PDS | Introduction of Parallel and Distributed Systems
這邊紀錄一系列的筆記關於 Parallel and Distributed Systems (PDS) 的課程,主要是希望自己更加了解這個領域,並且在暑假期間能做出一個小的 Demo 來練習。
1. Introduction
分散式系統的具體學習目標,從理論到中間軟體再到實際應用
隨著軟體規模、性能需求的提升,透過低成本多節點的方式來提升系統的效能已經成為一個趨勢。並且分散式在降低硬體成本的同時,也提升了軟體的可靠性、擴展性等等, 但也因此分散式要處裡許多新的技術問題。
- 分散式系統需要分散式理論跟演算法作為基礎:
- CAP theorem
- BASE
- Paxos Algorithm
- Two-phase commit protocol
- Three-phase commit protocol
- 如果不能理解這些基礎的理論,將會對架構跟開發工作帶來困擾
- Technical solutions(技術解決方案):
- Distributed Lock
- Distributed Transaction
- Service Discovery
- Service Protection
- Service Gateway
- Middleware(中間軟體):
- Distributed Coordination Middleware: Zookeeper, etc.
- Service Governance Middleware: Dubbo, Eureka, etc.
- 如果對於這些 Middleware(中間軟體)的功能或者實現原理不了解,同樣會增加開發的困難度
1.2 Application History
1.2.1 Single Application
1.2.2 Cluster Application
1.2.3 Narrowly Distributed Applications
1.2.1 Single Application
最初的應用形式即是部屬在一台機器的單一應用,其中可以包含很多很多 Module,內部的 Module 之間是高度耦合的,但在開發、測試、部屬的成本低廉。 隨著功能與併發數量的提升,通常會帶來兩個挑戰:
- Hardware 上龐大的單體應用需要更多的資源,因此單一主機的成本會提升
- Software 應用內部的 module 之間耦合度高,隨著功能的增加,會導致開發維護變得困難
因此當應用的功能與併發數量提升到一定程度時,就要考慮拆分應用,就演變成了 Cluster Application。
1.2.2 Cluster Application
使用 Cluster 那就要面對在 Cluster 中的節點之間的協作問題,這也是分散式系統的核心問題
Cluster Application 可以對應用的併發與容量進行分散,這裡的 Cluster 包含多個「同質」(Homogeneous) 的應用節點, 這裡會使用「同質」是因為這些節點的功能是一樣的,執行相同的程式、相同的設定,就像是一個副本複製出來的一樣。
例如透過反向代理去做 Load Balance,把外部請求分發到不同的節點上。
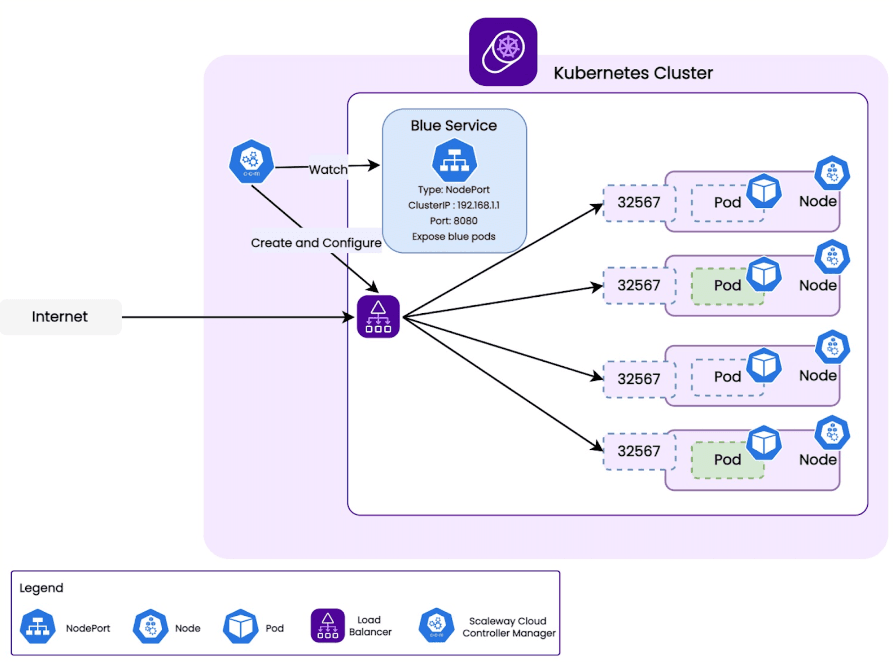
上圖是一個 Kubernetes 的架構,透過 Load Balance 來分發請求到不同的 Pod 就可以提升應用的併發量。
但 Homogeneous Cluster 帶來最明顯的問題是,同一個使用者發出的請求可能會被不同的節點處理,導致服務可能不連貫。 為了解決這種問,演化出了幾種方案。
Stateless Cluster Nodes
Stateless cluster nodes(無狀態叢集節點) 是指任何請求的結果都和該節點之前所處理的請求無關。 例如簡單的 Web Server,每次都回傳相同的 Page,這樣就不需要考慮請求的連貫性,對於使用者來說這個頁面是 stateless。
但是即使是 Stateless 也需要考慮協作,例如: Stateless cluster node 需要每天早上發送一封 Mail 給外部的使用者, 我們希望的是只有一個節點發送這封 Mail,如果沒有考慮到這個問題,可能會導致每個 Node 都發送一封 Mail 給使用者。
- 可能的解法: 設計一個外部的請求,由該外部請求來請求發送,這樣就可以保證只有一個節點被分配到這個任務
Stateless node 設計簡單,可以很方便的擴充,但是也因為要是 Stateless 所以會有很大的侷限性。
Single Cluster Node
雖然 Stateless 很好用,但是畢竟有很多服務是需要狀態的,例如: 聊天室、購物車…
Key words: Fixed allocation, Session affinity
這些服務在 Single application 是很好實現的,但在 Cluster 中就變得複雜起來,一個最簡單的辦法就是在使用的 Node 和 User 之間建立聯繫。 User 可以訪問固定的 Node,這樣就可以保證 User 的狀態是連續的。
- 任意 User 都有一個對應的 Node,在 Node 上保存使用者的 Context information
- User 的請求總是被分配到對應的 Node 上
想要實現這些功能的方法有很多,例如: 線上遊戲由使用者自己選擇 Server、透過帳號來分配 Server 等等 …
當然這樣的方法在各個 Node 之間是互相隔離的,因此在容錯上會比較差。
Shared Information Cluster Node
Shared Information Cluster Node (共用資訊叢集節點) 是為了解決資訊共享的問題,如果有一個共享的資訊庫,那麼所有的 Node 都可以訪問這個資訊庫, 這樣就不用去擔心 Node 崩潰後資訊的丟失,例如下圖:
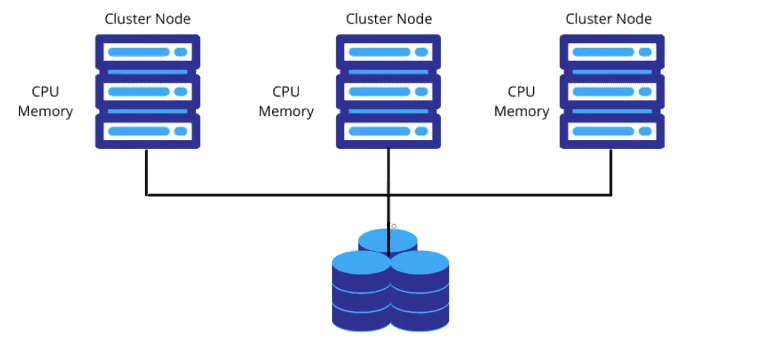
例如: 可以使用 Redis 來做共享記憶體,儲存使用者的 Session 等等。
但是同樣的共享資訊池也會成為一個瓶頸,因為所有的 Node 都要訪問這個資訊池。
Consistent Information Cluster Nodes
為了避免資訊池成為瓶僅,那就橫向擴展資訊池,這樣就可以降低資訊池的壓力,但同樣就會有 Consistent(一致性) 的問題, 例如部分 Node 共用一個 Information Pool,Pool 之間去做一致性。
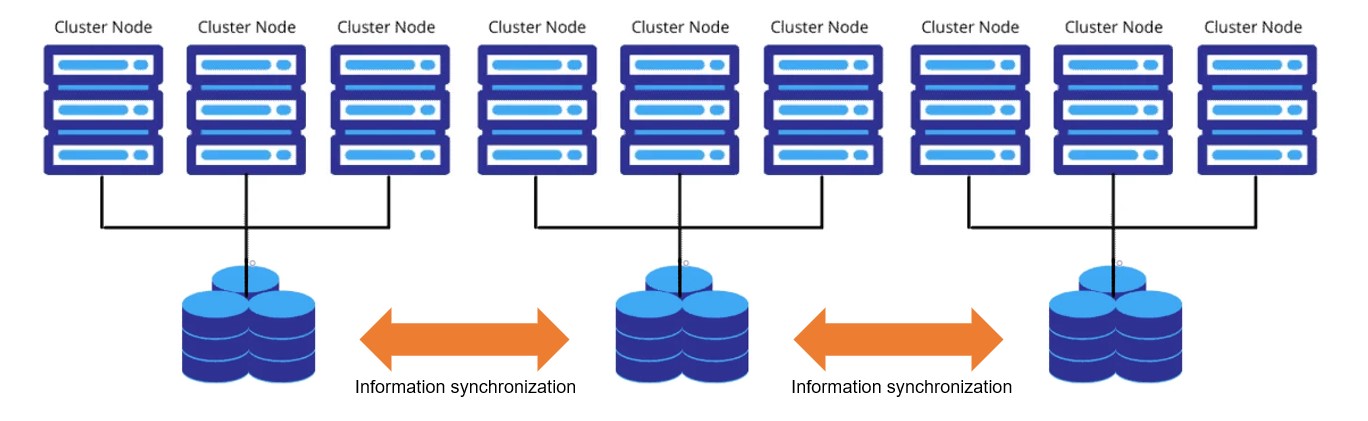
部分 Node 共用同個 Pool,或者乾脆 Pool 加入 Node,在 Node 之間做 Consistent
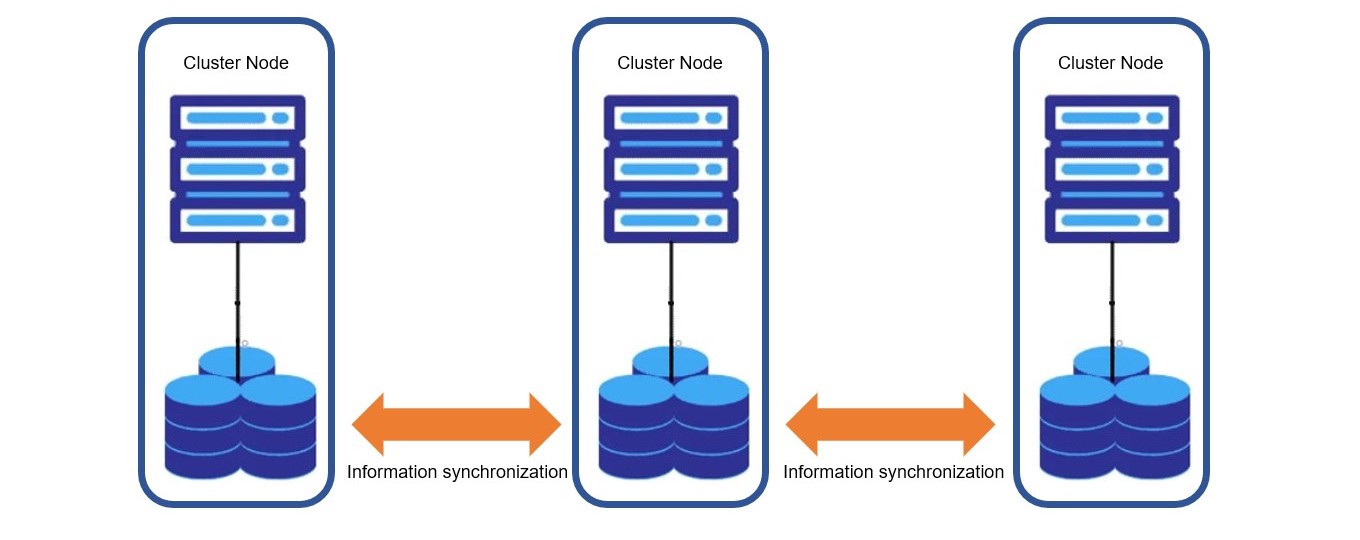
要注意 Consistent 的實施成本非常巨大,你可以想像如果有 1000 個 Pool,那麼每次更新都要通知 1000 個 Pool,這樣的成本是非常高的。 因此 Information-consistent clusters 適合用在讀多寫少的場景。
1.2.3 Narrowly Distributed Applications
Cluster Application 是為了解決併發數量和使用量,並不能減少程式自身的問題
狹義上的分散式系統是指原本是一個 Single application,但是隨著規模的擴大遭遇以下問題:
- 硬體成本, 應用性能, 業務邏輯複雜, 變更維護複雜, 可靠性變差
這些問題都不能透過將 Single application 轉變為 Cluster application 解決時,去把 Single application 拆分成多個獨立的 Sub-application, 讓每個 Sub-application 都是可以獨立運行的,這樣就把 Single application 變成了 Narrowly distributed applications。
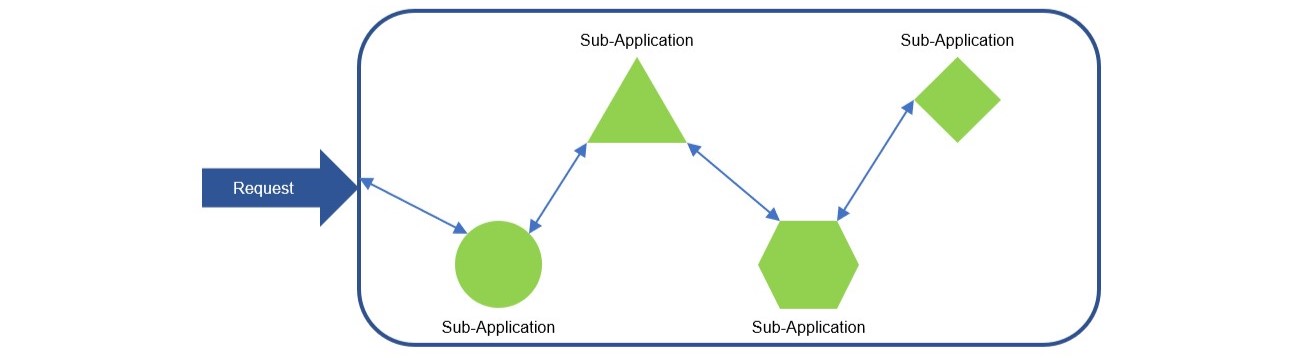
因此每個 Node 上運行的 Application 都是 Heterogeneous 的,可以獨立的開發、部屬、升級、維護。
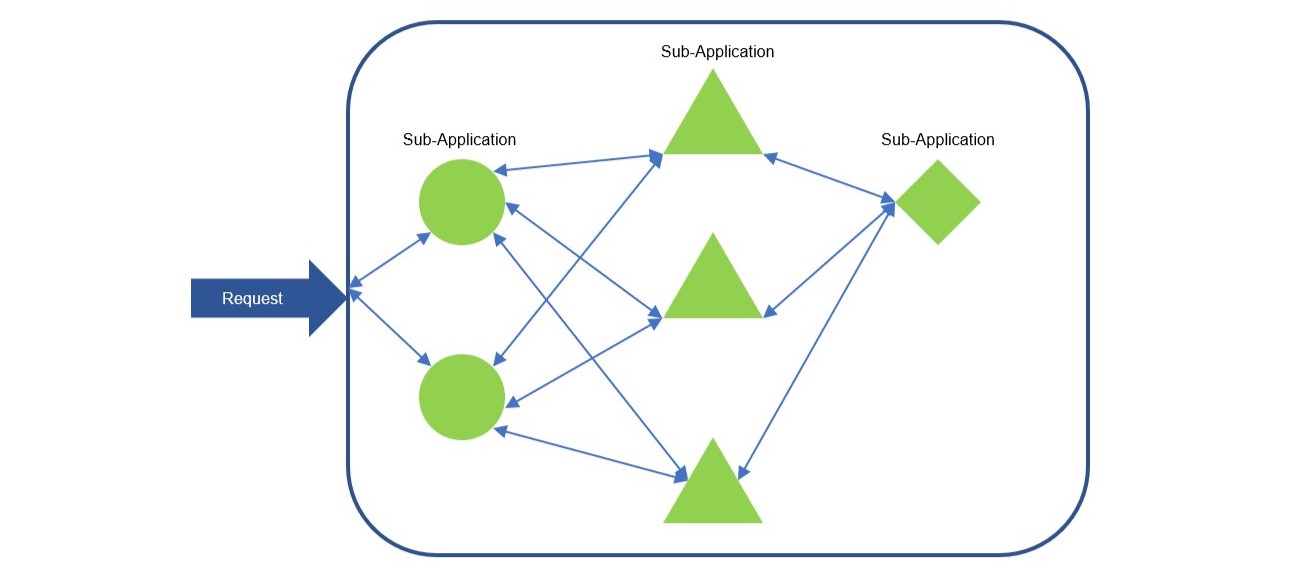
把這些 Sub-Application 擴展成 Cluster
這樣我們也可以把這些 Sub-Applcation 部署到不同的機器上,擴展成一個更大的 Cluster,也就是 Distrubuted System, 也可以依照 Sub-Application 的需求進行 Scaling,更為靈活與高效。
1.2.4 Microservices
在 Narrowly Distributed Applications 的基礎上,Sub-Application 之間有嚴格的從屬關係,這種關係可能會造成資源的浪費。
這裡舉個浪費的例子: 存在 Application A, 包含 3 個 Sub-Application: A1, A2, A3,有可能 A 的某個功能只需要 A1, A2, 但是 A3 就會被閒置,這樣就會造成資源的浪費。
Microservices 是一種 Architecture patte,也就是每個 Microservices 都是完備的,可以獨立對外提供服務, 這樣就可以針對每個 Microservices 進行 Scaling、Resource Allocation。
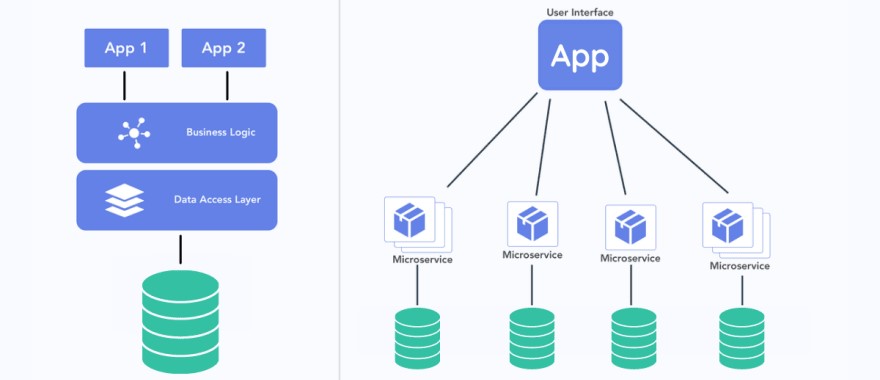
1.3 Distributed System Introduction
如果所有的服務都只能作為系統的一部分聯合起來對外提供服務,那麼這樣的系統就是 Narrowly Distributed Applications, 如果這些服務可以獨立對外提供服務,那麼這樣的系統就是 Microservices。
1.3.2 Distributed System Consistency Problem
最簡單的一致性問題如下,假如 Request 是有序的,那麼我們應該要確保 R1 修改完 a 之後 R2 讀取的 a 是修改後的值。
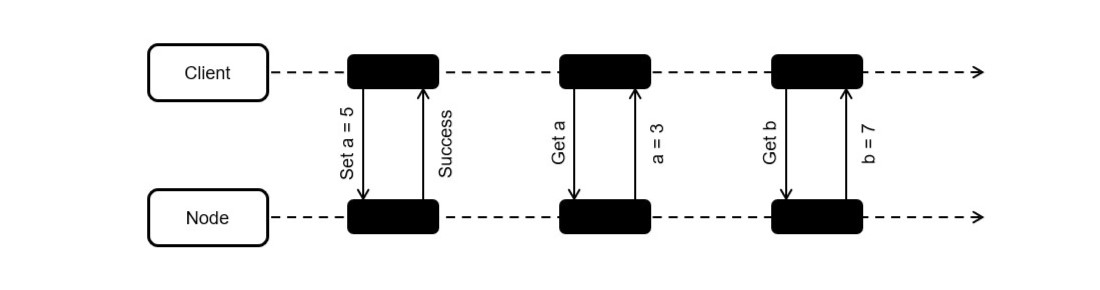
如果一個系統會發生上面的問題,那麼這個系統就是不一致的(至少是線性不一致 Linearizability Inconsistency), 關於一致性的分級會在後續章節提到,這裡只是提一下。
1.3.3 Distributed System Node
在 Distributed System 中,Node 可能是同質的,也可能是異質的。
在同質節點中,當系統發生變更時,所有的節點的變更是一樣的,例如: Zookeeper cluster 收到 Client 發送建立 znode 的請求後, 每個節點都需要建立 znode。
異質節點中,當應用發生變更時,每個節點的變更是不一樣的,例如: 一個網購平台的系統,訂單節點需要建立訂單,庫存節點需要減少庫存。 這也是一種 Consistent 的問題,要確保整個系統的 Consistent。
1.4 Distributed System Advantages & Disadvantages
1.4.1 Advantages
- Reduced Cost:
- 降低系統的實施成本是分散式系統的發展與最初動力,對於硬體強大的大型主機,可以用多個小型叢集上取代
- Improved Availability:
- 提升系統的可用性,即使某個節點失效,也不會影響整個系統
- Improved Performance:
- 提升系統的併發與容量,提升系統的性能
- Reduced Maintenance:
- 由於分散式系統的多個節點,可以降低系統的維護成本,例如: 可以對某個節點進行維護,而不影響整個系統
- 並且因為節點之間是獨立的,可以獨立的平行開發與模組化
1.4.2 Disadvantages
- Consistency:
- 一致性問題是分散式系統的核心問題,要保證系統的一致性是非常困難的,所以在下個章節會先介紹一致性問題
- Node discovery problem:
- 在有許多動態變化的節點時,怎麼發現系統中的可用節點是一個問題
- Node call problem:
- 當系統中有許多節點時,在節點之間的呼叫是經常發生的,但它們也有與之對應的成本
- Node coworking problem:
- 當系統中有許多節點時,節點之間的協作是一個問題,例如: 如何在同質節點中保證一個 Task 只被一個節點執行
- 異質節點也需要解決 Producer-Consumer 問題,例如: 訂單節點需要建立訂單,庫存節點需要減少庫存
這張主要是 Introduction 所以就簡單介紹 Distributed System 的優缺點與發展歷程,後續章節會更深入的介紹 Distributed System。
Last Edit
7-30-2024 19:48