Compiler | Compilers Introduction
Compilers course notes from CCU, lecturer Nai-Wei Lin. 編譯器這門課可以讓人更深入的了解 Programming language,如果能知道編譯器如何將 High level language 轉換為 Machine code 與背後的工作原理, 就能更有效的去編寫程式。在修 OS 的時候更有感覺,有些是針對編譯器與平台的優化去更改寫法,有些小小的改動就能減少數行的指令去提升效能。
linux/lib/rbtree.c 在 6.4 版做了一個非常簡單的 commit,將 bitwise | 換成 +,這個替換使 x86 平台上可以使用 lea Assemble, 將兩道指令變成一道指令。正是了解 Compiler Optimization 才能知道這樣修改有什麼用。
- Human use nature languages to communicate with each other
- Human use programming language to communicate with computers
1.1 Language Processors
廣義的說 Compiler 就是一個可以將一個 Language 翻譯成另一個 Language 的工具,同時 Compiler 的另一個重要功能是發現翻譯過程中 Original language 的錯誤。
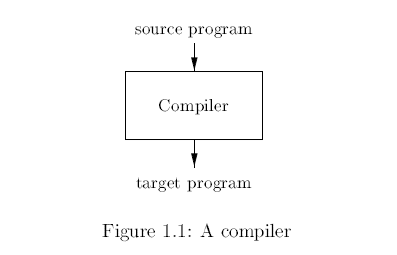

上圖展示了一個 Compiler 與 Interpreter 的差異,另外 Java language process 結合了兩者的過程,既有 Target code 也有用於執行程序的 Interpreter。
但是一個程式語言從 Compile 到 Execute 除了 Compiler 還有很多其他的處理程序,如: Preprocessor、Assembler、Linker、Loader。但這裡專注於 Compiler 的部分, 在 1.2 再詳細說明 Compiler 的結構。
1.2 The Structure of a Compiler
首先我們可以把 Compiler 分為 Frontend/Backend 兩個部分:
- Analysis(Front-End): 將 Source code 分解成多個組成要素,並在這些要素之上加入語法結構。使用這個結構來建立 Intermediate code,並且可以檢查原始程式是否符合正確的語法與語意,並且提供資訊給使用者修改。 並且把 Source code 的資訊收集為 Symbol table,之後將 Intermediate code 與 Symbol table 一起送給後端。
- Synthesis(Back-End): 根據 Intermediate code 與 Symbol table 來建立目標程式
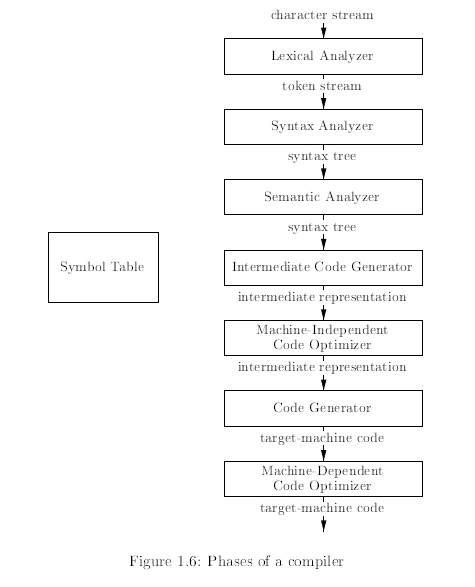
上圖都是 Compiler 的結構,右圖表述了每個步驟之間的更多細節
有些編譯器在前端與後端之間會有 Machine-independent optimization(機器無關的最佳化)步驟,這個最佳化的目的是在 Intermediate code 之間進行轉換。
1.2.1 Lexical analysis
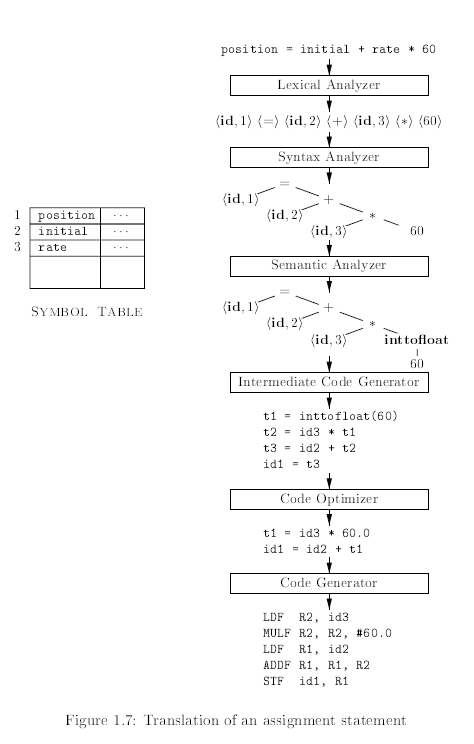
Lexical analysis(語彙分析)也被稱做 Scanning(掃描),是編譯器的第一個步驟,進行讀取原始程式的字元串流,並依據 Lexeme(詞素)來產生 Token(詞彙單位)作為輸出。
- Lexeme: 是 Source code 中具有相同意義的字符序列,如
int,return,=都是 Lexeme。 - Token: 是 Lexical analysis 後的結果,它的形式可能像 <token-name, attribute-value>
- 例如
Position = initial + rate * 60在經過 Lexical Analysis 後會變成:<id, 1> <=> <id, 2> <+> <id, 3> <*> <60>這樣的 Token - 其中 Position 對應 <id, 1>,id 代表 identifier,而 1 指向 Symbol table 中所對應的條目
- 例如
1.2.2 Syntax analysis
Syntax analysis(語法分析)也被稱做 Parsing(解析),使用 Lexical analysis 產生的 Token 來建立 Syntax tree。之後會介紹 Context free grammar 來描述程式語言的語法結構, 並自動為某些類型的語法建構高效率語法分析器的演算法。
1.2.3 Semantic analysis
Semantic analysis(語意分析) 使用 Syntax tree 和 Symbol table 中的資訊來檢查原始程式是否符合程式語言的規則,並且在這裡收集型別的資訊。
- Type checking: 這是 Semantic analysis 的重要部分,檢查每個運算子是否具有一致的運算元。例如: Array 的 Index 應該要為 int,若有 float 就應該回報錯誤。
- Coercion: 程式語言也可以做型別轉換,例如
Position = initial + rate * 60,而所有變數都已經宣告為 float,此時就能將 60 轉換為 60.0。
1.2.4 Intermediate code generation
在 Source code 變成 Target code 的過程中可能會產生一個到多個的 Intermediate representation(IR, 中間表述)也可以稱作為 Intermediate code(中間碼), Syntax tree 也可以算做是一種 IR,這些中間表述應該要有兩個重要的性質: Easy to produce(易於生產), Easy to translate(易於轉譯為 Machine language)
例如使用類似 Assembly language 的一種三位址碼作為 Intermediate code:
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3
- 使用 Intermediate code 還能使我們更好的分離前端與後端,並且也增加了移植性與優化的可能性
- 使用多層的 IR 可以使每層都專注在不同的目標上,這樣可以使編譯過程分隔後更易於模塊化
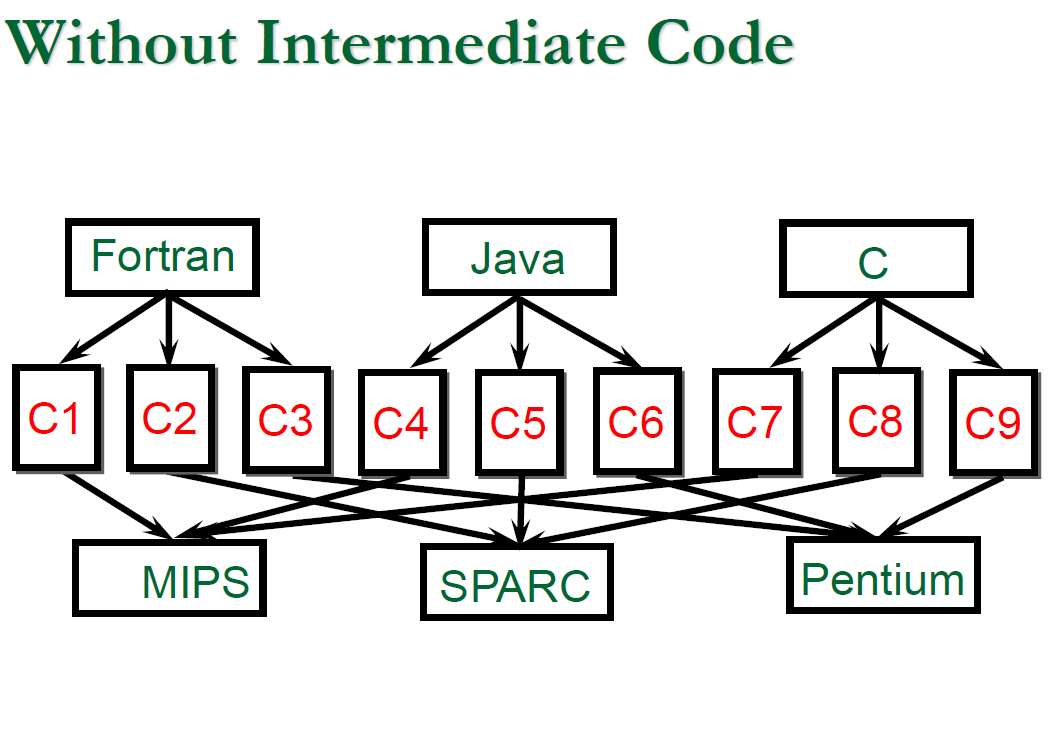
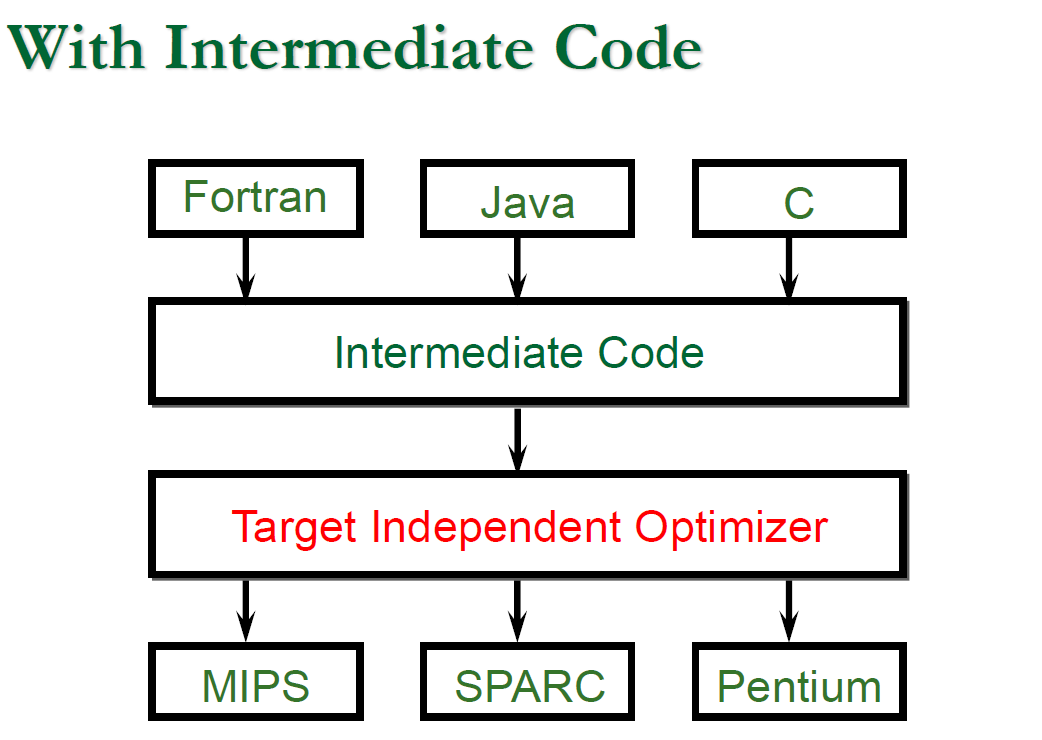
如果不使用 Intermediate code,我們可能要去應對多種對應不同平台的轉換
1.2.5 Code optimization
Code optimization 的目的在於將程式碼變得更「好」,這裡指的並不只是效能上的提升,例如更短或者占用資源更少的目的碼。 分為 Machine-independent(機器無關) 和 Machine-dependent(機器相關)的最佳化:
- Machine-independent: 發生在 Compiler 的中間階段,也就是生成 Intermediate code 的時候可以進行優化。這種優化並不依賴於特定的平台,因此可以在不同的硬體平台上重用。
- Machine-dependent: 發生在 Compiler 的最後階段,也就是將 Intermediate code 轉化為 Target code 的時候進行優化,此時就要考慮不同的機器有不同的 CPU 架構與指令集, 此時就能利用平台的特性來幫助優化。
例如 1.2.4 展示的三位址碼,我們可以對其進行平台無關的優化,直接將 60 轉為 60.0 替代整數就可以消除 inttofloat 運算,並可以少去 t3 = id2 + t2 的運算,
把值直接傳給 id1,這樣就能得到一個更短的 Intermediate code。
t1 = id3 * 60.0
id1 = id2 + t1
Compiler Optimization 通常會另外開一門課特別講述,目前越來越強大的現代編譯器所做的程式碼最佳化已超出許多人預料。延伸閱讀: 你所不知道的 C 語言:編譯器和最佳化原理篇
1.2.6 Code generation
Code generator(代碼生成器)將會以 Intermediate code 作為輸入,並將其映射至 Target code,例如 Assembly language。
- Target code 若是 Assembly language,就必須為 Intermediate code 的變數分配 Memory address 或 Register
- A crucial aspect of code generation is the judicious assignment of registers to hold variables
例如 1.2.5 的優化過後的中間碼,這裡進行翻譯成組合語言
LDF R2, id3 // id3 的內容載入 R3 Regiester
MULF R2, R2, #60.0 // R2 與 60.0 進行乘法運算
LDF R1, id2 // id2 的內容載入 R2 Regiester
ADDF R1, R1, R2 // R1 與 R2 的值相加存到 R1
STF id1, R1 // R1 的內容存入 id1 中
這裡忽略了對於 Identifiers 儲存分配的問題,在後面會討論到
1.2.9 Compiler-construction tools
跟其他軟體開發一樣,開發 Compiler 也可以利用許多現代開發工具,除了通用的軟體開發工具之外也有一些更加針對 Compiler 的工具。
- Scanner generators: 可以根據一個語言的 Lexemes 的正規表達式(Regular Expression)描述來生成語彙分析器
- Lex, Flex
- Parser generators: 可以根據一個程式語言的語法(Context free grammars)描述自動生成語法分析器
- Yacc, Bison
- Syntax-directed translation engines: 用於 Traversal syntax tree 並使用 Attribute grammars 生成中間代碼
- Code-generator generators: 根據中間語言翻譯成目標機器的機器語言的規則(Tree grammars) 來生成代碼生成器
- Data-flow analysis engines: 可以幫助收集 Data-flow(程式中的資料傳遞),是 Compiler 優化的重要部分
- Compiler-construction toolkits: 可用於構造編譯器不同階段的工具
1.3 Formal Language Theory
Compilers: Principles, Techniques and Tools 書中 1.3 談論的是程式語言歷史,這裡改為討論語言的定義與自動機。
1.3.1 Language definition
在談論 Formal Language(形式語言)前首先要談的是 Alphabet, String, Language 的不同定義:
- Alphabet: a finite set of symbols.
- {0, 1}: binary alphabet
- String: a finite sequence of symbols from the alphabet.
- 1011: a string of length 4
- ε: the empty string
- Language: a set of strings on the alphabet.
- {00, 01, 10, 11}: the set of strings of length 2
- ∅: the empty set
對於 String 與 Language 有以下的基本運算:


1.3.2 Grammars & Metalanguage
- Grammars: The sentences in a language may be defined by a set of rules called a grammar.
- 例如有語法規則 G: the set of binary strings of length 2
- 那麼 L : {00, 01, 10, 11} 就是符合該語法規則的句子
- Metalanguage : a language used to define another language
如果透過一種語言來定義另一種語言,那麼該語言(Metalanguage) 必須是有明確的規則才能清楚作出清楚的定義,這樣才有可能實作下個階段的 Automata
1.3.3 Automata
我們能在 Compiler 中需要實作的就是 Automata,Automata 往往與 Formal language 密切關聯,自動機被用作可能是無限的形式語言的有限表示。 因此可以在實作上透過 Automata 使語言輸入並通過(Accept) 與 (Transform)轉換。
- Acceptor(接受器): 一種自動機,用 Grammar 確定輸入的字符串是否為該語言的句子
- Transducer(轉換器): 一種自動機,依照 Grammar 的定義來轉換輸入的字符串成為另一種語言。
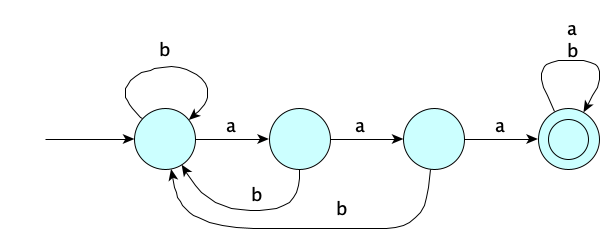
狀態機透過 State, Event, Output, Input 來達成如何精確地描述和處理可能無窮大的信息集合。
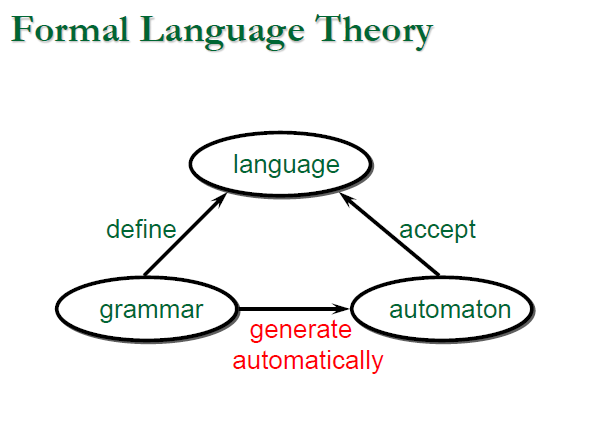
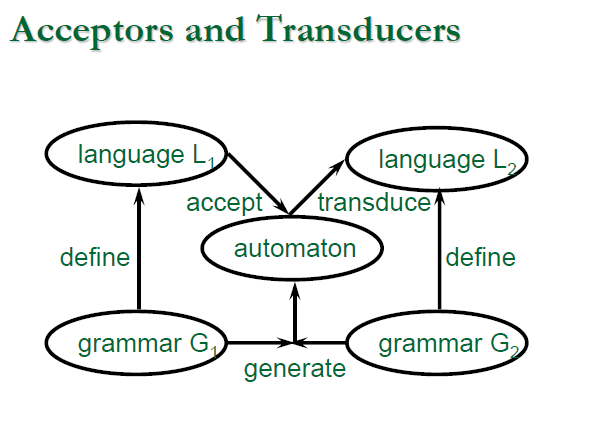
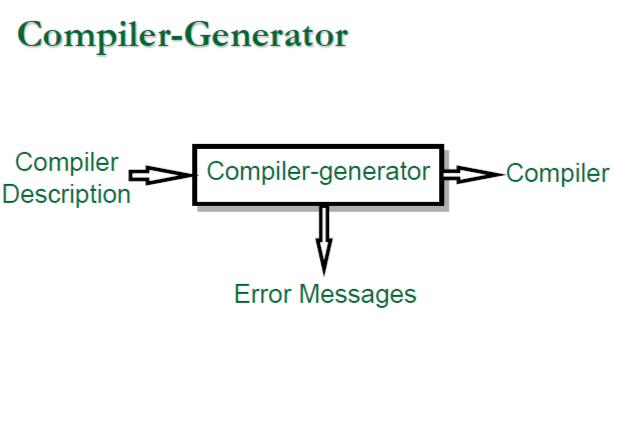
1.3.4 Compiler-Compiler
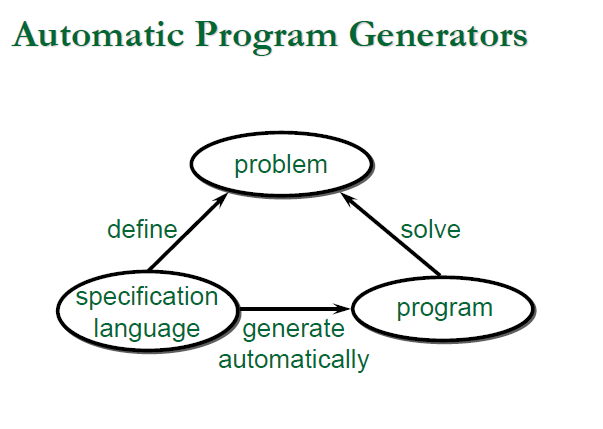
- 既然 Compiler 是透過 Grammars 來進行對一種語言的通過(Accept) 與 (Transform)轉換,這個 Grammars 必定是一種精確的規格(Specification), 這就讓我們可以透過 Specification 來撰寫 Automata,使我們可以透過 Grammars 來自動生成(Generate automatically) Automata
- 那麼定義 Grammars 的元語言(Metalanguage) 必然也是有精確的規則存在,那我們當然也可以透過 Matelanguage 來進行 Compiler 的自動生成,
這就是 Compiler-Compiler(編譯器的編譯器) 或 Compiler-Generator(編譯器生成器)
- 使用不同的 Matelanguage 來定義 Compiler 不同階段的元件,我們就能以此來自動生成這些元件
這是我們在各個階段可以使用的 Matelanguage,以及透過這些 Matelanguage 我們可以怎麼去實作 Automata
- Lexical syntax:
- Regular expression: finite automata, lexical analyzer
- Syntax:
- Context free grammars: pushdown automata, parser
- Semantics:
- Attribute grammars: attribute evaluators, type checker
- Intermediate code generation:
- Attribute grammars: intermediate code generator
- Code generation:
- Tree grammars: finite tree automata, code generator
NOTE
This is first note of compilers, focus on the introduction of compilers.
Last edit 09-23-2023 13:32