OS | Storage and File System
Operating System: Design and Implementation course notes from CCU, lecturer Shiwu-Lo.
參考資料: Jserv Linux 核心設計: 作業系統術語及概念, Linux 核心設計: 檔案系統概念及實作手法
Everything is a file. 是一個 Unix 設計哲學,但是這個設計並沒有完全實現在 UNIX 和後續的 BSD 上,直到 Plan 9 才算是真正的 Everything is a file, 使用了 9P 這個 Protocol,而 Linux 也採用了 9P 應用在虛擬化技術上。
如果從恐龍書來學習作業系統,那麼通常 File System 會被放在比較後面來學習,但是以 UNIX 的發展來看的話, File System 是從第零版的 UNIX 手冊就已經包含了檔案系統,而不見得已經包含了 Scheduler, 這也代表 File System 是作業系統中一個非常關鍵的部分。
- Block storage
- Hard drive Scheduling
- File system Overview
- File structure
- Directory structure
- Filesytem across hard drives
File System Overview
不管是 HDD 或是 SSD 都是 Block device,也就是資料的最小儲存單位是 block,對於 OS 來說硬碟就是一連串的 block。
- 再給定 Logical block address (LBA) 就可以讀取或寫入資料
- LBA 就是一連串的 block 並且有邏輯上的連續性
- CS 的先驅們設計了 File 和 Directory 這樣的概念,把 block device 變成邏輯上有意義的資料的集合
在 Linux 中為了讓不同的 File System 可以共存,所以設計了 VFS(Virtual File System) 這樣的機制,VFS 是一組檔案操作的抽象介面, 只要依循 VFS 開發的 File System 就可以在執行時期動態的掛載到 Linux 的 Kernel 上。

9.3.1 Directory and File
- 實際上 Directory 也是一個 File,在傳統的 UNIX 中 Directory 也是一個 File
- 其中記錄了其他 File 的名稱和對應的檔案編號
- 透過檔案編號就可以找到對應的 control block,control block 中記錄了檔案的 block 分布於硬碟上的位置
benson@101-debian:~$ tree -L 2 --inodes
[ 12] .
├── [ 16506] .bash_history
├── [ 2545] .cache
├── [ 3631] go
│ └── [ 3632] pkg
└── [ 1582] workspace
├── [ 1792] Hotshot824.github.io
└── [ 17040] jekyll-gitbook
5 directories, 0 files
這裡我們使用 tree -L 2 --inodes 來查看目前目錄下的檔案結構,會發現 Directory 也有對應的 inode,這代表 Directory 也是一個 File。
Block Size
- 大部分 Block device 所支援的 block 大部分是 4KB,跟 OS 的 page size 相同
- 這樣可以讓 OS 在管理記憶體與 Block device 的時候更有效率
9.3.2 Universal I/O Model
Linux 因為要秉持 UNIX 哲學 Everything is a file,因此不同種類的 I/O 都是透過 File Descriptor 來操作的,這樣就可以在這個一致的介面下操作。
- 我們可以使用 mount 來查看這些虛擬檔案系統
benson@debian:~$ mount sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) udev on /dev type devtmpfs (rw,nosuid,relatime,size=4042436k,nr_inodes=1010609,mode=755,inode64) devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000) ...
File Structure
這裡會介紹幾種常見的 File Structure,例如: Contiguous Allocation, Linked List, Indexed Allocation,但真正的重點是 i-node, 這是目前 Linux 使用的 File Structure。
9.4.1 Contiguous Allocation
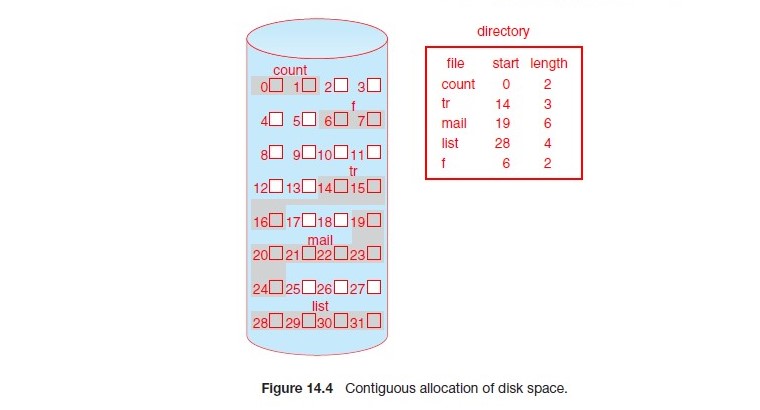
Contiguous Allocation(連續配置) 是一種最簡單的檔案配置方式:
- 基本構造是依照一個識別方式來找到檔案的起始位置,然後再依照檔案的大小來找到檔案的結束位置。
- 因為檔案是連續配置的,所以不管是循序存取或是隨機存取的效率都很高
- 例如: 存取 file1 的第 20 個 block 只要讀取起始位置加上 20 就可以了
- 但是檔案基本上無法繼續增長,適用於靜態的檔案系統,例如: CD-ROM, 磁帶機等等
- 再 Linux 上例如 root file system 每次開機都會掛載,並不會變化就可以使用 Contiguous allocation
Contiguous allocation 可以獲得比較高的效率,但是勢必會有 fragmentation 的問題
Extents
Extents 是取得連續配置與 fragmentation 中取得平衡的方案,file system 會盡可能的分配連續的空間給檔案,這樣的連續空間被稱為 Extents。
- 如果 file1 的空間不夠用,就會分配一個的 Extent 給 file1 延伸
- 後續的演算法都可以使用 Extents 來擴充,加入 Extents 的概念
Extents 可以視為分配空間的單位,但是保證這個單位空間是連續的
9.4.2 Linked List
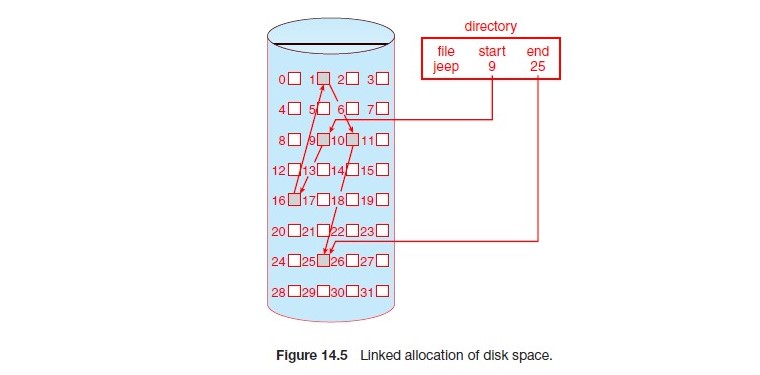
想要存取 jeep 就必須從 block 9 -> 16 -> 1 -> 10 -> 25 這樣去存取
Linked List 就跟字面上的意思一樣,每個 block 都會記錄下一個 block 的位置,這樣就可以連結起來, 因此在空間上可以不連續,但是在邏輯上是連續的。
- 在效能上不會太好,尤其是 Random Access 的效能,如: SSD, HDD
- 即使是 DRAM 也是 sequential access 的效能比較好
- SSD 的效能可能會降低至 1/2,而在 HDD 效能會下降的非常多
File Allocation Table(FAT)
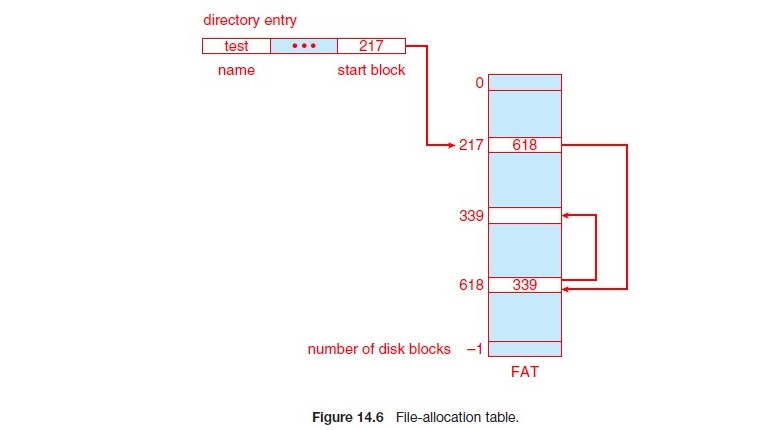
FAT 就是把 Linked List 的指標直接拿出來放在一個表格,這樣的好處是可以提前知道那些 block 是連續的,要讀取那些 block,這樣就可以提前 sequential access。
- 可以做部分的優化,sequential access 的效能比 random access 快很多
- 假如要讀取 jeep 就可以提前知道 jeep 的那些 block 是連續的,這樣就可以提前讀取
- 多餘被讀取的 block 就先丟進 DRAM,之後再丟棄就可以
- OS 可以提前讀進這些檔案的連結方式,也可以更快速的做 Random Access
- 如果 Main Memory 夠大還可以把 FAT 放在 Main Memory,這樣就可以更快速的存取
這裡要注意,FAT 所存放的是 block 的下一個 block 的位置,而不是直接指向該 block 的位置,因此跟 Index Allocation 有所不同
9.4.3 Indexed Allocation
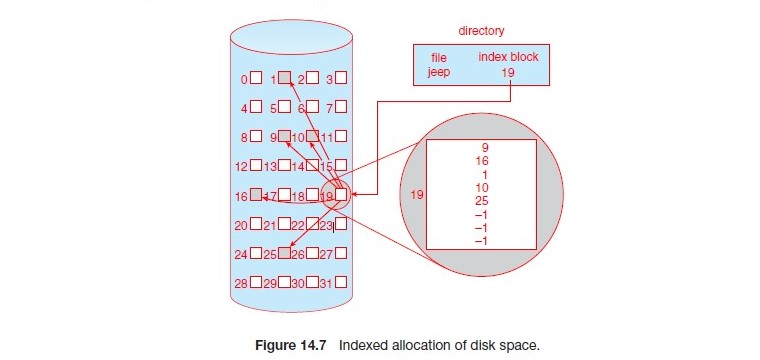
系統為每個檔案建立一個 index block,這個 index block 會記錄這個檔案的所有 block 的位置,這樣就可以直接存取這個 index block。
- 主要的問題是 index block 的大小,如果 index block 是 4K,那最多存儲 65536 個 data block,假如 data block 也是 4K 這個檔案系統最大為 256MB 的檔案
- 因此這裡可以向 MMU 一樣使用多層的 index block,這樣就可以存儲更大的檔案
缺點是假如我有一個很小的檔案如 4K,那麼這個檔案的 index block 會佔用很多的空間,假如有三層就要 12K 的 Index block 要維護
9.4.4 i-node
i-node 是 Unix 和 Unix-like OS 中所使用的一種資料結構,用一個資料結構來記錄一個檔案 metadata,包含了檔案的大小、擁有者、權限、時間戳等等
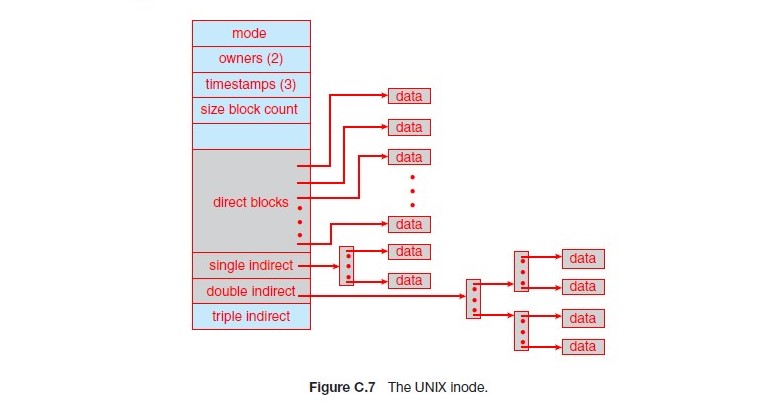
i-node 的這個設計在第一代的 UNIX(1960) 就已經使用,這個設計已經沿用了 60 年以上,很難想像一個檔案結構的觀念在這麼長的時間內都沒有被超越。
- 當然 i-node 有一些改善,例如控制權限從 owner, group, others 變成了 ACL(Access control list)
- 但是 i-node 的基本結構並沒有改變
i-node 的前 12 個 block 是直接指向 data block(Direct data block),所以不用再去使用第二層的 index-block,這樣如果檔案小於 48KB 就可以直接使用 i-node 來紀錄, 節省了 index-block 的空間。

- 一個 i-node 本身通常是 128 bytes,所以一個 block 可以存放 32 個 i-node
- 除了 Direct data block 之外還有 Single indirect block 和 Double indirect block
- Single indirect: 就是第二層的 index block 可以指向編號 12 ~ 267 的 block,也就是 256 個 block,
- Double indirect: 就是第三層的 index block 可以指向編號 268 ~ 65535 的 block,也就是 65536 個 block
- 因此一共可以定址 12 + 256 + 256^2 + 256^3 = 16843020 個 block,也就是 64.25GB 的檔案
- 在此之上還可以使用 Extents 來擴充,這樣就會讓 Data block 的大小變得更大
因此如果假設 data block 是 4KB,要存取某個 block:
- 當 File size < 48KB 就可以直接使用 i-node 兩次存取到 block
- < 1072KB 使用 Single indirect block,最多三次的 Access
- < 263216 使用 Double indirect block,最多四次的 Access
- < 64.25GB 最多五次的 Access
要注意這裡所提的都是最糟情況下,實際上已經存取過的 i-node 或 index 會被放在 DRAM 中,所以實際上的 Access 次數會比較少
9.4.5 Hole
Hole 是一個很重要的功能,如果一個檔案中並沒有實際的資料,那是否要真的要先分配空間給這個檔案,例如:
- VMWare 的虛擬機器通常可能設定了 100GB 的硬碟,但是實際上只有 10GB 的資料,剩下的資料還沒有寫入
- 如果沒有 Hole 的機制,就要把這 90GB 的空間都分配出來,全部以某種方式填滿
- 再有 Hole 的情況下這些空間都被視為 Logical 0,不占用實際的 Disk
關於 VMWare 的虛擬機器通常會提供 Provisioning Policies(佈建原則) 給使用者選擇
延伸閱讀: Linux 檔案的hole, Sparse file
9.4.6 Free Space Management
空的 block 也需要某種管理機制,讓 OS 能快速的找到空的 block 來分配給檔案,這裡有幾種常見的管理機制:
- Bit Vector 來管理空間,每個 block 用一個 bit 來表示是否被使用
- 這樣的好處是可以直接使用 Bitwise Operation 來操作,並快速的找到連續的空間
- 但是操作 Bit Vector 會有一些 overhead,例如: 把 Bit Vector 放在 DRAM 中才能快速的操作,並且 Time Complexity 是 O(n)
- Linked List 來管理空間,每個 block 會記錄下一個空的 block
- 使用 Linked List 來管理的好處是找到空的 block 就放入 Linked List 就好,OS 只要知道 Head 就可以找到所有的空間
- 缺點是比較難找到連續的空間
- 實際的例子是 ext2, ext3 都是使用 Linked List 來管理空間
btrfs
- 在 btrfs 中所有使用中的 block 都由 extent 來管理,因此 btrfs 中的檔案都是由 contiguous block 構成
- btrfs 會使用一顆 B-tree 來管理被使用的 block
- 這樣也代表沒被放入 B-tree 的 block 就是空的 block
- 例如兩個 node 分別記錄
250~440與800~1000,那麼441~799就是空的 block
Directory Structure
會對 Directory structure 的操作有兩種:
- 已經給定的 path name,找出相對應的檔案,例如:
vim /home/benson/example.txt就是在/home/benson下找出example.txt
- 列出 Directory 下所有的檔案
ls /home/benson就是列出/home/benson下所有的檔案
9.5.1 Unix Directory
- Directory 是一個特別的檔案
- 這個檔案紀錄了這個 Directory 下所有的的東西
- Directory 可以用 opendir(), readdir() 操作
- 主要包含這些:
name,type,i-node number
- 主要包含這些:
Directory Design Method
- Linear List
- 每一個目錄檔案可以視作是一個特殊的文字檔案,裡面紀錄
name,type,i-node number - 這種方式很適合列表功能,例如:
ls
- 每一個目錄檔案可以視作是一個特殊的文字檔案,裡面紀錄
- Data Structure for Fast Searching
- 可以使用檔案路徑名稱來快速的找到對應的 i-node,例如: hash, b-tree
- 這種方式很適合指定路徑名稱的功能,例如:
vim /home/benson/example.txt
- Mixed
- 這兩種方式可以混合使用,這樣就可以快速列表跟快速搜尋,例如: btrfs
Last Edit
3-6-2024 12:58