OS | Main Memory
Operating System: Design and Implementation course notes from CCU, lecturer Shiwu-Lo.
- Physical configuration of DRAM on PC
DRAM + BIOS + MMIO
- Three main functions of DRAM
- Segmentation memory management
- Paging memory management
- Linux memory layout
- External fragmentation
x86 Start - BIOS Address
在一台 PC 剛開機後唯一能讀取的記憶體就是 BIOS(ROM),必須透過 BIOS 才能完成後續 OS 的內容載入到 DRAM 中
- x86 在啟動的時候,執行的第一個指令是在
0xFFFFFFF0這個位址- 因此主機板上必須使用 Address decoder 將
0xFFFFFFF0對應到 BIOS 的 Entry point
- 因此主機板上必須使用 Address decoder 將
- BIOS 設定完畢後,會進入 OS 的 Entry point
- 例如: Linux 的
start_kernel
- 例如: Linux 的
BIOS in Memory Usage
BIOS 雖然不需要電力就能保存,但是通常速度會比 DRAM 慢,所以大部分的 BIOS 會把自己複製到 DRAM 中, 並且配置 data, stack, heap section,然後在 DRAM 中執行。
為什麼不使用 Flash memory,因為 Flash memory 是 Block device 而 CPU 能讀取的必須是 byte addressable
Memory Layout
下圖是如果記憶體只有 256MB 或 512MB 的 Memory Layout,在 32-bit 的 CPU 中,最多只能使用 4G 的定址空間
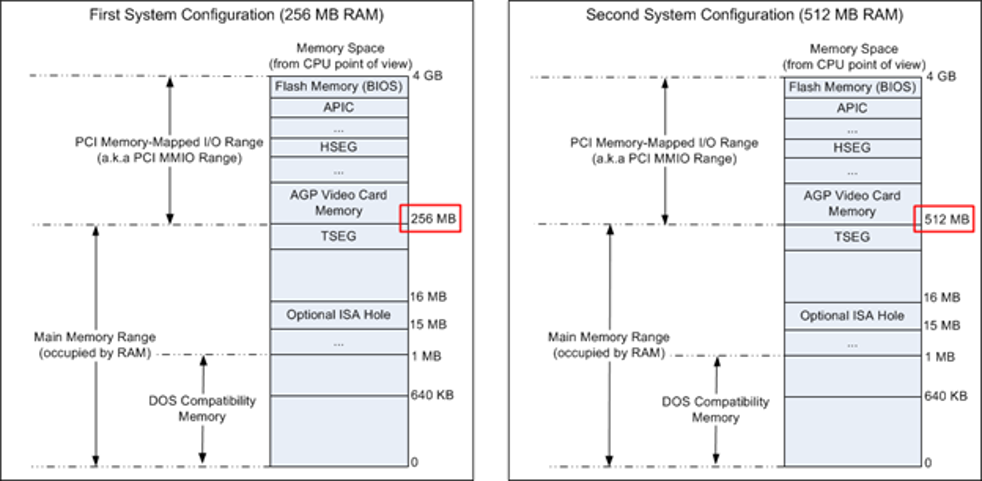
- DRAM 之外的空間就是 MMIO,這部分的空間通常只能透過 Kernel 存取
- 注意到他把 BIOS 映射到最上層的位置,這樣 BIOS 就不會去占用 DRAM 的定址空間
延伸閱讀: System address map initialization in x86/x64 architecture part 1: PCI-based systems
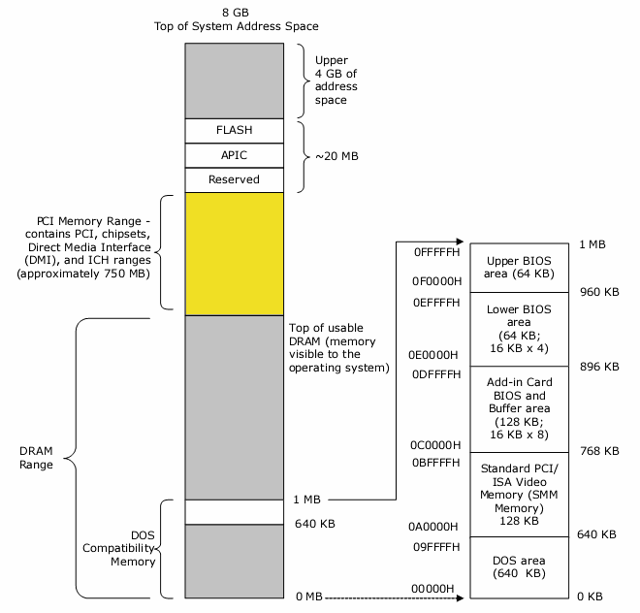
- 假如一個 4G 定址空間的機器裝上 4G 的 DRAM,那麼扣除 PCI 的空間後,只會剩下 3.25G 的空間可用
- 最好的解決方式就是邁入 64-bit 的時代,不只解決了 Memory address 的問題,也解決了檔案不能超過 2G 的問題
延伸閱讀: Why does my motherboard see only 3,25 GB out of 4 GB RAM installed in my PC?
7.1 BIOS - Memory Map
使用 dmesg 可以看到 Linux 在啟動時的 BIOS-e820 Physical Memory 配置,可以看到幾個區域
- usable: 可以使用的記憶體
- reserved: 保留給 BIOS 或是其他的 Device 使用
- ACPI data/NVS: 配置給 ACPI 或 NVS (Non-Volatile Storage)使用
[ 0.000000] BIOS-provided physical RAM map:
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009f7ff] usable # 0.62 MB
[ 0.000000] BIOS-e820: [mem 0x000000000009f800-0x000000000009ffff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000000ca000-0x00000000000cbfff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000000dc000-0x00000000000fffff] reserved
[ 0.000000] BIOS-e820: [mem 0x0000000000100000-0x00000000bfeeffff] usable # 3069.94 MB
[ 0.000000] BIOS-e820: [mem 0x00000000bfef0000-0x00000000bfefefff] ACPI data
[ 0.000000] BIOS-e820: [mem 0x00000000bfeff000-0x00000000bfefffff] ACPI NVS
[ 0.000000] BIOS-e820: [mem 0x00000000bff00000-0x00000000bfffffff] usable # 1 MB
[ 0.000000] BIOS-e820: [mem 0x00000000f0000000-0x00000000f7ffffff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000fec00000-0x00000000fec0ffff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000fee00000-0x00000000fee00fff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000fffe0000-0x00000000ffffffff] reserved
[ 0.000000] BIOS-e820: [mem 0x0000000100000000-0x000000023fffffff] usable # 5120 MB
實際分配給電腦的記憶體是 8192 MB,而經由 BIOS 分配以後為 8191 MB,可以發現這些 usable 的地址其實是不連續的, 有些地方映射到 DRAM,有些地方映射到 MMIO。CPU 會去透過 Address decoder 將 Physical address 映射到不同裝置的記憶體。
- DMA 與 DMA32 是保留給 16/32-bit 的 DMA controller 使用
- Normal 就是任何能夠使用 64-bit address 的裝置
- Movable zone 是用來處理 Hotplug 的記憶體,例如: USB Keyboard
- unavailable ranges 代表該區域的記憶體不可使用
- 可能因為 BIOS 或是其他的裝置使用了這些記憶體
[ 0.014535] Zone ranges:
[ 0.014536] DMA [mem 0x0000000000001000-0x0000000000ffffff]
[ 0.014539] DMA32 [mem 0x0000000001000000-0x00000000ffffffff]
[ 0.014541] Normal [mem 0x0000000100000000-0x000000023fffffff]
[ 0.014543] Device empty
[ 0.014545] Movable zone start for each node
[ 0.014548] Early memory node ranges
[ 0.014548] node 0: [mem 0x0000000000001000-0x000000000009efff]
[ 0.014550] node 0: [mem 0x0000000000100000-0x00000000bfeeffff]
[ 0.014553] node 0: [mem 0x00000000bff00000-0x00000000bfffffff]
[ 0.014554] node 0: [mem 0x0000000100000000-0x000000023fffffff]
[ 0.014558] Initmem setup node 0 [mem 0x0000000000001000-0x000000023fffffff]
[ 0.014577] On node 0, zone DMA: 1 pages in unavailable ranges
[ 0.014636] On node 0, zone DMA: 97 pages in unavailable ranges
[ 0.027855] On node 0, zone DMA32: 16 pages in unavailable ranges
...
[ 0.102320] Kernel/User page tables isolation: enabled
Kernel/User page tables isolation 是用來避免 SPECTRE 之類的攻擊,讓 Kernel 有自己的 Page table,缺點是會降低 System call 的效能
延伸閱讀: 实模式启动阶段:从bios获取内存信息
cat /proc/iomem 可以看到 Physical address 的配置
- 與之前的
dmesg顯示的內容相同 - 並且 kernel 會配置自己的 code, rodata, data, bss section
00001000-0009f7ff : System RAM # 0.62 MB
00100000-bfeeffff : System RAM # 3069.94 MB
bff00000-bfffffff : System RAM # 1 MB
100000000-23fffffff : System RAM # 5120 MB
8f400000-90201b41 : Kernel code
90400000-90cd5fff : Kernel rodata
90e00000-91046d3f : Kernel data
916fe000-927fffff : Kernel bss
DRAM Main Functions
7.2 Buffer/Cache
7.3 Program Layout
7.4 Memory Segmentation
7.5 Memory Paging
7.6 Fragmentation Problem
這裡先介紹 DRAM 的特性:
- DRAM 的特性是只要 CPU 開始工作,DRAM 就會全速運轉
- 即使 DRAM 有多個插槽,OS 會把他們視為一體
- DIMM (Dual In-line Memory Module)
- 通常插滿記憶體代表容量變大,頻寬變大,但 OS 無法獨立控制每個記憶體
- NUMA (Non-Uniform Memory Access)
- 有多個 CPU 的情況下,每個 CPU 都有自己的 DRAM,但是 CPU 之間可以透過 QPI 互相存取
- 這種情況下 OS 可以獨立控制每個 CPU 的 DRAM,例如: 雙路的 Server 的架構
- 記憶體無論如何都要耗電
- DRAM 不管是讀取或寫入或儲存都需要耗電,所以 OS 會把 DRAM 全部用完
- 如果某一個區段沒有真正的用途,那還是要耗電保存這部分 garbage
- 記憶體的主要用途
- 執行程式的時候使用
- 充當 Cache Memory 的角色,主要是當作 HDD, SSD 的 Cache
- 充當 Buffer 的角色,再與周邊 Device 溝通時,需要保留一塊 Memory 讓裝置可以存取,例如: DMA
7.2 Buffer/Cache
這裡使用 top 查看記憶體使用情況
- OS 會盡力把記憶體用完,例如: 拿來當作 Cache, Buffer 讓 I/O 更快
- 類似 memory cleaner 這樣的軟體,去釋放記憶體反而可能導致 I/O 變慢
MiB Mem : 7939.9 total, 7495.9 free, 357.6 used, 314.9 buff/cache
MiB Swap: 953.0 total, 953.0 free, 0.0 used. 7582.3 avail Mem
7.3 Program Layout
這裡說明 Program 在記憶體中的配置,以及他們的用途這部分就不多做介紹了,可以參考下圖。OS 在這裡的任務就是將執行檔從儲存裝置中載入到 Memory 中,配置好執行的環境。
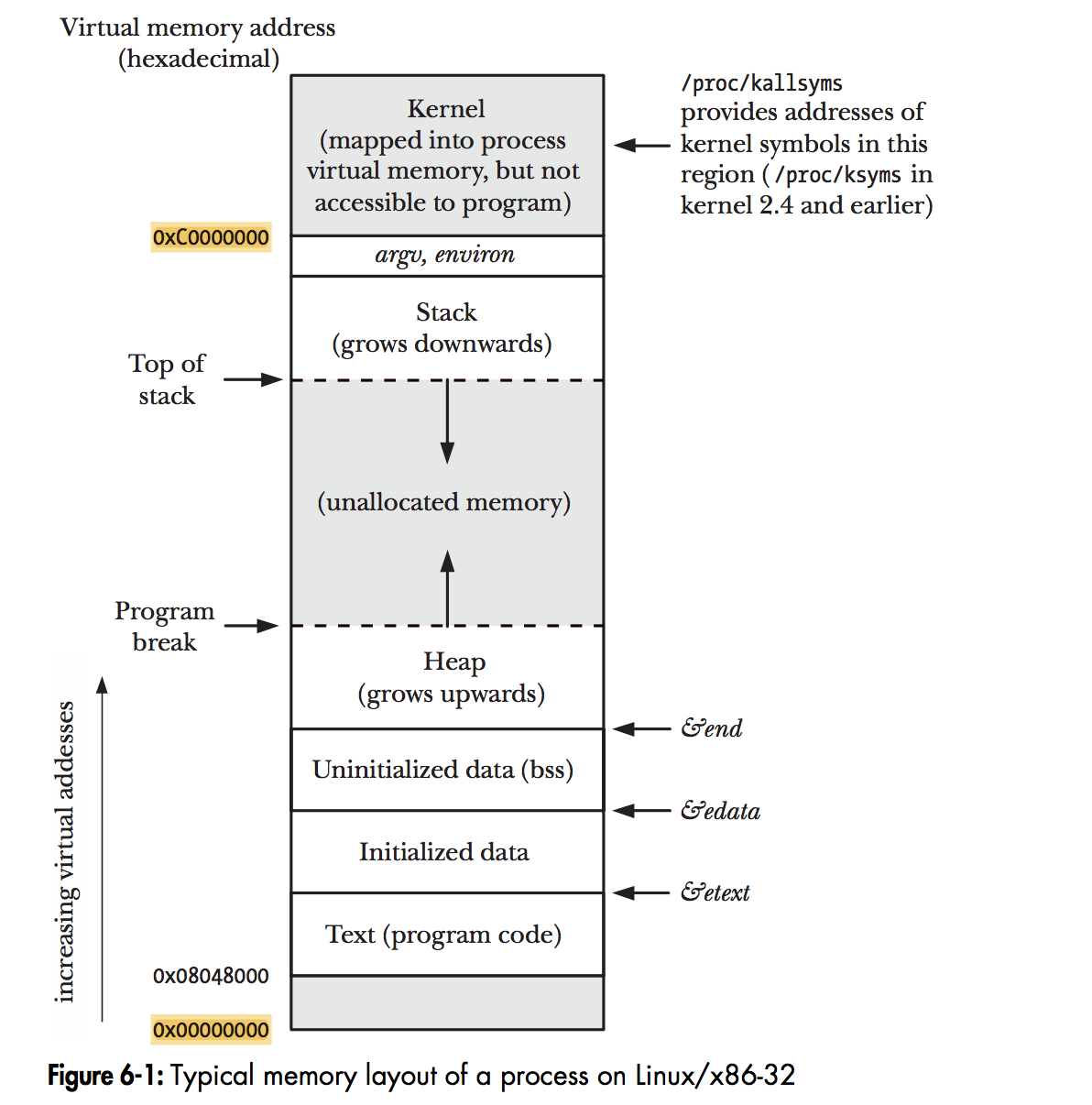
如果想觀察 Kernel 的 code, data, bss section 可以使用
cat /proc/kallsyms,但是需要 root 權限
7.4 Memory Segmentation
記憶體的區段機制(Memory Segmentation)是很直覺以程式的區段作為管理的單度,每個 seg. 都對應到程式的一個邏輯上的 seg.(text, data, bss, heap, stack), 通常 seg. 是不可以被拆分,要拆分的話需要硬體支援,有固定的拆分大小。
例如: x86 的 ds. fs. gs. 三個 data 的 segmentation,其中 fs. gs. 是額外的 data seg.
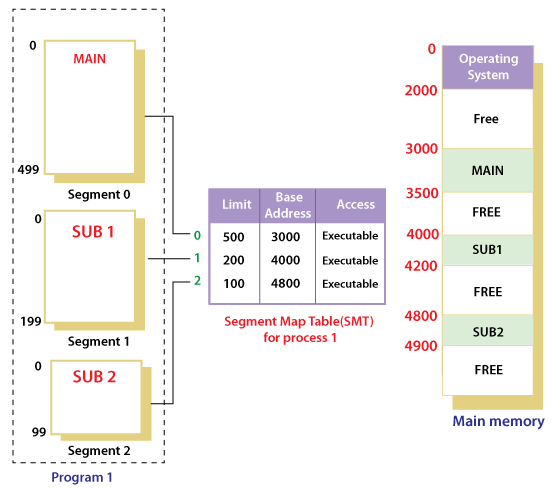
同一個程式的 seg. 可以在 Physical memory 中不連續,這樣可以更有效率的使用記憶體,但是這樣就有可能產生 Fragmentation Problem(碎片化問題)。
Management of Segmentation
既然是基於 Segmentation 的管理機制,那麼他所使用的定址方式就會是基於 Base + Offset 的方式(相對定址)。
- 例如這樣的指令: regtarget = regbase + offset
- 這個 regbase 是 OS 能夠管理的
- 例如設計三個 Register 可以分別指向 code, data, stack 的開始位置,這樣就能分開存放這三個 seg.
在這種機制下 Context switch 的時候除了切換 general register 以外,還需要切換 base reg. file
這種 base reg. file 的設計同時還要引入 limit(長度)用來限制存取的範圍,如果存取錯誤的記憶體就會觸發 Segmentation Fault。 以 ARM Cortex-M 為例,MPU_RBAR 是用來設定 base address,MPU_RASR 是用來設定 limit。
Memory Segmentation 的機制並不太適合在動態的環境下,要新增程式或減少程式,容易造成碎片化問題,但在靜態的環境下,例如: 嵌入式系統,就很適合使用這種機制
7.5 Memory Paging
Memory Paging 是目前主流的記憶體管理機制,相較於 Memory Segmentation,他的管理單位是 Page,而不是 Seg.
- Page 是固定大小的記憶體區塊,通常是 4KB
- OS 指定每個 Page 的用途,例如: code, data, stack, heap
- 不一定是連續分配的 Page
為了確保程式在執行時不會忽鄉干擾,OS 要能很輕鬆的切換正在執行的程式,所以硬體上會支援 Mapping Table 的機制
- 假如系統最多有 48 個 Page,那麼這個 Table 就起碼要有 48 個 entry
- 要能針對每個 Page 設定不同的權限,例如: stack(rw-), code(r–), data(rw-)
- 即使 stack, data 是相同權限,但是 OS 會給他們不同的功能,例如: stack 可以隨程式增加大小
下圖是一個程式從 CPU 使用 Virtual address 到 Physical address 的過程,其中 OS 會透過 Mapping Table 來做轉換, 實際上這樣的轉換是在 CPU 中完成的,是已經設計好的硬體線路
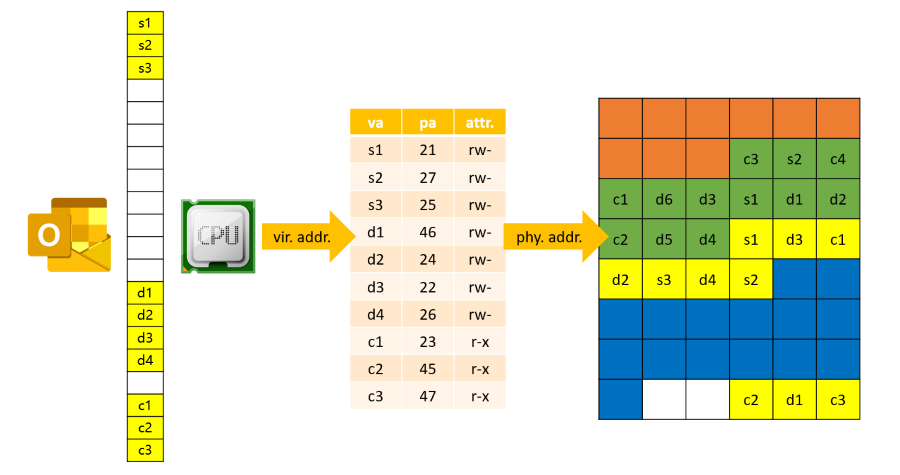
可以看到表格中會有 Vir. address, Phy. address 的對應,與屬性權限等等,如果 Context switch 的時候,OS 只需要切換這個 Page Table 就可以了。
- 同時 OS 會知道這個 Page 是什麼類型,例如: stack 假如碰觸到邊界,OS 就會去增加 stack 的大小。
- 在虛擬記憶體上,OS 會把這些資訊記錄在 Task Control Block(TCB) 中,使用 RBtree 來管理
Linux Kernel 中使用 mm_struct 來描述 Task 的 Virtual Memory Layout
- 相較於 Segmentation,Paging 的優點是:
- 在記憶體分配上 Paging 比較有彈性,只要有足夠的 Page 就可以
- 在 Hardware 上並沒有 Segmentation 的概念,是由 OS 來實現的
- 每一個 Page 的大小是固定的,分配演算法會比較好實現
- 缺點:
- Page 的數量遠超過 Segmentation,所以 Page Table 會很大,可能會造成硬體 Mapping 上的效能負擔
- 如果使用 Assembly 寫程式,Paging 的程式碼會比較難寫,難懂
7.6 Fragmentation Problem
只要會造成 Memory 動態分配的情況,就必然會有 Fragmentation Problem,這是一個無法避免的問題
- External Fragmentation: 如果一塊記憶體中的 Free space 足夠,但無法滿足程式的需求,這些 Free space 就是 External Fragmentation
- Internal Fragmentation: 因為配置演算法,本來只需要 X size 的記憶體,但是分配了 X + Y size 的記憶體,其中 Y size 就是 Internal Fragmentation
- 例如: OS 分配空間時覺得剩下的空間太小了,乾脆把整個空間都分配給程式,那就是 Internal Fragmentation
這裡有一些解決 External Fragmentation 的方法,例如:
- Memory Compaction(記憶體壓縮): 搬移記憶體使 Free space 變成連續的,但是成本很高
- 更好的分配演算法: Best Fit, Worst Fit, First Fit
Fragmentation in Paging/Segmentation
- 在 Pagging 的情況下,由於每個 Page 的大小一致,並且透過 Mapping 的方式使用 Page,所以不會有 External Fragmentation
- 但因為程式所需要的記憶體大小不會剛好是 Page 的大小,所以會有 Internal Fragmentation
Memory Paging Hardware
7.7 MMU and MPU
7.8 TLB
7.9 TLB Miss
7.10 Translation table structure
7.11 Hardware Handling of TLB Miss
7.12 Software Handling of TLB Miss
這裡會介紹 Mapping Table 的基本形式,即是 TLB(Translation Lookaside Buffer),如果 TLB 不夠大要怎麼處理
7.7 MMU and MPU
- MPU(Memory protection unit): 可以設定某段記憶體的權限,例如: code(r–), data(rw-)
- MMU(Memory management unit): 除了 MPU 的功能以外,還可以透過 MMU 使 OS 更有效的分配記憶體的使用
MMU management unit
- 以 Segment 為最小管理單位
- 較早期的電腦會以 Segment 為最小管理單位
- 在 Protect 上會比較直觀
- 因為 Segment 的特性,所以對於記憶體管理的幫助不大
- 以 Page 為最小管理單位
- 在 Protect 上會比較複雜,因為每個程式都會有很多 Page
- 但在管理上因為 Page 固定大小,因此可以更有效率的管理記憶體
- 因為 Page 很多,所以需要很多的 Mapping entries,例如: 4GB 的記憶體就要 1M 個 entries(4GB / 4KB),這會成為硬體的負擔
MMU Architecture
實際上 MMU 會建立在 CPU 內部,下面是一個簡單的架構表示 CPU 中 MMU, Address decoder, DRAM 之間的關係:
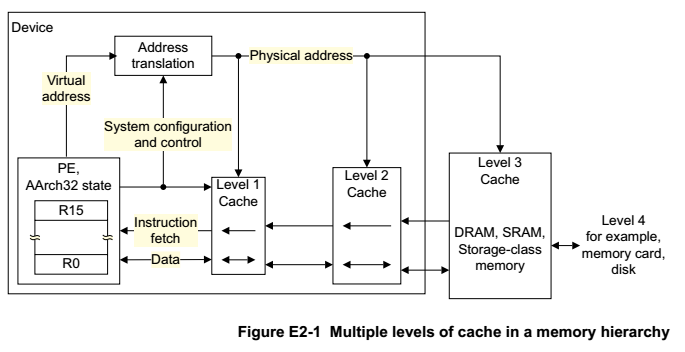
- L1 Cache 與 MMU 誰在前誰在後,取決於 CPU 的設計
- 要注意的是 L1 Cache 如果在 MMU 前面 Context switch 的時候,就要把 L1 Cache 清空
MMU Function
這裡介紹下 MMU 應該會是什麼樣子,這下面舉的是抽象簡化的例子
假如有以下編碼 regtarget = regbase + offset
- Segment 機制下:
- regbase 可能是 basecode 這樣的管理方式,代表是 code seg. + offset
- Paging 機制下:
- regbase 代表的是 Page Number,所以是 Page Number + offset
- 例如: 一個 32 bit 的系統,Page number 會是 20 bit,offset 會是 12 bit,因此 offset 最多只能是 4KB,因此不需要 limit 的設計
7.8 TLB
其實 TLB(Translation Lookaside Buffer) 就是一個在 CPU 中的高速 Buffer(SRAM),把 MMU 的 Page Table 存放在 TLB 中,利用這種方式可以加速地址轉換的速度。
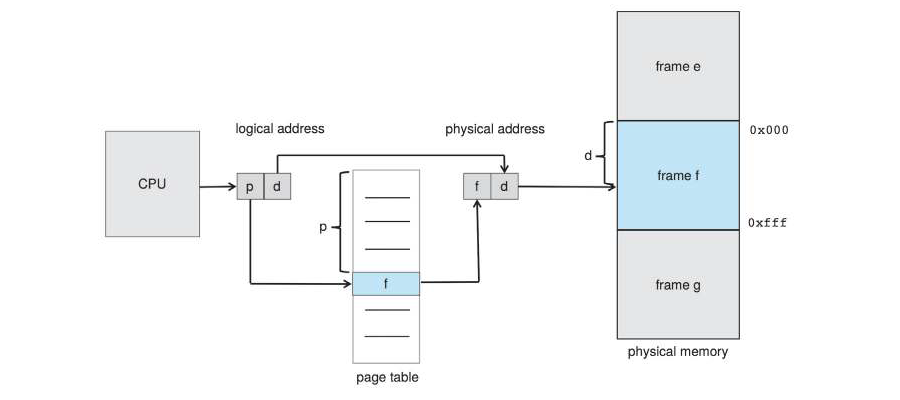
- p(page number): 程式在 Logical address 中的 Page number
- f(frame number): 實際在 Physical address 中的 Page number
- d(displacement, offset): 在 Page 中的 offset
這裡來看一個實際的例子 Intel Sandy Bridge 的 TLB 規格:
- Level 1 TLB
- i-TLB: 72 entries, i means instruction
- d-TLB: 100 entries, d means data
- Level 2 TLB (如果在 L1 TLB 中沒有找到,就會到 L2 TLB 中查找)
- 1024 entries
TLB Size
那麼一個 Page 的大小是 4KB,4KB * 1024 = 4MB,但是一個程式不可能只有 4MB 大小,這裡再看另一個例子,MIPS R8000-style TLB,一共有 384 entries, 這樣也才 384 * 4KB = 1536KB,都是遠遠小於實際程式需求的。
解決方法:
- Hardware: 增加 TLB 的數量,但是這樣會增加硬體成本(CPU 變大,成本變高,搜尋時間變長)
- Dynamic: 增加動態載入 TLB 的方式
要動態載入 TLB 就要思考這是怎樣的資料結構,同時要硬體支援
7.9 TLB Miss
TLB 有大小的限制,因此會發生 TLB Miss,當 Miss 發生時就會需要動態載入 TLB
增加 TLB 的大小:
- TLB 基本上是一個平行搜尋的硬體
- Page number 會同時與 TLB 中的數百到數千個 entries 做比對
- 擴充 TLB 會增加硬體成本,例如: 電晶體數量,時脈降低,耗電量增加
既然這樣的話增加 Page size 也是一種方法,但是就會降低軟體在管理上的彈性,例如: huge page
Dynamic Loading TLB entries
當 MMU 發現某一個 Page number 在 TLB 找不到對應的 entries 時,觸發 TLB Miss 將當下要使用的 TLB 載入, Main Memory 足夠放入所有的 TLB entries,但是這部分應該要由 Hardware 來實現還是 Software 來實現?
7.10 Translation table structure
這裡介紹如何把 TLB 的 entries 放到 Main Memory 中,使用什麼樣的 Data structure 來管理
假如我們要把 TLB 的 entries 放到 Main Memory 中,那假設以下情況:
- 500MB 的程式,需要 500KB 的記憶體空間放 Page Table
- 700MB 的程式,需要 700KB 的記憶體空間放 Page Table
- 1500MB 的程式,需要 1500KB 的記憶體空間放 Page Table
以上這些程式一樣會動態載入記憶體,這樣的話久而久之也會造成 External Fragmentation,這樣就反其道而行了,Paging 本來是用來解決 Fragmentation 問題的, 但是為了這些大小不一的 Page Table,反而造成了 Fragmentation 問題。
Hierarchical Paging
這裡就使用一種 Hierarchical Paging(階層式分頁)的方式來解決這個問題,一個 4KB 大小的 Page 可以管理 1024 entries,第二層也是以 4KB 還分層管理, 這樣兩層就能放入 1024 * 1024 = 1M 個 entries,這樣就能解決上面的問題。
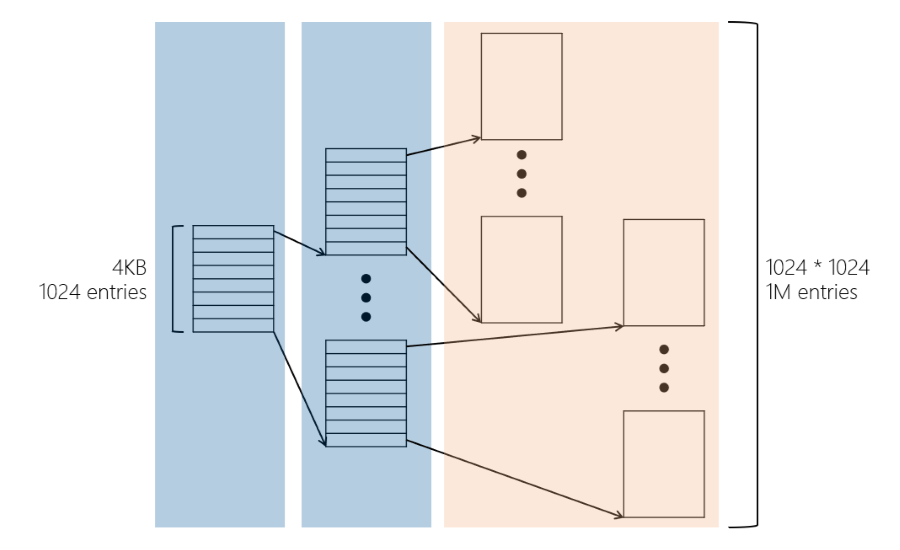
這樣的話定址的格式就會改成以下的格式:
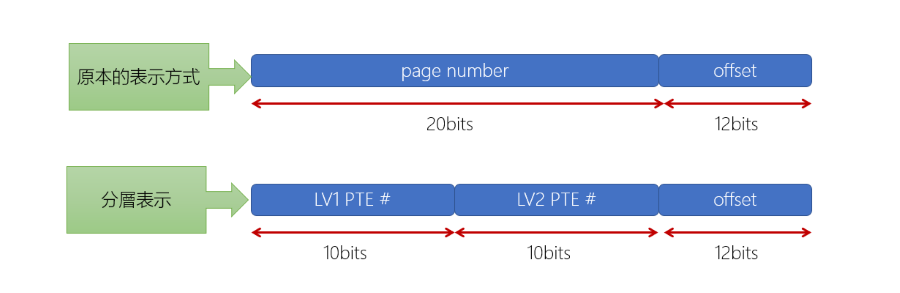
- LV1 PTE(Level 1 Page Table Entry): 第一層的 Page Table Index
- LV2 PTE(Level 2 Page Table Entry): 第二層的 Page Table Index
- d(displacement, offset): 在 Page 中的 offset
注意到這樣的指令格式剛好是 210 x 210 x 212 = 232,也就是 32-bit 的 CPU 可以使用這樣的指令格式。
在這裡 LV1, LV2 在沒有映射出去的時候,會設定為 Invalid bit
延伸閱讀: Andrew S. Tanenbaum, Modern Operating Systems, Chapter 3, 3.3.2 Page Tables 有更多種類的 Page Table 結構可以參, Marvin Solomon CS 537
7.11 Hardware Handling of TLB Miss
目前大部分的 CPU 都是用硬體來處理 TLB Miss,硬體會透過之前提過的 Hierarchical Paging 的指令方式來查找 Page Table,
在 Logical address 中會以逗號隔開的方式記錄: 0xpte1, 0xpte2, 0xoffset
下圖是一個簡單的架構表示如何處理 TLB Miss:
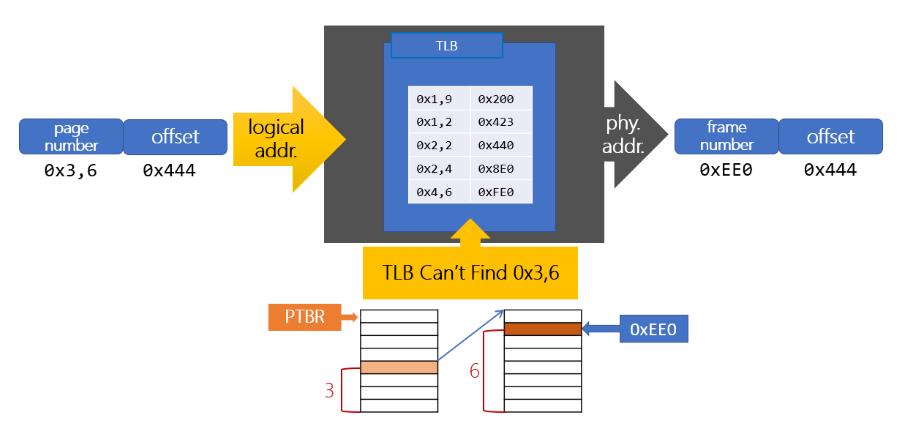
- 首先 CPU 會先去 TLB Search,TLB 中沒有的話就會觸發 TLB Miss
- PTBR 會記錄 LV1 Page Table 的 Physical address,以供 CPU 找到 LV1 Page Table
- PTBR(Page Table Base Register): 在 Intel x86 中是 CR3
- 找到第二層的 LV2 Page Table,然後在 LV2 Page Table 中找到對應的 Frame number
- 將一個 TLB Entry 置換成剛剛找到的 Frame number
- 重新啟動 TLB Search,這次就會找到對應的 TLB Entry
7.12 Software Handling of TLB Miss
MIPS 處理器使用了 software-managed TLB,這種方式會比較慢,當 TLB miss 時將會觸發 exception,然後 OS Kernel 會去進行後續處理。
這裡列出三類型的 TLB exception:
- TLB Refill: TLB 中沒有相對應的 entry 時就會發生
- TLB Invalid: Virtual address 使用被設定為 Invalid 的 entry 時就會發生
- TLB Modified: TLB 有對應的 entry,但是該 entry 的權限不符合(No dirty bit)時就會發生
MIPS 會告知 OS TLB Miss 的原因與位置,並根據 CPU 正在執行哪一個 task 來使用適當的演算法找出對應的 entry
要注意軟體處理 TLB Miss 有兩種可能:
- Real Error: 也就是程式碼出錯,例如: 存取了不該存取的記憶體
- TLB Miss: 也就是程式碼沒有出錯,只是 TLB 中沒有對應的 entry
OS Kernel 在這裡可以像硬體一樣去使用 Paged Page Table(分頁分頁表),或使用 Hash Table 來管理 TLB entries。 並且在軟體上會清楚正在執行哪些 Task,所以可以提前把共用的 TLB entries 載入到 TLB 中,這樣就可以減少 TLB Miss 的發生。
- Advantages:
- 透過軟體的話,可以更有效的搜尋,甚至修改搜尋演算法
- 可以提前載入共用的 TLB entries,減少 TLB Miss 的發生
- Disadvantages:
- 要去執行 Exception 會牽涉到 Mode change,會有額外的成本
部分 MIPS 也有硬體機制來走訪 Page Table,部分 SPARC、POWER 處理器允許軟體來處理 TLB Miss
填寫 TLB 的功能必須由 Kernel 來做,由 User space 來做的話會有安全性的問題
Fragmentation
7.13 OS memory allocation architecture
7.14 Kernel Management of Frames
7.15 Slab Allocation
7.16 Malloc
Linux Kernel 幾乎不會修改與 Kernel space 相關的 Page Table,因此 Kernel 會盡可能地去使用大的 Page,例如: 1GB, 來降低對於 TLB entries 的使用,因為在 User space 中 Kernel 的部分是共用的,修改 Kernel 的 Page Table 可能會造成額外的 TLB Miss。
User space 的部分就會使用 4KB 的 Page,這裡要討論的是 malloc 怎麼分配記憶體給 Task 使用,malloc 不會每次都剛好等於 4KB 的倍數, 硬體上可以解決的是 4KB Page 為單位的 Fragmentation 問題,但是程式自由配置的大小問題還是需要由軟體來解決。
7.13 OS memory allocation architecture
下圖展示一個作業系統的記憶體分配架構,怎麼初始化到分配記憶體給 Task 使用
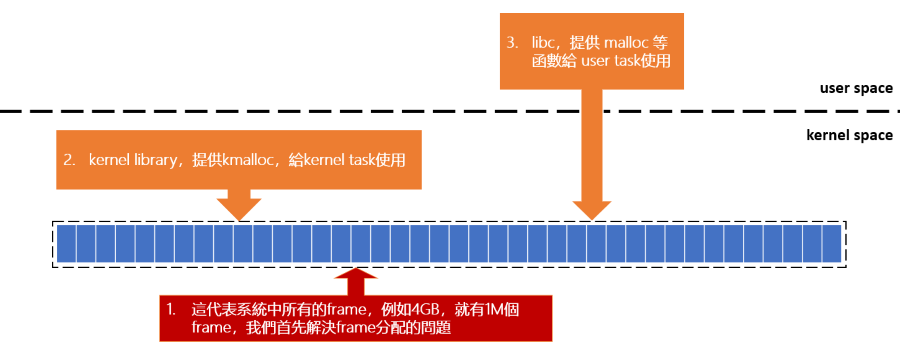
在這個架構之下這裡要討論的是:
- Kernel 如何管理分配 Frame
- Kernel lib 會提供
kmalloc()來提供給 Kernel 的 Task 使用 libc如何實現malloc()來提供給 User space 的 Task 使用- 這裡雖然記憶體最小的管理單位是 4KB,但是 libc 透過 syscall 來向 Kernel 一次要求多個 page
- 例如: sbrk(), brk(), mmap()
- 而 malloc() 會在這些 page 中分配記憶體給 Task 使用,以此做到更細微的記憶體分配
- 這裡雖然記憶體最小的管理單位是 4KB,但是 libc 透過 syscall 來向 Kernel 一次要求多個 page
7.14 Kernel Management of Frames
Kernel 透過 MMU 的機制,可以把記憶體都視為 4KB 大小的 Page(Frame) 來管理
- Kernel 將所有的 DRAM 都 Mapping 到 Kernel space
- 這代表 Kernel 可以直接存取所有的 DRAM,即使已經分配給 User Task 使用
- 因為記憶體幾乎是完全交由 Kernel 來管理,所以 Kernel 內部必須小心地處理記憶體
- 因此開機系統啟動時會去探測記憶體大小和狀況,這裡會使用 bootmem
- bitmap 只會在最初使用,因為在怎麼優化效率都不高
延伸閱讀: Linux 核心設計: 記憶體管理
Buddy system
buddy system 的目的是更快的搜尋到可以分配的記憶體,並且盡量保持記憶體的連續性
假設在分配時,kernel 已經知道有一塊 2M 的連續記憶體可以分配,並且 task 也可以用掉這 2M 的記憶體就可以直接分配這 2M 給 task 使用, 同時保持記憶體的連續性,可以使 MMU 做更有效率的優化。
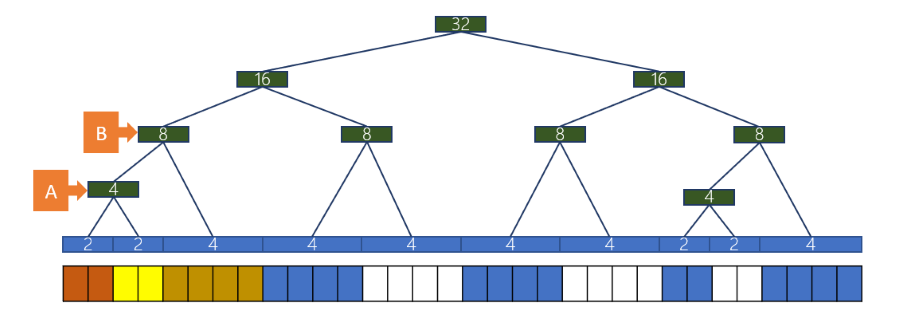
在上面這個例子中,我們假設 kernel 已經知道有 32 個 frame 可以分配,藍色的部分代表已經被使用的 frame:
- 合併的條件是來自相同的 parent
- 橘色與黃色的 frame 來自同一個 parent A,所以可以合併
- 黃色的 parent 是 A,棕色的 parent 是 B,所以不能合併
- 只有橘色與黃色合併後,parent 變為 B,才能與棕色合併
- 如果某 Kernel task 需要 2 個 page,那麼就優先把 2 個 page 的 leaf 分配給他
- 同理如果需要 4 個 page,就優先把 4 個 page 的 leaf 分配給他
在 Linux kernel 中實現 buddy system 的方式是透過 bitmap 來實現樹,而不是真的使用一個樹的資料結構
7.15 Slab Allocation
Linux kernel 中有許多頻繁使用的資料結構,例如: task_struct, file, inode 等等,如果直接使用 buddy system 來分配記憶體, 會很容易造成 Fragmentation,所以使用 slab 來解決這個問題
雖然 buddy system 可以每次以 page(4KB) 為單位分配記憶體了,但是系統執行時絕大部分的資料結構都是小的,因此 Linux 使用 slab 來解決小物件的分配。
- slab 會去向 buddy system 要數個 page,在這裡會被稱為 cache(kmem_cache, 並不是指 CPU cache)
- slab 描述 kmem_cache 的定義在
mm/slab.h cat /proc/slabinfo可以看到目前系統中有哪些 cache
- slab 描述 kmem_cache 的定義在
- slab allocator 是由很多個不同大小的 cache 組成,這些 cache 通常是為了分配特定 object 的大小
- 例如: 在 Linux kernel 中 task_struct 大約只需要 1.7KB 就可以使用一個 cache 來服務這個 object
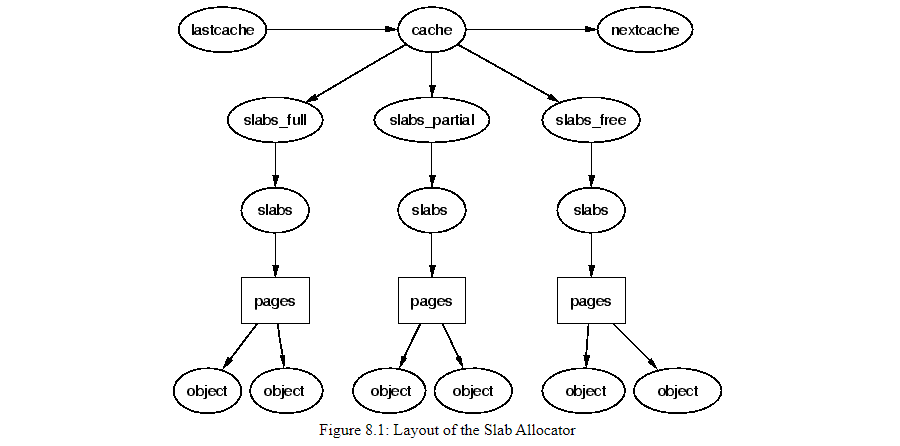
- cache 中使用三種 list 來管理: full, partial, free
因此 slab 會達到以下的目的:
- 可以比 buddy system 分配更小的記憶體
- cache 常用的 object 可以被重複使用,不需要重新分配記憶體(allocating, initialising, destroying)
- 把這些常用 object 與 L1 或 L2 cache 對齊,可以更好的利用 hardware cache
這裡可以想像 slab 就是把常用的 object 當成牛奶瓶,cache 就是牛奶箱,牛奶瓶可以重複去牛奶箱中拿取放回。
7.16 Malloc
通常程式都會有 heap,而 malloc 幾乎都是從 heap 中分配閒置的記憶體給程式使用。
- heap 是連續配置的記憶體空間,大小為 page 的倍數
- malloc 這裡會使用一些演算法來從 heap 分配記憶體給程式使用
- 例如: ptmalloc
延伸閱讀: Glibc 内存管理, Overview of Malloc
malloc 實現這邊打算之後另外寫一篇文章,這邊只要知道 task 使用 malloc 也不是直接向 kernel 索要 page 就可以了
Last Edit
1-26-2024 19:15