Computer Organization | Pipelines
1.1 Pipelines Overview
Pipeline 是現代 CPU 提升指令吞吐量的核心機制,而編譯器則必須透過指令排程與最佳化來配合 pipeline,避免 hazards,才能真正發揮硬體效能。
Pipelines 是現代處理器中常用的一種技術,用來提高指令的執行效率。透過將指令的執行過程分成多個階段,處理器可以同時處理多條指令,從而提升整體的吞吐量。 這樣的好處是減少閒置,讓多條指令可以同時在不同的階段進行處理。
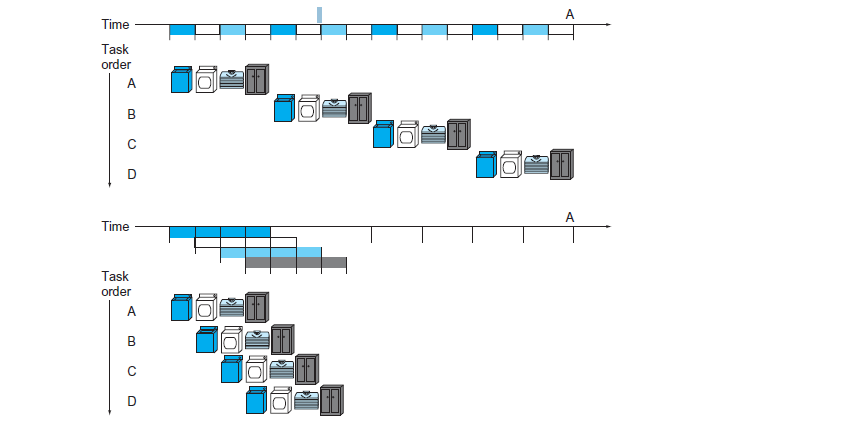
Pipeline 總是拿 Laundry 的例子來說明 如果 A, B, C, D 四個人都分別做洗衣、烘乾、摺衣服、收納將會花費 12 time units、但如果使用 Pipeline 的方式,四個人可以同時進行不同的工作,總共只需要 7 time units 就能完成所有人的工作。
因此在 Pipeline 中主要有三點要注意:
- The work (in a computer, the ISA) is divided up into pieces that more or less fit into the segments alloted for them.
- This implies that in order for the pipeline to work efficiently and smoothly, the work partitions must each take about the same time to complete.
- In order for the pipeline to work smoothly, there must be few (if any) exceptions or hazards that cause errors or delays within the pipeline.
Pipeline 是增加 Throughput 的一種技術,對 Latency 沒有幫助
1.2 Work Partitioning
- Pipeline 可以被分為主個 Stages:
- Instruction Fetch (IF) : fetch instruction from memory
- Instruction Decode (ID) : decode instruction and read registers
- Execute (EX) : execute the operation or calculate address
- Memory Access (MEM) : access an operand in data memory
- Write Back (WB) : write the result back to a register
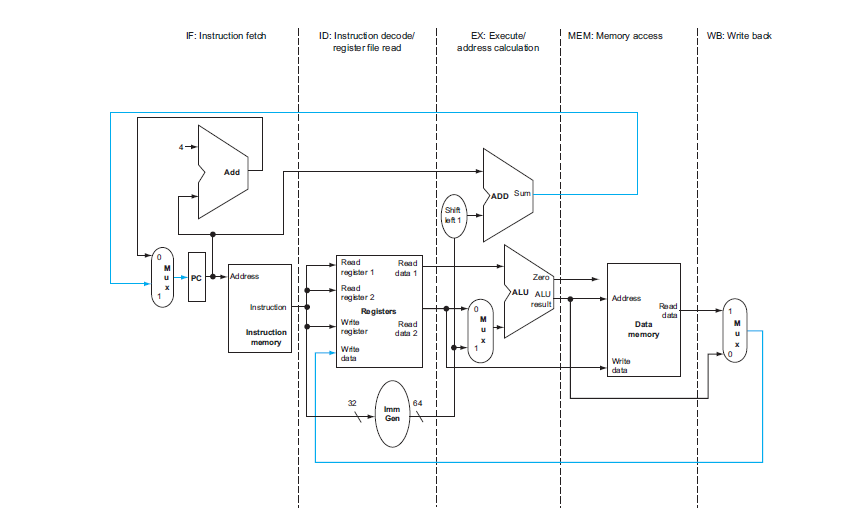
上面的圖是很理想的 Pipeline 狀況,每個 Stage 都剛好在一個 Clock Cycle 內完成工作。
複習一下 Single-Cycle Processor 的工作流程:
- IF:
- 階段透過 MUX 選擇下一個指令的位置,由 Program Counter (PC) 指向下一個指令的位址
- 從 Instruction Memory 中讀取指令,並將 PC 加 4 指向下一個指令或者跳轉位置
- ID:
- 將指令解碼,並從 Register File 中讀取所需的 Read Registers / Write Registers
- 讀取 Register 中的資料由 Read Data 1 / Read Data 2 輸出
- imm Generator 會根據指令類型產生立即數 (32-bit / 64-bit)
- EX:
- ALU 根據 ALU Control 的控制,對 Read Data 1 / Read Data 2 或立即數進行運算
- MEM:
- 根據指令類型,決定是否要對 Data Memory 進行讀取或寫入
- WB:
- 將結果寫回 Register File
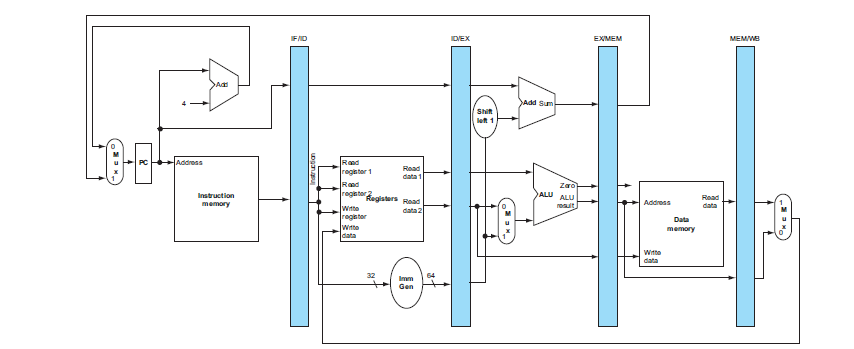
Pipeline registers
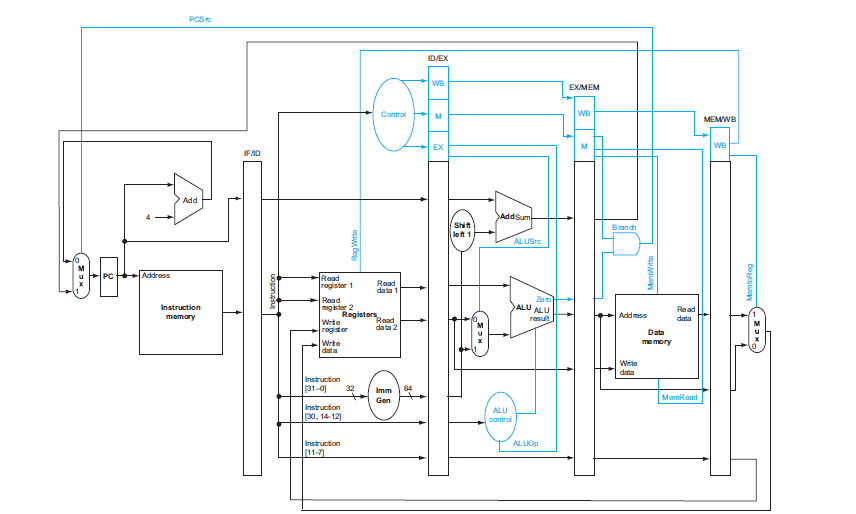
為了確保 Single-Cycle Processor 符合每個 Stage 都在一個 Clock Cycle 內完成工作,我們需要在每個 Stage 之間加入 Pipeline registers,這些 Buffer 用來暫存每個 Stage 的輸出,並在下一個 Clock Cycle 開始時提供給下一個 Stage 使用。
Pipeline register 的功能,是在每個 clock cycle 結束時,儲存該 stage 的輸出資料與對應的控制資訊,並在下一個 cycle 將這些穩定的值提供給下一個 stage 使用。藉由這種「先存、再用」的機制,多條指令才能在同一條 datapath 上同時處於不同 stages,讓 pipeline 在時間上並行運作,而結果仍然正確。
1.3 Pipeline Control
Pipeline control 的作用,是把「這條指令未來每個 stage 要做什麼」的控制決策,在 ID 階段產生後隨指令一起經由 Pipeline registers 傳遞
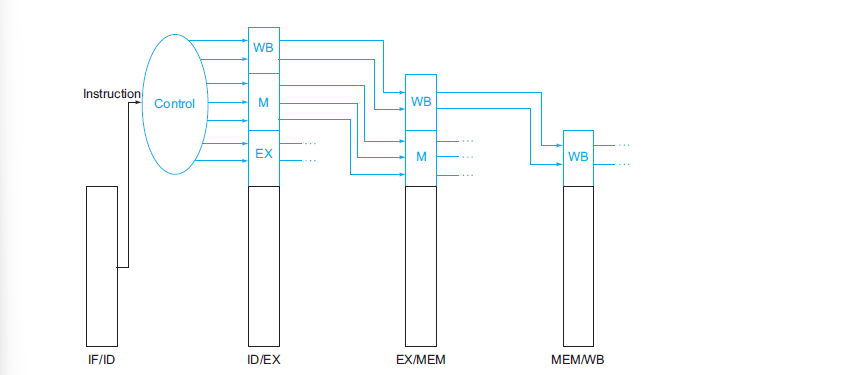
同樣的我們也需要 Control Unit 來產生控制訊號,這些控制訊號會被傳遞到各個 Stage 的控制邏輯中,確保每個 Stage 都能正確地執行其功能。
- IF/ID:
- 將指令的 rs、rt、rd 欄位,以及 opcode、funct 欄位傳遞給 control circuitry
- 用於初始化該指令後續所需的控制資訊
- ID/EX:
- Buffer EX、MEM、WB 三個階段的控制訊號
- 同時執行 EX 階段的控制
- 決定 ALU 的輸入 operand、ALU operation 類型
- 根據 ALU 的 Zero 輸出判斷是否進行 branch
- EX/MEM:
- Buffer MEM、WB 階段的控制訊號
- 同時執行 MEM 階段的控制
- 設定 memory read / write
- 決定寫入 memory 的資料來源
- 包含 branch control logic
- MEM/WB:
- Buffer 並執行 WB 階段的控制
- 決定要寫回 register file 的資料來源
上面說的是理想狀況下的 Pipeline 運作方式,但實際上在 Pipeline 運作過程中會遇到各種問題,這些問題會導致 Pipeline 無法順利運作,這些問題稱為 Hazards,下一篇文章將介紹 Pipeline 中常見的 Hazards 以及解決方法。
Last Edit
11-12-2025 01:50