變時就需要重新分布資料
- Full Resharding, Range-based Rebalancing, Hash-based Rebalancing
- 比較早期的做法,目前大型系統很少直接使用,部分做法需要停機維護,對於線上服務來說是非常不友善的
- Dynamic Rebalancing:
- 分類規則是動態的,根據資料的特性來決定資料要如何分布
- 例如使用 Consistent Hashing 來決定資料要如何分布,當 Shard 改變時只需要重新分布部分資料
- Consistent Hashing, Virtual Nodes
- Auto-Sharding (MongoDB sharding cluster, DynamoDB fully managed partitioning, etc.)
- 目前大型系統常用的做法,可以減少 Rebalancing 的成本和影響,適合線上服務的需求
實際上這種分類是很粗略的,因為 Rebalancing 畢竟是一個分類問題,實際上可以使用的演算法策略非常多,用制式想法來解決 Rebalancing 的問題是非常呆版的, 需要根據業務和資料的特性來設計一個適合的 Rebalancing 策略,這也是 Sharding 架構中非常重要的一個議題。
目前很多主流 Database 都已經支援 Auto-Sharding 的功能,這些 Database 會自動根據資料的特性來決定資料要如何分布,並且在需要 Rebalancing 的時候自動進行 Rebalancing
4.1.1 Consistent Hashing
Consistent Hashing 是一種常見的 Dynamic Rebalancing 的策略,主要的概念是將資料和 Shard 映射到一個環狀的 Hash 空間中,當 Shard 改變時,只需要重新分布部分資料,而不需要重新分布所有資料,這樣就可以減少 Rebalancing 的成本和影響。每次重新分布只需要對 K/n 的資料進行重新分布,其中 K 是資料的總量,n 是 Shard 的數量。
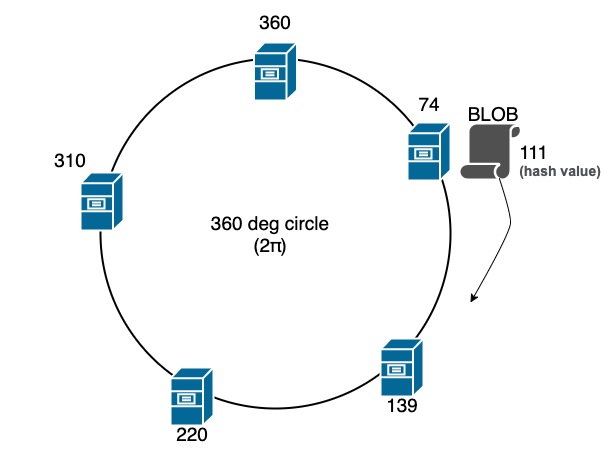
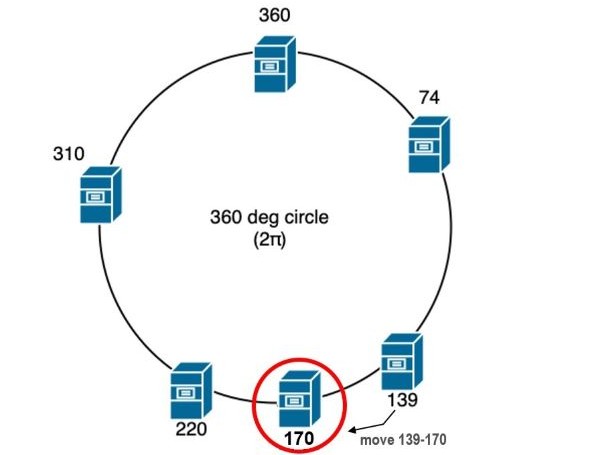
如上圖我們把 Consistent Hashing 想像成一個環形的 Hash 空間,BLOB 在計算完 Hash 後會儲存在 139 這個 Shard 上, 假如我們之後要擴充 139 Shard 的容量,我們可以新增一個 Shard 170,這樣只有 Hash 值在 139 和 170 之間的資料需要重新分布到 170 上, 其他資料則不需要重新分布,這樣就可以減少 Rebalancing 的成本和影響。
Last Edit
03-31-2026 17:04