OS | Virtual Memory
Operating System: Design and Implementation course notes from CCU, lecturer Shiwu-Lo.
本章節會主要介紹 Virtual Memory 這是這章節的討論範圍
- Virtual Memory Hardware and Software
- Virtual Memory Example
- Page Replacement
- Working Set
- open, read, writ vs. mmap
- Differences between these system calls
- TLB miss
MMU Main Function
- MMU 主要處理記憶體分配的問題
- 消除了 External fragmentation(外部碎片)
- 由於 Page size 僅有 4KB,所以 Internal fragmentation(內部碎片)很輕微
- 如果 TLB miss
- 假設該 TLB 要去 Mapping 的 Page 在 Memory 中只要將 Virtual memory to Physical memory 的 Mapping 加入 TLB 即可
- 上述的動作可以使用 Hardware 來完成,或使用 Software 來完成
- 如果 TLB miss 並且 Hardware 的表格也查不到呢
- 稱之為 Page fault
What is Virtual Memory
8.1 Define the Virtual Memory
嚴格的定義: 由軟體重新定義 Page fault
- 當 CPU 所要存取的 Memory 根本不存在於 DRAM 中時,就稱作為 Page fault
- 如果我們啟動 Software 此時該 Software 所要存取的 Memory 根本不存在於 DRAM 中,就稱作為 Page fault,例如 Segmentation fault
- OS 設計者重新詮釋了 Page fault 的意義,例如:
- OS 暫時還沒把該 Page 載入到 DRAM 中,重新載入就好
- 例如: Execl 假如有 500MB 的資料要放入 DRAM 中以供執行,但硬碟的讀取速度有他的極限例如 20MB/s,不可能每次執行 Execl 都要花 25 秒鐘去讀取資料
- 先把必要的程式碼放入 DRAM 就好,等使用者真的需要使用其他功能時再去載入該功能
- OS 讓不同的 Process 隱形共用內容相同的 Page
- 唯讀,不會有任何問題發生,還可以減少記憶體使用量,例如: fork() 使用 Copy-on-write 的技術來實作
- 寫入,OS 必須確保每個 Process 在邏輯上都有自己的 Page,例如: 即使 fork() 使用同一份 Memory,但是要確保程式的 Logic address 上是不同的
- OS 暫時還沒把該 Page 載入到 DRAM 中,重新載入就好
稍微寬鬆一點的定義: 讓 Mapping 變得更加靈活
- 透過設定 MMU,使 Memory Mapping 更加靈活的例子
- Shard Memory,讓不同的 Process 可以共用同一份 Memory
- 可以將檔案 Mapping 到 Process 的 Memory Space,讓 Process 可以直接存取檔案
- 可以將部分 I/O 的記憶體 Mapping 到 Process 的 Memory Space,讓 Process 可以直接控制 I/O
- Linux 中使用 mmap 存取
/dev/mem
- Linux 中使用 mmap 存取
8.2 Virtual Memory Components
下圖是 Virtual Memory 中會需要的組件
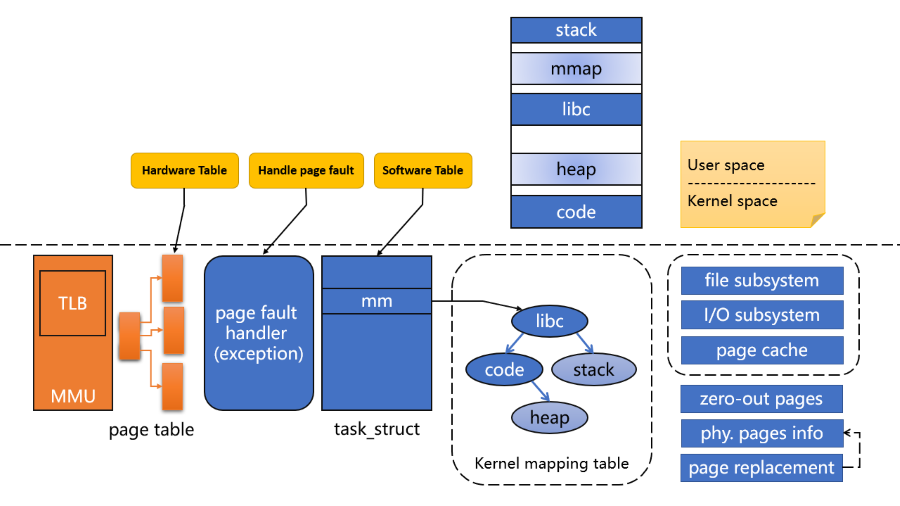
- Hardware table(Page table)
- 這部分由 OS 來寫入硬體所設計的表格,由 MMU 來讀取,例如: x86 定義表格,Linux 依照 x86 的定義來實作
- 每個 Process 都有自己的 Page table
- 如果 TLB miss 硬體查詢 Page table 還是找不到,此時觸發 Page fault exception
- Software table(mm_struct, kerne mapping table)
- 每個 Process 甚至 Linux Kernel 都需要一個查詢表,快速的查詢每個 Memory 是否正確
- 如果正確還發生 Page fault 如何處理?
- 處理 Page fault
- OS 必須有 Page fault handler(Interrupt service routine)
- 並且要能紀錄: 錯誤的原因,錯誤的 Address
Virtual Memory Example
8.3 Shard Memory
8.4 Demand Paging
8.5 Linux Pure Demand Paging
8.6 Performance of Demand Paging
8.7 Copy-on-Write
8.8 Kernel same-page merging
8.9 Page Table Entry Attributes
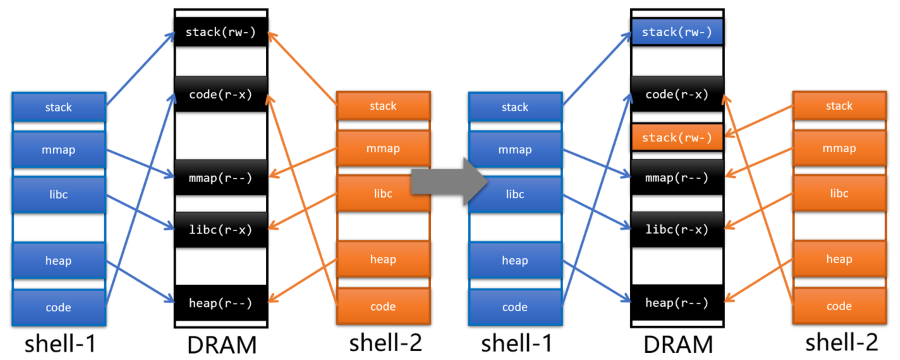
8.3 Shard Memory
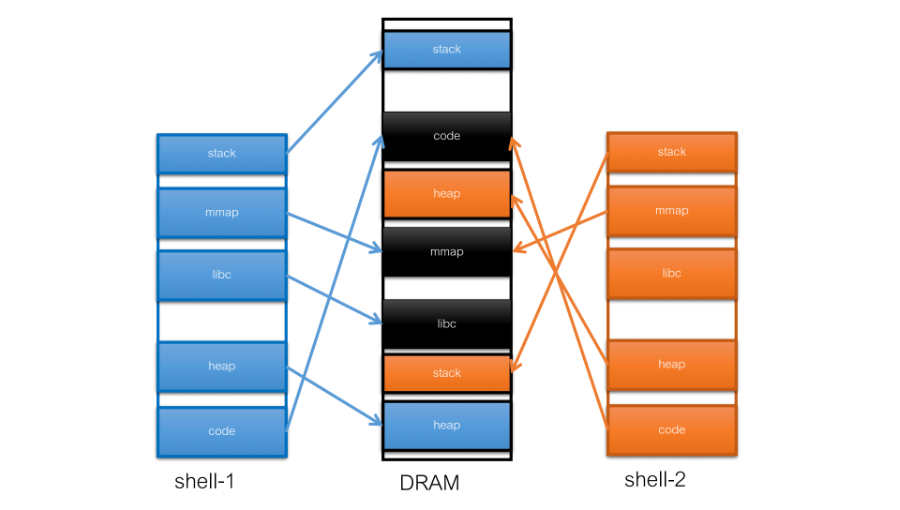
- stack, heap 這部分是程式自己獨有的
- 黑色的部分是共享的:
- code, libc: 這兩個是同一個程式但是開了兩個 Process
- 因為在執行時會去 Mapping 硬碟上的執行檔,這樣 OS 就能知道其實這兩個 Process 完全是一樣的
- 並且這部分只能 Read,這樣就沒有 Locked 所造成的效能瓶頸
- mmap: 這部分不是由 Kernel 去分享的,當 Shell 去呼叫 mmap syscall,後得到一個符號這樣就可以將該記憶體映射至自己的 Memory
- shell-1 將資料傳給 shell-2 要傳的是資料在 mmap 中的 offset
- 盡量不要去指定 mmap 要被映射的 Address
- code, libc: 這兩個是同一個程式但是開了兩個 Process
- Virtual Memory 允許 Code, Data 共享
- 多個程式使用相同的 Library,例如: libc
- 應用程式透過 Shared memory 共享資料,例如: mmap
- Parent 和 Child 都沒呼叫 execv 的話,記憶體內容幾乎一樣,例如: Copy-on-Write
- Linux 允許隱含式的共享
- Linux kernel 可能會掃描 Memory,將內容一樣的 Page 隱含共享
- 例如: 電腦的桌布跟登入畫面使用同一張圖片,記憶體內容是一樣的
8.4 Demand Paging
Define of Demand paging
- 作業系統不會立刻將使用者所需要的 Memory 配置給 User
- 發生 Page fault 時,才會載入該段記憶體的資料
Demand paging advantage
因為只需要載入需要的資料
- Less I/O needed
- Less memory needed
- Faster response
- 啟動時間,只需要載入需要的資料就能啟動了
- More users/programs
- 因為每個程式需要的記憶體較少,因此可以載入更多的應用程式
Demand paging shortcoming
- 對於 Disk system,Demand paging 雖然減少了讀取的量,但是會引發大量的 Random access
- 例如: 執行兩個程式,這兩個程式一共 100 MB,OS 可以驅動 Disk 使用兩秒鐘的時間來載入這兩個應用程式。
- 如果使用 Pure demand paging,假設兩個程式輪流執行,一共需要 20 MB 5120 個 pages,並且執行的程式碼「隨機散布」, 目前 Disk 的 IOPS 約為 200,則載入兩個程式的時間變為 25.6 Sec
- 除了引發大量的 Random access 以外,Demand paging 也可能會造成執行期間有些 Lag
- 例如: 不希望玩遊戲時會有延遲,就要一次把遊戲所要用的資料全部載入
Random access 對 SSD 的速度大約是 Sequential access 的 1/2 ~ 1/3,HDD 則有可能從 200MB 降低到 1MB
IOPS: Input/Output Operations Per Second(每秒輸入/輸出次數)
Linux 在這方面的處理方式是假如要 1個 Page,就會一次載入周遭 8 個 Page,因為通常同一個程式會連續使用到相同的 Page,這樣就能減少 Random access 的問題。
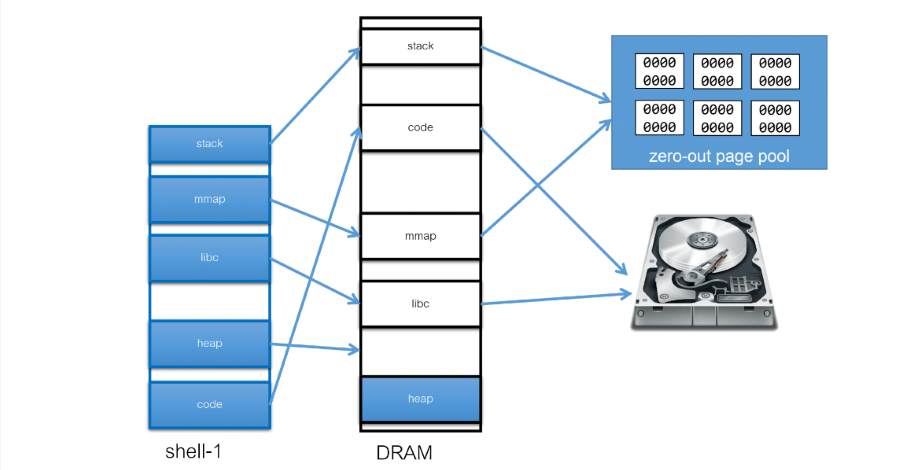
上面張圖表示了一個程式配置到 DRAM 的情況
- OS 會透過 process 的 kernel mapping table 來看要去哪裡找資料
- code, libc: disk
- stack, mmap, heap: zero-out page pool
- zero-out page pool: OS 會維護一個 pool 在這裡面都是已經預先初始化(0)的 page,用來分配給 stack, mmap 使用
- 這是為了避免資訊,例如: 上個程式的資料還留在 DRAM 中,下個程式可以從 DRAM 讀取到上個程式的資料
Valid-invalid
下圖是一個 x86 的 Page table entry,後面的 12 個 bit 就是 attribute
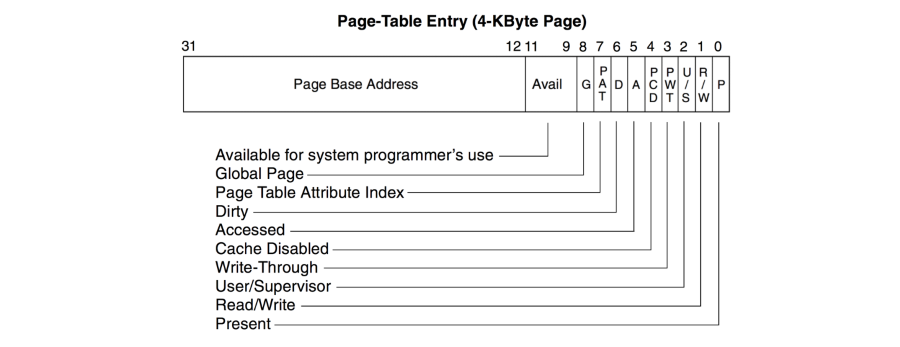
- Present: 0 的話表示該 Page 不在 DRAM 中,此時可能代表 OS 還沒有將該 page 載入 DRAM 中,或者該 page 本來就不在 DRAM 中(程式寫錯)
- 不管是在 page table 中的第一層或第二層,只要有一個是 0(invalid),就會觸發 exception
- 此時 OS 會去查詢 process 的軟體表格(Linux mm_struct)
- 查詢成功: 配置 physical page 給該 address,然後修改 page table 重新執行
- 查詢失敗: 程式發生錯誤,例如: pointer 指向錯誤的 address,此時繼續錯誤處理(終止或呼叫 GDB)
大部分的 valid-invalid bit 都在 PTE 的最右邊,這是 CPU 設計時如果指向不存在的 page,在此時前變得 bit 都可以任意使用, Linux 就使用這些 bit 來協助解決 backing storage 為 swap space 的 page fult
8.5 Linux Pure Demand Paging
Pure demand paging 的意思是在執行新的程式時,並不會分配任何 page 給 task,直到該 task 索取
以 Linux 為例子,使用 execve() 將執行檔放入當前 process 的 memory space
- 先在該 task 的 mm_struct 中設定 section 映射的資訊
- code, data 對應到執行檔案
- bss section 對應到 zero-out page pool
- lib 對應到相對的 library
- 只分配少量的 stack space(8KB) 給該 task
- 執行程式
Linux 並沒有分配任何 page 先給該 task,因此是 pure demand paging
8.6 Performance of Demand Paging
怎麼估算 Demand Paging 的效能,如下:
- Page fault rate: 0 <= p <= 1
- 估算一個 Page fault 發生的機率
- Effective Access Time(EAT)
$EAT = (1 - p) * memory\,access + p(page\,fault\,overhead + swap\,page\,out + swap\,page\,in + restart\,overhead)$
- swap page out: Free space 不夠就需要將某些 page 從 DRAM 寫入 disk
- 優化方式: 無論如何都保持一定的 free space
- swap page in: 當 page fault 發生時,需要將某些 page 從 disk 讀入 DRAM
- 常用的 page 就先放入 page cache 中,例如:
ls
- 常用的 page 就先放入 page cache 中,例如:
- page fault overhead, restart overhead: 這兩個 overhead 通常是硬體相關的問題,或 ISR 的部分 assembly 寫的夠不夠好
- swap page out: Free space 不夠就需要將某些 page 從 DRAM 寫入 disk
OS 上主要能優化的就是 swap page out/in 這兩種方式
Example
- Memory access time: 200 nanoseconds
- Average page-fault service time: 8 milliseconds
- EAT = (1 - p) * 200 + p(8,000,000)
= 200 + p * 7,999,800
- EAT = (1 - p) * 200 + p(8,000,000)
- 如果每 1000 次 memory access 有 1 次 page fault,那麼速度將變為原本的 1/40
以上的例子是說明,在可能的情況下盡量少用 swap space,這樣可能會造成 CPU 大量的時間都在 idle
8.7 Copy-on-Write
在 Physical memory 中也會使用 Copy-on-Write 的技術,例如: 在剛 fork() 出來的 child process,如果 child process 沒有修改任何資料, 就不會真的複製一份 parent process 的資料,而是共用同一份資料,這樣就能減少記憶體的使用量。
- 通常 fork 之後的 parent 與 child
- 在 register 之外都是一樣的,因此直接 copy parent 的 mm_struct 給 child
- 將 parent 與 child 的 page table 都設定為 read-only
- 在 read-only 之後如果其中一個 task 去作出修改,就會觸發 page fault
- Linux 把造成 page fault 的 page 改成 writeable,並且複製一份 page 給 child
- 這樣 parent 與 child 就重新各自擁有一份可 write 的 page
這樣的技術也可以用在 File System 上,例如: Linux 的 Btrfs
8.8 Kernel same-page merging
- Kernel virtual memory(KVM) 中會有許多不同的 VM 都會用到相同的 page
- 例如: 都是執行 Win10,那麼這些 VM 中的 OS Kernel 應該都是一樣的
- 在一般的 OS 也可能會有相同的 Page
- 例如: 桌面與登入畫面使用相同的圖片,這樣就會有相同的 Page
- 上面的情況都比較難有真正的事件發生,因此需要 OS 去主動掃描才能發現共用記憶體,節省記憶體的使用量
8.9 Page Table Entry Attributes
在 Main Memory 中介紹的是 PTE 的前 20 個 bit,這邊會更詳細的說明後 12 個 bit 的意義
- Present: 是否在 DRAM 中
- Read/Write: 0 表示 read-only,1 表示 read/write
- User/Supervisor: 表示是否需要 kernel mode 權限才能存取
- Write-through: 決定 page 使用的是 write-back 或 write-through
- Cache Disable: 如果是 1 則禁止該 page 被 cache
- Accessed: 表示該 page 是否被存取過
- Dirty: 表示該 page 是否被修改過
- Page Table Attribute Index: 跟 Write-through/Cache Disable 有關,可以設置更細緻的 Cache 設定
- Global: 表示該 page 是否是 global page,例如: 共享的 library
- Available: 這 3 個 bit 可以讓 OS 自由使用
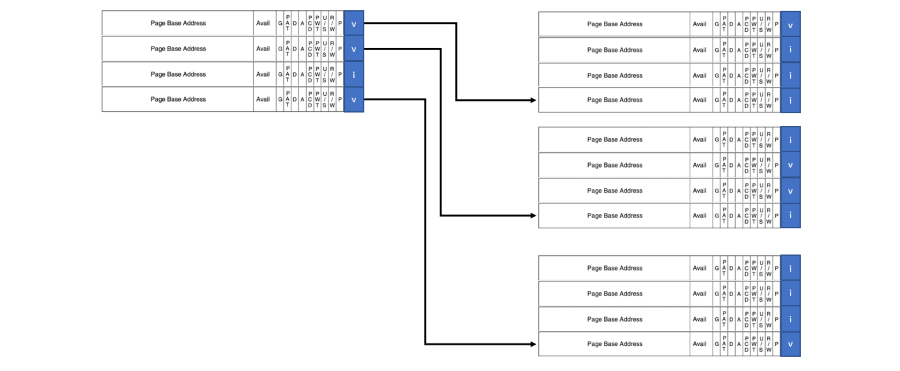
而一個 4KB 的 Page table 可以放入 1024 個 PTE,然後在 Main memory 提過的 Hierarchical pading 在這裡可以更詳細的說明, 這樣的話架構就會如下(以 4 個 PTE 組成一層 Page table 為例):
這樣我們就能把 Page table, TLB, Virtual memory, Physical memory 組合起來,如下:
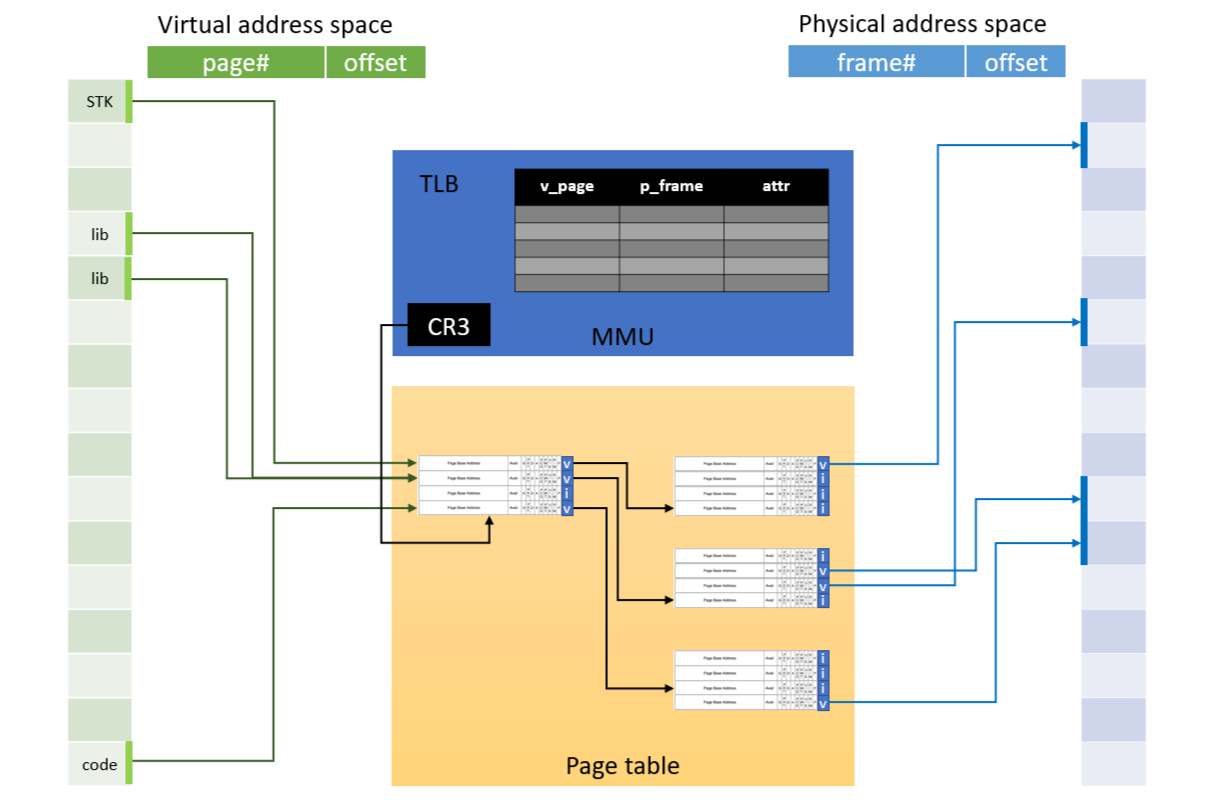
- Virtual address 透過 TLB 轉換成 Physical address
- TLB 紀錄 virtual address 與 physical address 的 mapping
- attribute 也會紀錄在 TLB 中
- TLB miss 會觸發 page fault,透過 CR3 register 找到 page table
- Page table 紀錄 virtual address 與 physical address 的 mapping
- page table 找到 physical address 後去更新 TLB,然後重新查詢
- 如果 PTE 是 invalid,就會觸發 page fault,再去載入該 page 到 DRAM 中
到這裡為止就是完整的 Virtual memory 到 Physical memory 的運作方式
Page Replacement
在這之前所討論的都是在 DRAM 足夠滿足程式大小的情況,但是實際上 DRAM 並不一定能滿足程式所需要的大小
8.10 Why Need Page Replacement
8.11 Page Replacement Concept
8.12 Page Replacement Algorithm
8.13 Algorithm Evaluation Example
8.14 Linux’s Page Replacement
8.10 Why Need Page Replacement
主要的原因就是 DRAM 有限,例如: 使用者同時執行了 Excel, Word, Chrome,這三個程式的大小加起來超過了 DRAM 的大小, 或者是使用者正在看一部影片,但是這部影片的大小超過了 DRAM 的大小。
例如一個 6.2GB 的影片,使用者只有 6GB 的 DRAM,就先把 200MB 的資料寫入 swap space,需要時再從 swap space 讀取
- 因為 Virtual memory 的存在,所以 OS 可以只載入目前所需要的資料
- 隨著程式的執行,過去所需要的資料會不斷累積,但不代表這些資料可以被丟棄
- 因此當 DRAM 不足時,OS 要考慮是否把這些資料寫出到 secondary storage 或丟棄
例如: 一個 word 的程式用來初始化 word,但是接下來不會再使用,這時就可以把這些資料丟棄
8.11 Page Replacement Concept
在 memory 中我們怎麼找出最近不會使用到的 page,這就是 page replacement algorithm 的目的
- 這個 algorithm 設計的好可以讓使用者感覺不到 page replacement 的存在
- 當然也有可能設計的不好,造成使用者感覺到 lag
- 在不考慮 page-out/page-in overhead 的情況下,user 可以使用的 memory 遠超 DRAM 的大小
- 假設 user 執行的應用程式共需要 12GB 的記憶體,但 user 只有 4GB 的 DRAM
- 依照未來會存取的順序來對 12GB 的記憶體做排序,就可以知道哪些 page 優先被放入 DRAM
- 為什麼只要仔入部分資料就可以
- 例如: 10秒鐘內,user 能存取的資料不會超過 4GB(locality)
- 如果超過 4GB,那麼就把部分資料 page-out,然後 page-in 需要的資料
實際在 Linux 執行中可以使用 free -h 去查看使用的 Men, Swap,Linux 並不會真的把 Men 使用光,而是會保留一部分的 Men 做為 page cache, available 則是在不使用 swap 的情況下可以分配多少記憶體
那麼在 512MB 的電腦上執行 6.3 GB 的程式,會發生什麼
- 理論上系統的所有被使用的記憶體大小不能超過 DRAM + Swap
- OS kernel 本身是 non-swappable
- 所以 OS 本身所需要的記憶體都會直接配置在 DRAM 中,這裡並不是 kernel 不能被設計成 swappable,而是這樣的設計不合理
- OS 會在必要時 kill 掉一些 task,稱為 OOM killer(out-of-memory killer)
8.12 Page Replacement Algorithm
這裡要討論的就是那些 page 應該被丟棄,這就需要 page replacement algorithm 來決定
- Algorithm 的目標: 最小化 page fault 的數量
- 這裡要看優化的目標是什麼,在這裡討論的是最小化 page fault 的數量
- 在這裡會討論以下幾種 algorithm
- FIFO: First-in-first-out
- Optimal algorithm
- 概念上的最佳化,必需假設知道未來的 Page access pattern
- LRU: Least-recently-used
- 過去不曾用到的 page,未來也不太可能會用到
- 實現時會增加硬體上的成本,因為要加入一個時間戳記
- Second-chance
- 有效且低成本的方式來實現接近 LRU 的效果
- LFU: Least-frequently-used
- 過去最不常用的 page,未來也不太可能會用到
- MFU: Most-frequently-used
- 過去最常用的 page,可能代表已經使用結束了,所以之後不會用到
- Linux’s page replacement
Basic assessment method
在等等評估演算法的方式中,會使用以下的方式來評估:
- 在給定的 Reference string 中,計算 page fault 的數量
- Reference string:
- 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
- 這個 reference string 代表了一個程式的 page access pattern
- 在這裡假設系統只有 3 個 frame
8.13 Algorithm Evaluation Example
FIFO
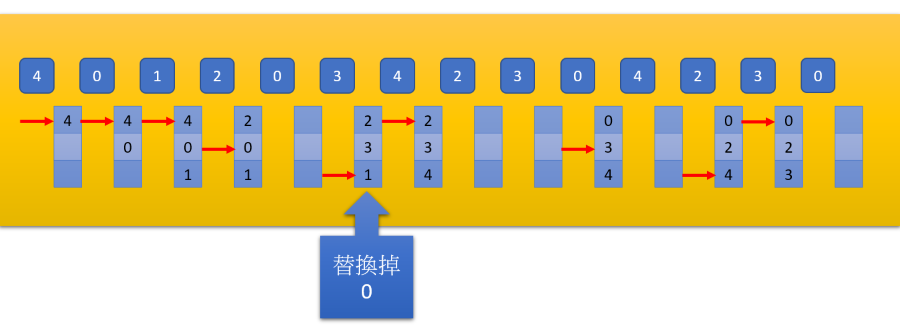
- 替換掉最早進入的 page
- 所以當 4, 0, 1, 2 時,將 4 Swap out
Optimal algorithm
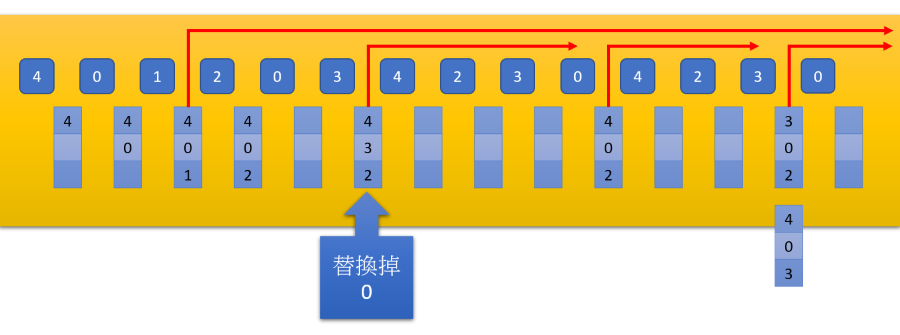
- 提早替換掉未來最久不會使用到的 page
- 所以當 4, 0, 1, 2 時,發現未來不會使用到 1,因此將 1 Swap out
- 接下來到 0, 3 時發現 0 還有三次 Access 才會使用,最久因此將 0 Swap out
- 實際上這樣的演算法是不可能的,因為我們不可能知道未來的 Access pattern
LRU
我們無法得知未來的 Access pattern,但是可以知道過去的 Access pattern
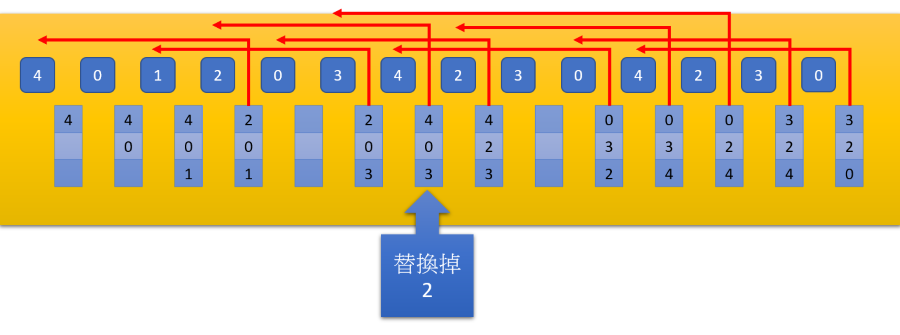
- 替換掉最久沒有使用的 page
- 所以當 4, 0, 1, 2 時,將 4 Swap out
- 接下來到 0, 3 時發現 1 是最後使用的,因此將 1 Swap out
Second-chance(clock algorithm)
LRU 如果要在硬體上實現,需要一個時間戳記,但是這樣會增加硬體的成本,因此有了 Second-chance
Second-chance 可以用 PTE 中的
- Accessed bit(也稱為 Reference bit)來實現,當 page 被存取時,OS 會將 Accessed bit 設為 1,OS 會定期去清除 Accessed bit 改為 0。
- Dirty bit 則是在 page 被修改時,OS 會將 Dirty bit 設為 1,如果把 Dirty bit 為 1 的 page-out,就代表必須要跟 disk 做同步,因此會增加 page-out 的時間。
- 如果以上兩個 bit 都是 0,就代表這個 page 是可以被 page-out 並且成本低的
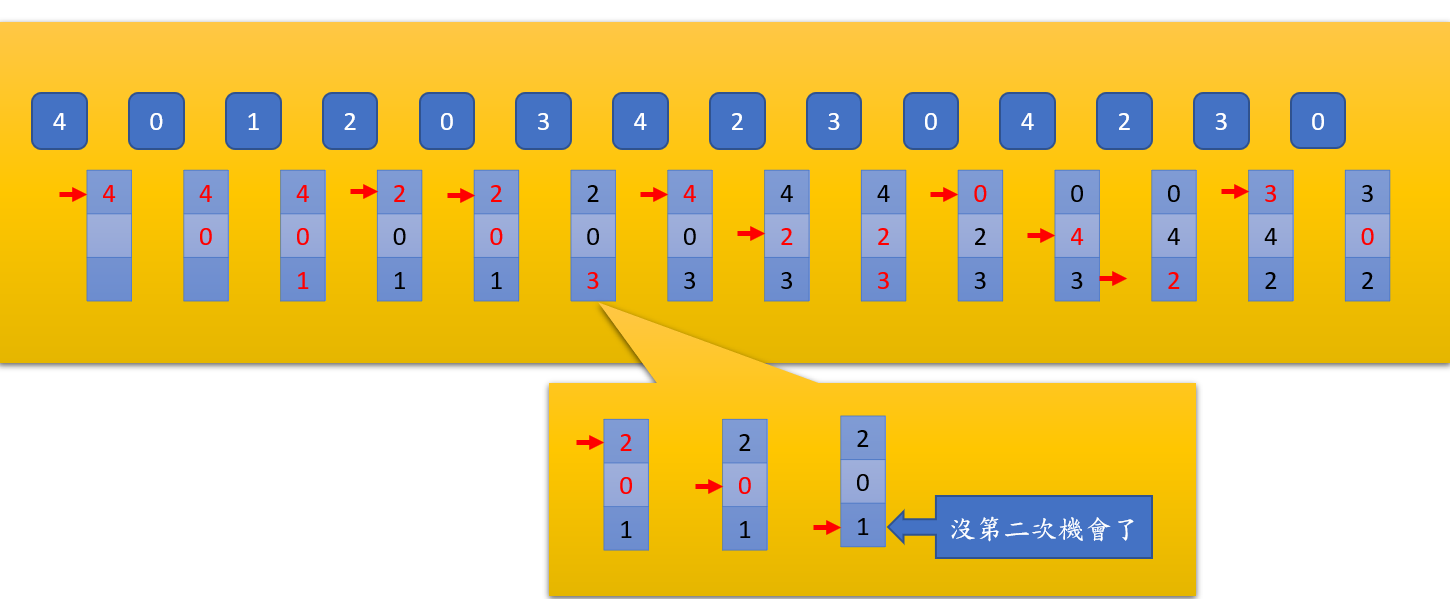
- 實際上剛載入的 memory 的 page accessed bit 都是 0,因此會先被替換掉
- 這樣假設 A 剛載入一個 page p, 此時 B ctx 他有可能會把 A 的 page p 替換掉,這樣回到 A 又要重新載入 p
- 解決方式是在一些 OS 上會有 young bit,或者是在載入時就將 accessed bit 設為 1
- 紅色的字體就是剛 Access 的 page,在實作上可以有很多方式
- 這裡使用一個 Pointer 依序指向 page,當 page 被指向第二次時並且 accessed bit 為 0,這個可以 page-out
Second-chance 有很多種實作方式,這裡只是其中一種
LFU
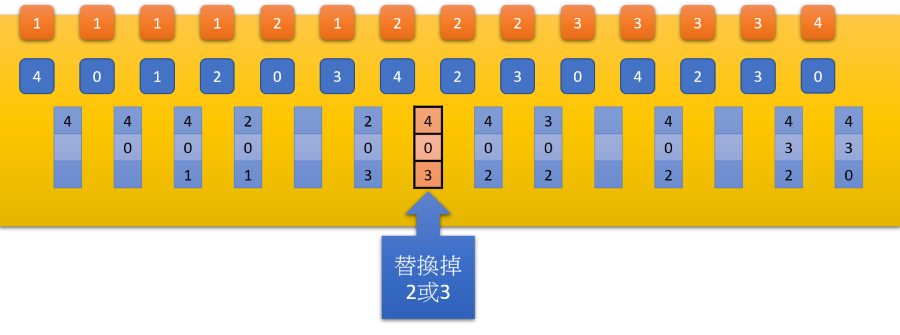
- 上方的橘色區塊代表該 page 被使用的次數
- 當需要 swap out 時,就會找到使用次數最少的 page page-out
- 如果使用次數都一樣這裡就假設 FIFO
MFU
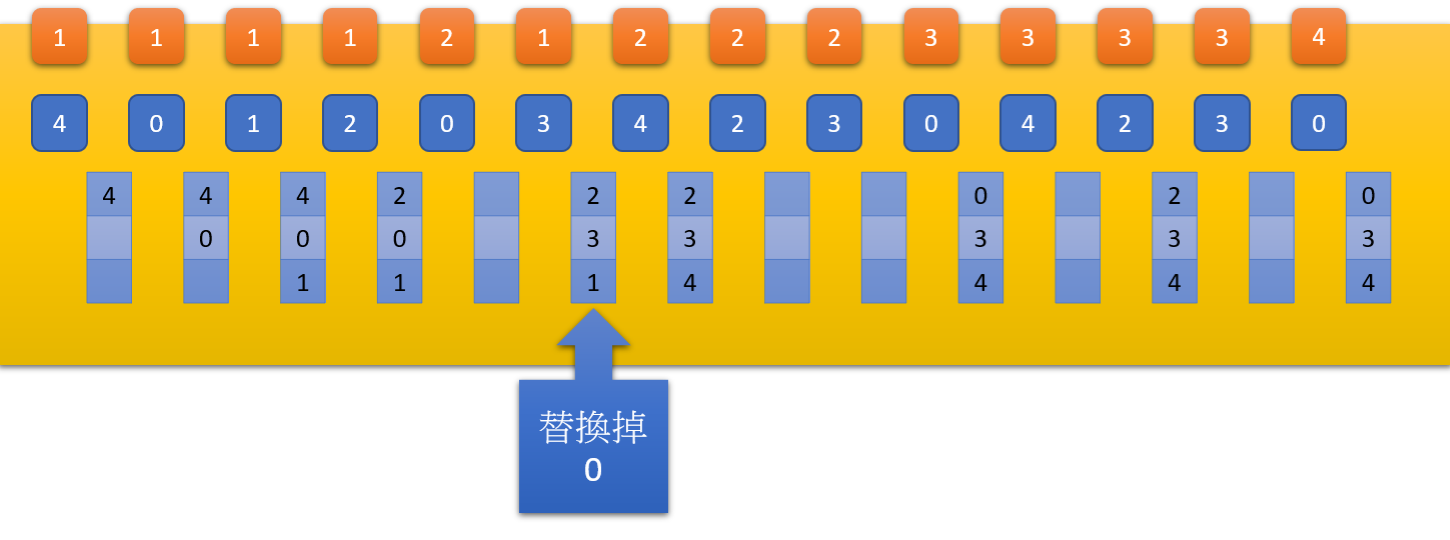
- 與 LFU 相反,找到使用次數最多的 page page-out
Conclusion
- Optimal algorithm: 理論上最佳化,但是不可能知道未來的 Access pattern
- LRU: 基於過去預測未來,實際上的效能不錯
- 但是要完全實現 LRU 需要增加硬體成本,例如: 紀錄 page 上次被存取的時間
- Second-chance: 有效且低成本的方式來實現接近 LRU 的效果
- 如果經常被存取,那 Access bit 會一直被設為 1
- 要 replancement 的時候會給有 Access bit 的 page 一個 second chance
- 很接進 LRU 的方式,相當於使用 1 個 bit 來當作時間戳記
- FIFO: 簡單,但是效能不好
- 因為放在 memory 中多久跟 page 是否會被使用沒有直接關係
- LFU: 保留過去常用的 page,需要一些機制來消除累積的 page 次數,不然有可能造成某些 page 一直被留在 DRAM 中
- MFU: 提除過去常用的 page,通常是在特定情況下才會有較好的效果
8.14 Linux’s Page Replacement
Linux 使用了兩個 LRU list 來實現 page replacement
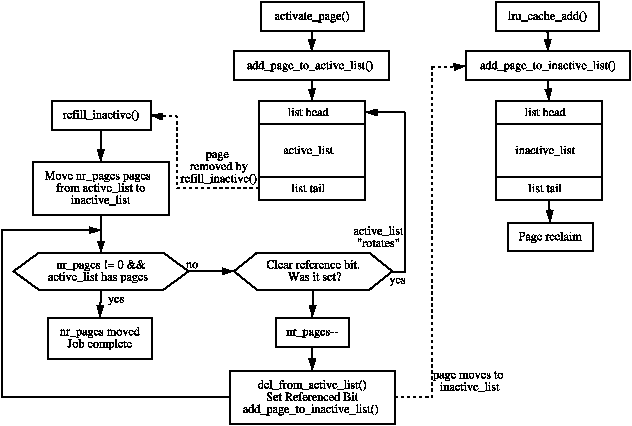
設計兩個 LRU 的好處是避免一些 page 去汙染 active list,例如: 一個一次性但很大的程式,那有可能就會把 active list 中真正需要的 page 踢出去, 有 inacitve list 就可以讓這些一次性的 page 保留在 inactive list 中,不會影響到 active list。
- 兩個 LRU list: active, inactive list
- Active list: 最近比較活耀的 page
- Inactive list: 最近比較不活耀的 page
- incative list 會定期的去檢查在一段時間內是否有 page 被存取過兩次,如果有就會被移動到 active list head
從 Active/Inactive list 移除 page 使用的是 Second-chance algorithm
- New page 通常會被放入 inactive list 的 head
- Inactive list 被填滿,就會將 tail 的部分 page 移到 swap space
- Active list 被填滿,就會將最 tail 的 page 移到 inactive list head
- 這樣的好處是,page 在 inactive list 中一直沒有被存取,就會慢慢移動到 tail,最後就會被移出 DRAM
- page 離開 inactive list 時,會把該 page 紀錄在 table 中,這個 table 只會紀錄最近丟棄的 page
- 如果有 new page 進入時,就會檢查 table 中是否有相同的 page,如果有就把該 page 移到 active list head
如果最近讀入的 page 剛好在 swap-out table 中,就表示演算法有失誤,例如: 這個 page 會被常常使用,只是存取的間隔比 inactive list 的時間長。
- 所以這裡會選擇把這個 page 移到 active list
- 丟進 active list 可以給他比在 inactive list 更長的時間有機會被存取
- 這裡可以討論的是是否要記錄這個間隔有多長,要不要以此去調整 inactive list 的時間
延伸閱讀: Linux Page Replacement
- 關於這個 Swap-out table 的設計,他的靈感或許來自 「Adaptive Replacement Cache」(IBM)
- 使用 Active + Inactive
- 融合了 LRU + LFU,只要常常被存取,即使不是最近被存取的也不太容易被移出 DRAM
在此之下可以思考的是,是否可以把 Active + Inactive 變成更多層的結構
Linux Page Replacement Steps
要注意這裡所提到的 Active/Inactive list 是 OS 上的資料結構,所以真正的 Asecced bit 是在 page table 上, 這兩個 list 所儲存的是 DRAM 中的 physical address。
在 OS 上的資料結構如何去知道 Access bit 的變化,實際的 Access bit 是存在 task 的 page table 上:
- 掃描 Inactive list,要反向的從 physical page 去找出對應的 page tabe
- 從 page table 中把該 Page 的 Access bit mapping 到 Inactive list 的 page
因為 Linux 中的 Inactive list 是使用 Second-chance algorithm,因此是沿著 circular list 不斷往下掃描每一個 entry, 逐一去更新 entry 中的 Access bit 即可。
這樣移除的時候也要反向的去找出對應的 page table,然後更新 page table 中的 valid bit,然後就將該 page 移到 swap space, mm_struct 中的 page table 會記錄這個 page 的使用情況是在 swap space 還是在 disk 中。
Last Edit
1-31-2023 21:14