OS | Process and Thread
Operating System: Design and Implementation course notes from CCU, lecturer Shiwu-Lo.
這章節主要是介紹 Process 跟 Thread
- Process model
- Process Life Cycle
- Communication model between Process & Process
- Communication method between Process & Process
- Producer-consumer problem
- Context switch main overhead (使用 Thread 的動機)
- Thread model
Process model
3.1 Process Concept
- An OS executes a variety of programs:
- Batch system – jobs
- Time-shared systems – user programs or tasks
- Process ≈ Task ≈ Job
- Process - a process is an instance of a program in execution
- +Program code (text section)
- +Program counter & registers (CPU status)
- +Stack
- +Data section
Batch system(批次系統): 是指被時間安排在 PC 上運行,不需要與使用者互動的工作
3.2 Process Memory
- 每個 Process 通常有自己完整的 Address space
- 32bit 為例,每個 Process 有 4GB 的 Address(Memory) space
-
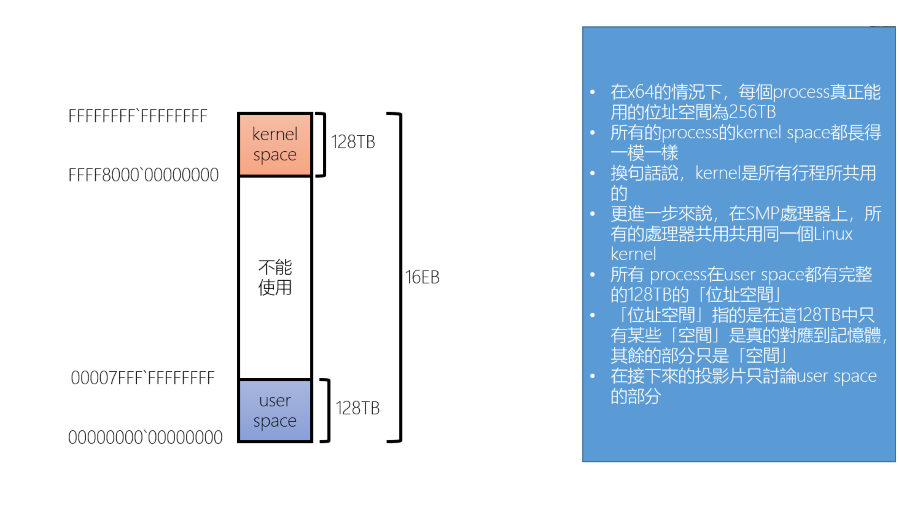
64bit 的 x64 CPU,因為成本的考量,通常只會使用 48bit 的 Address space,也就是 256TB (遠超 Disk 的容量)
- Address space 表示一個 Process 最多能使用多少 Memory,實際上 RAM 通常遠小於 Process 的 Address space
- 通常將 Process 的 Address space 分為兩個部分,上半部分為 OS Kernel,下半部分為 Process 的 User space
- 以 64bit 為例,一個 Process 的 Memory address(User space) 為 0~128TB,Kernel 則為 256TB(264) 往下 128 TB 的部分
- User space:
00000000 00000000~00007FFF FFFFFFFF - Kernel:
FFFF8000 00000000~FFFFFFFF FFFFFFFF
- User space:
Why kernel/user space need half of the memory space
- 每個 Process 的 Kernel Space 都是共用的,在 SMP Processor 上所有 Process 都共用同一個 Linux Kernel
- DRAM 有很多用途,例如: 作為 I/O 加速的 Buffer/Cache
- I/O Buffer: CPU 的資料可以先寫入 DRAM buffer,然後再由 DMA controller 將資料寫入 Disk
- I/O Cache: Disk 的資料可以寫入 DRAM cache,因為 I/O request 會產生 overhead
- 讀取 4kb 和讀取 16kb 的速度是一樣的,那乾脆一次從 cache 讀取 16kb
- OS 會把相關的資料放在 cache,這樣下次讀取就可以直接從 cache 讀取,而不用再次讀取 Disk
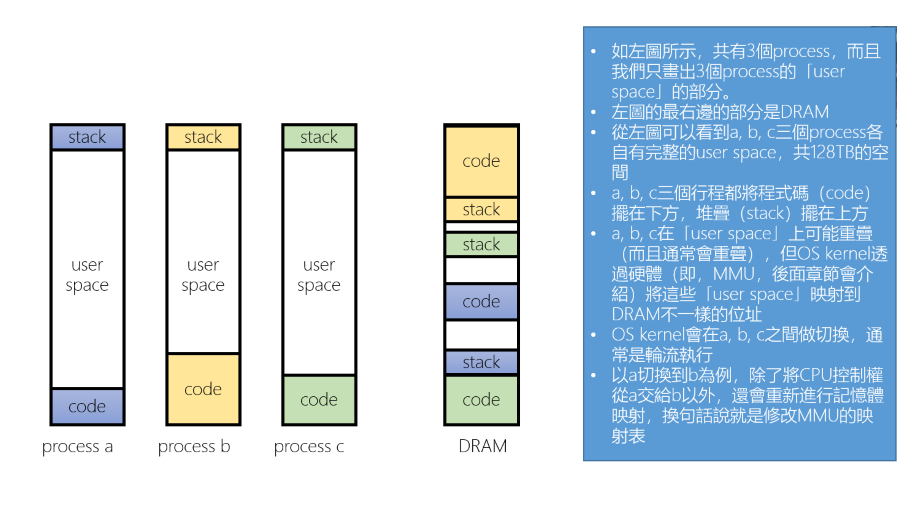
When Multi-Process running, what does the memory look like to users/programmers
這裡只討論 User space,一次只會執行一個 Process 這三個 Proces 各自有完整的 user space,當 Context switch 時除了 CPU 控制權會被交換外, 也會重新進行 Memory mapping(修改 MMU 的 mapping table)
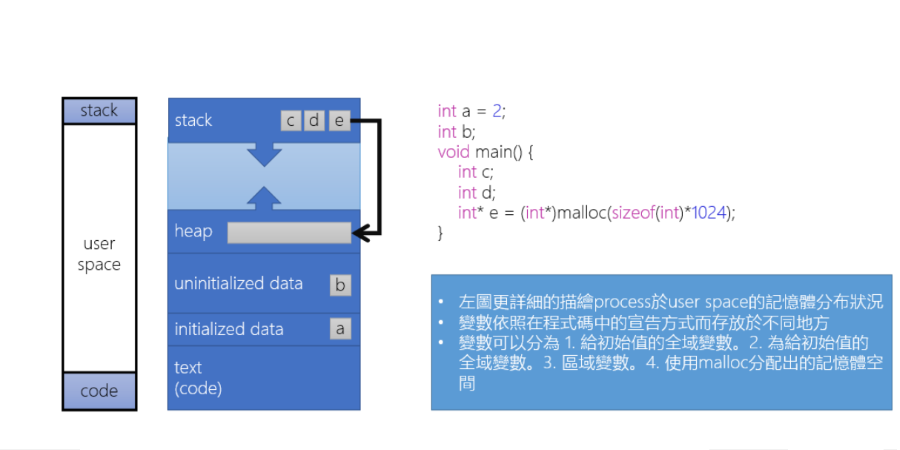
Internal memory configuration method of the Process
一個 Process 是怎麼在 Memeory 中進行分配的狀態
- Local variables: 在 Stack 中分配
- Global variables
- initialized value: 在 initialized data 分配
- uninitialized value(BSS): 在 unitialized data 分配
- Dynamic memory allocation: 在 Heap 中分配
- Program code: 在 Text section 分配,例如 Main, malloc function 的指令
通常 OS 一次會給 4096(4K) 大小的 Memory,並且會清空,這樣就不會有安全性問題,但寫程式時最好只預設 BSS 段的值會是 0,例如 Stack 可能會因為因為 Call/Return 的關係,而有一些不可預期的值。 但即使這樣也盡量要給予初始值,例如: int a = 0;,減少不可預期的錯誤發生
The position of variable in the Process
在一個程式執行時
- Text/initilized section 幾乎就是直接從 Disk copy 到 Memory
- Unitialized section 因為沒有資料儲存,所以可以透過一個資料結構來描述,並放在執行檔的 Header 中
- Stack/Heap 會隨著程式執行而變大,所以放在最後面並且往下/上成長
但是 Stack 通常會被限制在固定大小,例如: 一開始分配 16KB,當需要成長時就 OS 就再分配 4KB,但最多長到 8MB,這個可以透過 ulimit 查看或修改
如果一個 Memory 被寫入 DRAM 後,但長時間沒有被使用,那麼這個 Memory 就會被 swap out 到 Disk,這樣就可以釋放出 DRAM 給其他 Process 使用
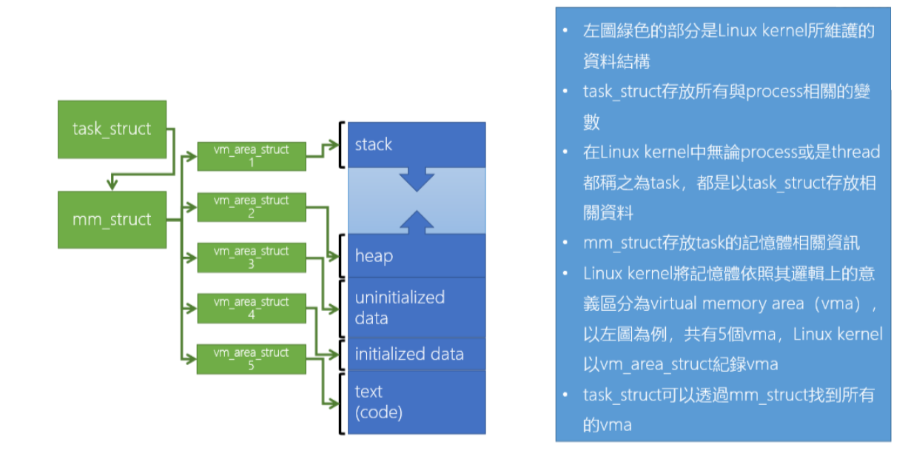
Linux kernel uses Logical meaning to manage memory segments of processes
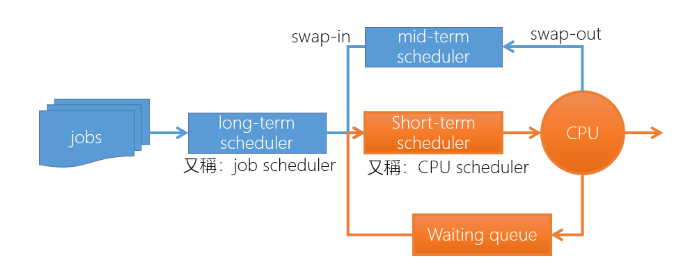
Linux Kernel 透過 task_struct, mm_struct, vm_area_struct 來管理 Process 的 Memory:
- task_struct: 描述 Task 相關的所有資訊
- mm_struct: 描述 Task 的記憶體相關的資訊,例如: 該 Task 的 Memory space 有哪些 area
- vm_area_struct: 描述該 area 相關的資訊,例如: 該 area 的起始位置、大小、權限等等
- 例如除了 Text area 是可 Read, Execute(rx),其他的 area 都是可 Read, Write(rw)
Example: Lab main.c
我們用一個簡單的程式 main.c 來做測試:
int a = 2;
int b;
int main() {
int c, d;
int* e = (int*)malloc(sizeof(int)*1024);
printf("pid = %d\n", getpid());
printf("main = %p\n", main);
printf("printf = %p\n", printf);
printf("a=%p, b=%p, c=%p, d=%p, *e=%p\n", &a, &b, &c, &d, e);
getchar();
return 0;
}
/*
benson@vm:~/OSDI$ ./main.exe
pid = 190697
main = 0x55d00a13218a
printf = 0x7f94c1974cc0
a=0x55d00a135010, b=0x55d00a135018, c=0x7ffe4cb7e4b8, d=0x7ffe4cb7e4bc, *e=0x55d00aca62a0
*/
然後在 /proc/
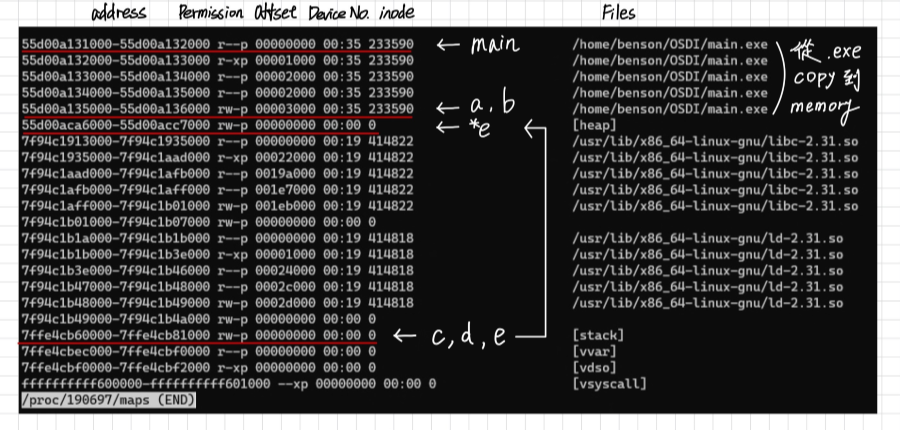
Address space layout randomization
如果我們重新執行一次程式,會發現 Address 又不一樣了,這是為了避免被攻擊,就是 Address space layout randomization(ASLR)
- 這樣可以避免攻擊者使用記憶體裡面的函數,例如: libc 裡面的 system(),如果可以執行 system(),那麼就可以執行任意的指令
- OS 會隨機產生每個 Section 的 Address
- 幾乎所有的 OS 都支援 ASLR,例如: Linux, BSD, Windows, MacOS
- 但是 ASLR 也有缺點,如果不使用 ASLR 那就可以把常用的 Function 放在固定的位置,這樣就可以加速程式的執行
- 目前大部分硬體都使用 phy.cache 可以降低這部分的影響
現在的 Linux Kernel 都會使用 ASLR,即是 KASLR
Program in Memory
- 目前大部分的作業系統設計中,執行檔與在 Memory 中的結構幾乎一樣,OS 只需要 Copy(mapping) 就可以執行了
- 例如: Linux 的 ELF(Executable and Linkable Format), Microsoft 的 PE(Portable Executable)

將執行檔 Mapping 1:1 映射到 Memory,這樣讓 OS 的工作能變得很簡單
Process Life Cycle
3.3 Process Life Cycle
下面是一個 Unix Process Life Cycle,但在這裡加入了一些 Linux 的觀念
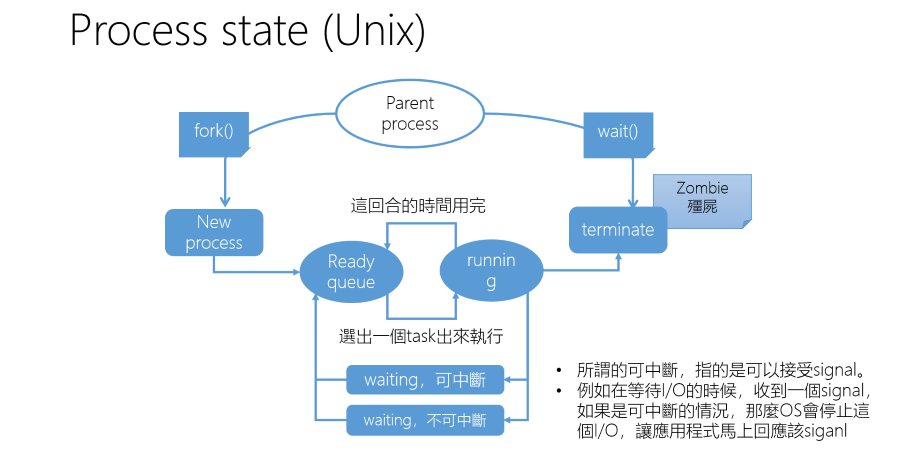
Parent Process 通常是 Shell,透過 fork() 產生 Child Process
- Ready queue: 當一個新的 Process 產生會進入 Ready Queue,等待 CPU 資源
- Running: 如果 Scheduler 選擇到該 Process,那麼就會進入 Running 狀態
- Waiting: 在 Linux 中 Waiting 分為兩種
- Interruptible: 可以被 Signal 打斷
- Uninterruptible: 不能被 Signal 打斷,但是少數例外下例如 Kill -9 還是能夠 Interruptible
- Terminate: 這裡需要由 OS 去回收分配給 Process 的資源,例如: Memory, Kernel 中儲存的 Process 相關資訊
- Zombie: Linux 中會剩下一個大約 4KB ~ 8KB 的 Task struct,稱作 Zombie
- 保留這個 Zombie 是為了讓 Parent Process 可以透過 wait() 取得 Child Process 的資訊, 這裡如果 Parent 沒有正確的回收 Child Process,但還是持續運行,這樣 Zombie 就會越來越多。 但如果 Parent 也結束了,那麼 Zombie 就會被 init process 回收,這樣就不會有 Zombie Process
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
pid_t child_pid;
/* Create a child process */
child_pid = fork();
if (child_pid > 0) {
/* Parent sleep */
sleep(60);
} else {
/* This is clild process will end immediately */
printf("Child pid %d\n", getpid());
exit(0);
}
return 0;
}
這個程式會印出 child_pid,此時去 top -p child_pid 就可以看到 child 變成 zombie 狀態。
fork() 會返回 child pid,但在 child process 中 child_pid 會是 0
3.4 Tack Contol Block(TCB, PCB)
Process control block ≈ Task control block
Process control block(PCB) 就是 OS 用來管理 Process 的資料結構,通常會包含以下資訊:
- Process state: 執行的狀態,例如: Running, Waiting, Ready
- CPU information: Process 的狀態,例如: PC, Register
- Memory information: Memory 狀態,例如: Text, Data section
- Schedule information: 排程資訊,例如: Priority
- I/O status information: I/O 狀態,例如: File descriptor
- Using resource: Process 使用的資源,例如: File, I/O device
…
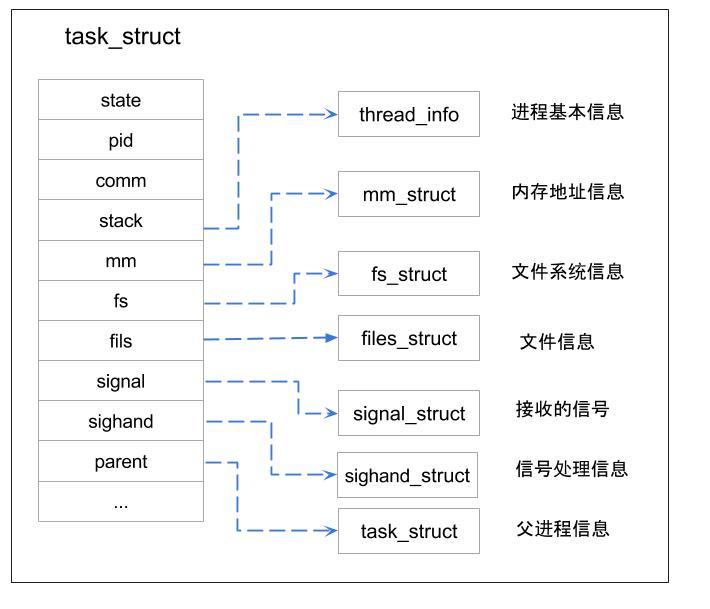

3.5 Three Scheduler Model
Scheduler 不是只有 CPU Scheduler,還有 Long-term Scheduler, Mid-term Scheduler:
- Long-term Scheduler(Job scheduler):
- 決定哪些 Process 要進入 Ready Queue,通常在很大型的主機上,例如: 台灣杉
- Linux 中並沒有 Long-term Scheduler,Task 產生後就會進入 Ready Queue
- Mid-term Scheduler(Swapper):
- 當 Degree of Multiprogramming 過高時可能造成(thrashing),將一些 Task swap out 到 Disk,等到資源足夠時再 swap in
- Linux Kernel 目前也沒有 Mid-term Scheduler,但 Linux 依照 Task 記憶體的使用情況,在 Memory 不足時會將不活躍的 Task swap out 到 Disk
- Short-term Scheduler: CPU Scheduler
- 大部分的 OS 只有 CPU Scheduler,針對各種事件有專屬的 Waiting Queue,例如: 例如 I/O, Semaphore
thrashing(輾轉現象) 指的是當虛擬記憶體被使用過度,導致大部分的工作在處理 Page fault 所造成的 Page Replacement,這樣就會造成 CPU 效能下降
3.6 Context Switch(ctx-sw)
- 目前主流的 OS 都是只有 Task 執行在 Kernel Space 時才能進行 Context switch
- Context switch 主要是切換 Register 與 Memory 的內容
- Context switch 的 overhead 主要是發生在 Cache memory 的更新
- 首先 TaskA Mode change 到 Kernel mode
- 然後將 TaskA 的資訊(TCB) 儲存起來
- 載入 TaskB 的資訊
- 最後 TaskB Mode change 到 User mode
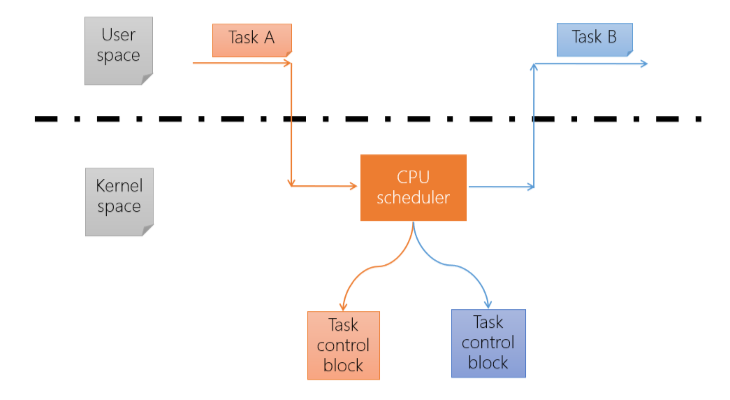
Scheduler 也就是策略的部分主要是用 C 寫的,但切換的部分是用 Assembly 寫的,因為要直接操作 Register
3.7 Processes are divided into I/O and CPU
- I/O Bound process - I/O time » CPU time
- 例如: ftp server
- CPU Bound process - CPU time » I/O time
- 例如: image processing
- 如果可以選擇的話,讓系統中同時存在 I/O Bound process 與 CPU Bound process,可以讓系統的效率最大化
- 通常 I/O Bound 的優先權比較高,因為趕快讓 CPU 發出命令給 I/O device,然後就可以去執行其他的 Task

I/O Bound 通常只需要一小部分的 CPU 資源,如果設定成 CPU Bound 優先權較高,反而會造成 I/O Bound 的 Task 在結束一段 I/O 後還要等待 CPU Bound 的 Task 結束 造成 CPU 使用率下降
3.8 Process Creation
- Linux 中可以透過 fork, vfork, clone 來產生 Process
- 實際上這三個在 Kernel 中都是呼叫 do_fork() 來完成
- Linux 中 pid 0 是 idle process,優先權最低,只負責讓 CPU 進入睡眠狀態
- 通常也叫做 swapper,每顆 core 有一個自己的 idle task
- pid 1 是系統中第一個 user space 的行程,負責作業系統的初始化
- 例如: 當電腦啟動時的 Daemon Process
- fork 出的 Process 其程式碼與父 Process 完全相同,如果要載入新的程式碼到該 process 中,使用 execve 系統呼叫
- 如果需要大量的執行 execve,那使用 vfork 會比較好,因為 vfork 會 Block parent process
pid 0 Process(idle process) 也是唯一沒有使用 fork() 產生的 Process,因為 pid 0 是系統啟動時就產生的 Process
使用 pstree -p 就能看到,所有的 Process 都是由 systemd(pid 1) 產生的
例如: 從 bash 去執行 ls 會有以下的流程
- bash fork 出一個 child process,然後 parent process wait()
- child process 透過 execve() 去執行 ls
- ls 執行完後,透過 exit() 結束,回到 parent process
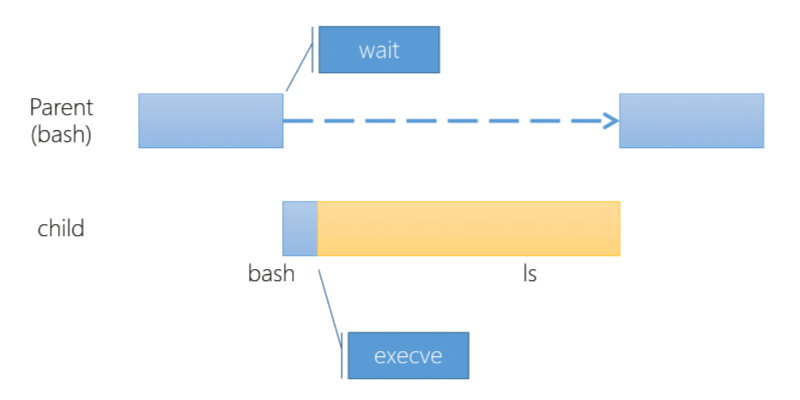
3.9 Process Termination
- 在 UNIX-Like OS 中,如果一個 Process Terminate,會變成 Zombie 狀態,Zombie Process 是無法被 kill 的,只能透過 Parent Process 使用 wait() 來回收
- 透過 wait() Parent Process 可以取得 Child Process 的結束狀態,例如: 使用了多少系統資源
- 基於特定的需求,也可以直接將 Process kill 掉
- kill -9 pid 會直接發送 SIGKILL(signal 9) 給該 Process,讓該 Process 立即結束
- kill pid 則是發送 SIGTERM(signal 15) 給該 Process,讓該 Process 優雅的結束自己
- 有些 OS 設計 Parent process kill 掉後,Child process 也會被 kill 掉
- UNIX-Like OS 中,如果 Parent process 被 kill 掉,Child process 會被 init process(pid 1) 接管
- init 內部有一個無窮迴圈,會不斷的執行 wait(),這樣就可以回收所有的 Zombie Process
例如我們可以透過 nohup 或 screen 來讓 Process 在背景執行,這樣就不會因為 Terminal 被關閉而被 kill 掉
Communication model between Process & Process
OS 保證每個 Process 之間都可以獨立的運行
- 但如果真的 Process 都完全獨立運行,那系統就會變得很難使用
- 例如: copy-paste
- 所以 OS 會提供一些方法讓 Process communication
3.10 Interprocess Communication(IPC)
IPC 是指可以讓兩個獨立的 Process 互相傳遞訊息,傳遞訊息的目的多半是
- 傳遞資訊,例如: copy-paste、information sharing
- 同步,例如: Parallel computing
- 模組化設計,例如: 將 Request 與 Worker 分開
IPC Model
這裡談的主要是 IPC 的分類,而不是 IPC 的實作
- 如何在 Process 之間建立 IPC
- 可以建立多少條 IPC 在 Process 之間
- 可否多個 Process 同時使用同一個 IPC
- IPC 有沒有容量限制
- IPC 中每一個 Message 的大小是否是固定的
-
IPC 是單向的還是雙向的
- Direct communication(直接傳遞): 每個需要通訊必須明確的指定接收者或發送者
- 可以是單向也可以是雙向的
- 例如: Pipe
- Indirect communication(間接傳遞): Message 是發送到 Mailbox 中然後由 Receiver 自行取出
- 是雙向的,並且可以建立多條 IPC 或讓多個 Process 一起接收
- 因為有 Mailbox 所以就要考慮 Buffer 的問題
- 沒有 Buffer: 那就必須等到 Recv 結束,發送者才能繼續執行
- 優點是速度通常比較快,透過 Scheduler 或許某些資訊可以放在 Register 中直接傳遞
- 固定 Buffer: 發送者將資料 Send 到 Buffer 中就可以繼續執行
- 多個 Buffer: 發送者可以一直送資料,但通常會限制發送的數量避免惡意程式
- 沒有 Buffer: 那就必須等到 Recv 結束,發送者才能繼續執行
Direct communication
通常使用 Process id 來將訊息丟給對方:
- send(P, message)
- receive(Q, message), receive(&Q, message)
- Receiver 可以指定是要從哪裡收,或者收任何訊息,由 OS 來告知是誰送的
Feature
- 不需要特別的建立連接
- 由於使用 Process id 來傳遞訊息,因此只能是任兩個 Process 之間傳遞訊息
- 由 P 和 Q 兩個單項傳遞來組合成一個雙向傳遞
Indirect communication
需要由使用者來建立傳輸通道
- 例如: Linux 的 mkfifo, pipe
- 例如: TCP/IP (如果在同一台機器上傳輸資料,不會經過 Network card)
Feature
- 溝通的行程可以建立多個通道,可以簡化設計複雜度
- 可以「多個傳輸行程」對「多個接收行程」,常見於 Server 的設計
- 雙向,例如: Shared memory
- 單向,例如: pipe
Problems by many-to-many
如果有「多個傳輸行程」對「多個接收行程」
- 由誰接收
- 是否由「通道管理程式」決定?
- 誰先發起,就由誰收
- 收了訊息之後怎麼處理
- 移除訊息,通常用於 Server 將 Task 交給一個 Sub-Server
- 一直存在,類似於廣播
Blocking & Non-Blocking
- 如果有足夠多的 Buffer 的話,Process 間的通訊可以是 Non-blocking
- 送出 Message 後 Process 繼續下一個工作
- 例如: signal
- 如果 Buffer 不足,或者根本沒有 Buffer 的話,就只能是 Blocking
- 送出 Message 後必須等待 Receiver 接收完畢,才能繼續工作
- 這個的好處是可以確認對方已經收到 Message
3.11 Communication method Direct or Indirect
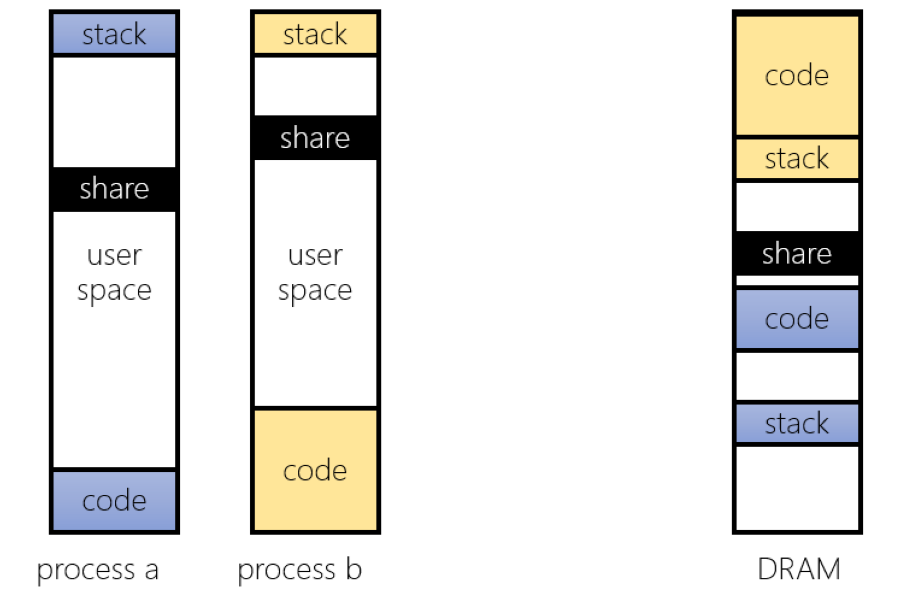
Shared Memory
在 Physical memory 上 Process A 和 Process B 是使用不同的區段,但是 Shared memory 就使用同一區段
- 要注意這裡是 Physical memory,但在 Process 中是不同的 Logical address
- 在 Linux 上可以透過 mmap() 來建立 Shared memory
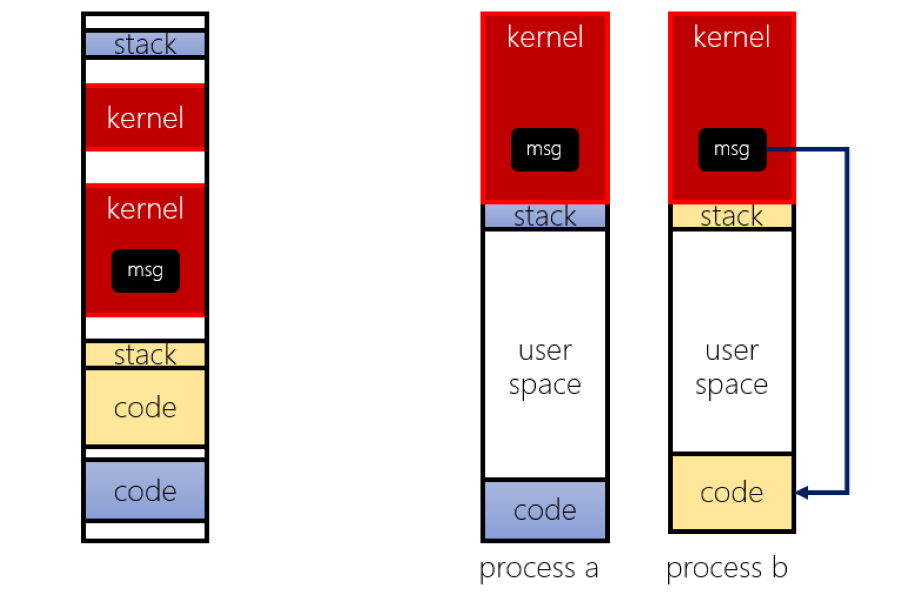
Message Passing
- 在 Process A 時呼叫 Kernel copy 資料到 Kernel space
- Context switch 到 Process B 時,Kernel 再將資料 copy 到 Process B 的 Memory
Producer-Consumer problem
這裡先簡單討論 Producer-Consumer Problem 的概念,後面會再討論如何解決
- 假如有兩個 Process 共享一個固定大小的 Buffer,Producer 會不斷的產生資料,然後放到 Buffer 中由 Consumer 來取出
- 如果 Buffer 滿了,Producer 就必須等待 Consumer 取出資料
- 如果 Buffer 空了,Consumer 就必須等待 Producer 產生資料
- 這樣如果沒有設計好就容易造成 Deadlock
如果是單對單的 Producer-Consumer,可以透過一個環狀 Linked list 解決,詳情請看 OS-CH03-重要的生產消費問題
Thread concept
3.12 Context switch main overhead
The overhead of context-switch
- Store/restore the register file (~1KB)
- TLB miss (~1KB)
- CPU cache miss (~1MB)
在 Context 中最主要的消耗就是 Cache miss,這取決於硬體的支援
- Virtual cache: 就需要把 Flush Cache,透過 MMU 將 Virtual address 對應到 Physical address
- Physical cache: 不需要 Flush cache
- 需要 MMU 轉換 Virtual address 成 Physical address,才能放入 Cache,轉換的過程就會有 Latency
- 例如: CPU Cache miss 在等待 L2 Cache 抓到資料,或是 L1 miss 之後需要 MMU 轉換 L2 之後才能做存取
- 例如: Process A/B,進行了一個 A -> B -> A 的切換,它們各自執行的時候都會把資料放入 Cache,A 只能期望 B 沒有覆蓋掉需要的資料
- Cache 是否支援 ASID (Address Space Identifier)
- 在 TLB 中加入一個 Process ID,只有當 ASID 與 Page number 都相同時,才會 Hit
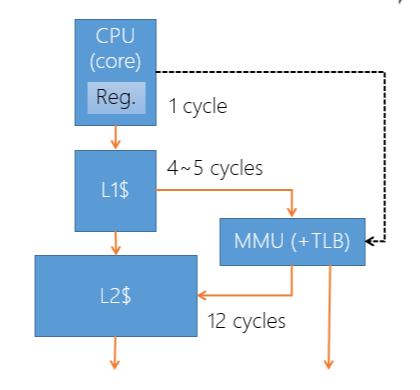
3.13 Thread memory
- Thread 在同一塊 Virtual memory 中執行,但是有各自的 Stack
- 因為在同一塊 Virtual memory 中執行,所以 Thread1 可以存取 Thread2 的 Stack
- 要做這樣的存取要慎重,因為 Stack 會隨著 Function call 而變動
Thread Local Storage
同樣的 Thread 之間也會有各自的 Local variable,這些 Local variable 會放在 Thread Local Storage 中, 這是由 Compiler 來設計的,讓每個 TLS 偏移量都不一樣,這樣就能讓 Thread 存取自己的 Local variable。
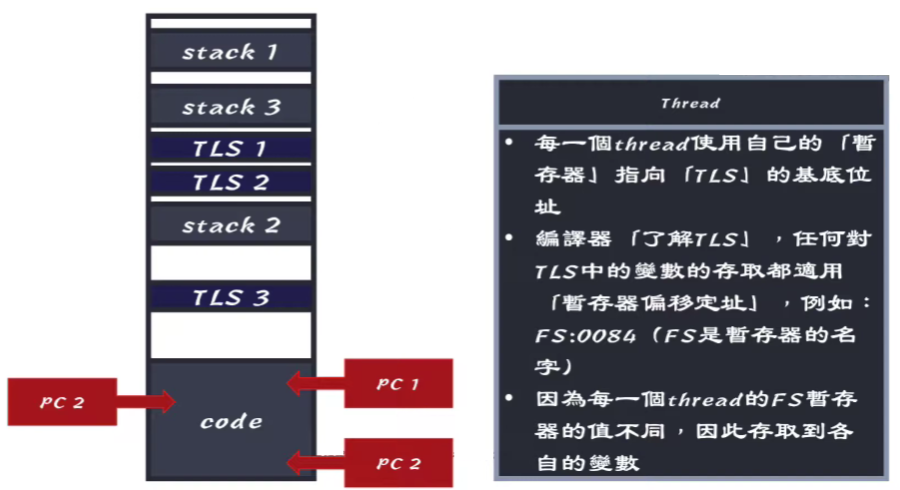
3.14 Thread history
- Many to One
- One to One
- Many to Many
Many to One
多對一就是兩個 Thread 共用一個 PCB,這樣的話如果其中一個 Thread 跑去做 I/O 的話,那整個 Process 就會被 Block,這樣就會造成整個 Process 都被 Block。 同時由於 OS 不會知道 PCB 上的是兩個 Thread,所以無法再多核心上執行,這樣就會造成效能的下降。
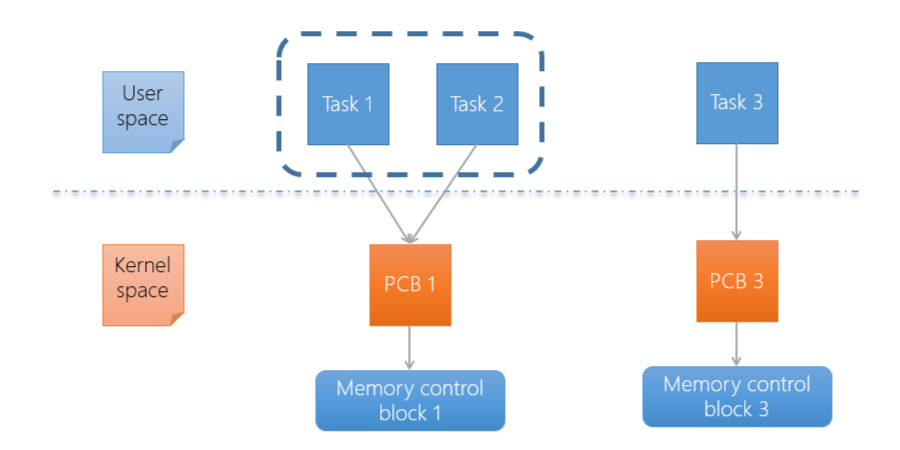
Green thread Green thread 是為了在底層的 OS 不支援 Thread 的情況下,透過 Library 來模擬 Thread 的行為,但這樣就只能使用 Many to One 的模型,例如: Java 的 Thread
通常只有在 OS Kernel 不支援 Multi-thread 的情況下,才會使用 Many to One,由於所有的 User thread 在 Kernel 都只有一個 PCB, 所以如果 Thread 跑去做 Block 的操作會導致其他 Thread 也被 Block。並且就算有很多 Processor 通常也只有一個 Thread 在執行,其他 Thread 都在等待。
One to One
通常是最多 OS 使用的 Model,每個 Thread 都有自己的 PCB,要透過 Memory control block 來判斷是 Thread 還是 Process, 如果共用 Memory control block 的話,那就判定他是一個 Thread。
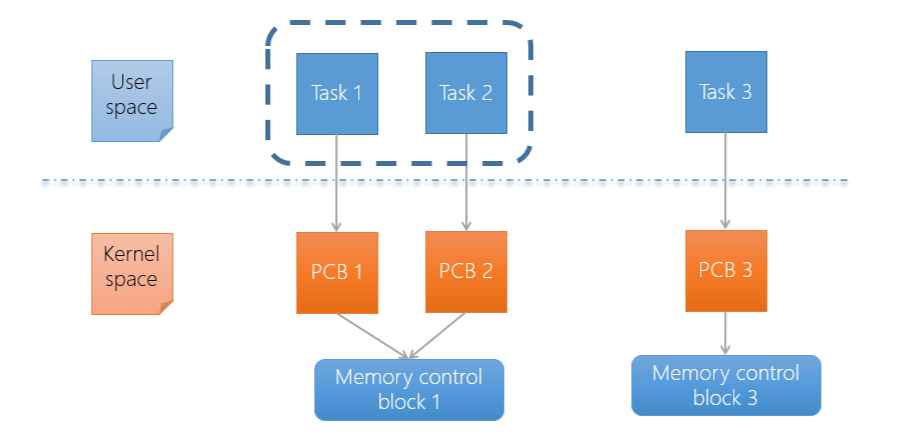
- 由於每個 Thread 都有自己的 PCB,所以可以在多核心上執行
- 大部分都是 Non-blocking,所以在處理 Block 的任務上會很有彈性
Many to Many
上面的稱作 User thread,下面稱作 Kernel thread,對應的方式有很多種,例如下圖代表上面的 User thread 可以同時發出同等 Kernel thread 數量的 System call, 但缺點是非常複雜並寫不好寫,並且不易理解,讓程式設計者很難進行優化。
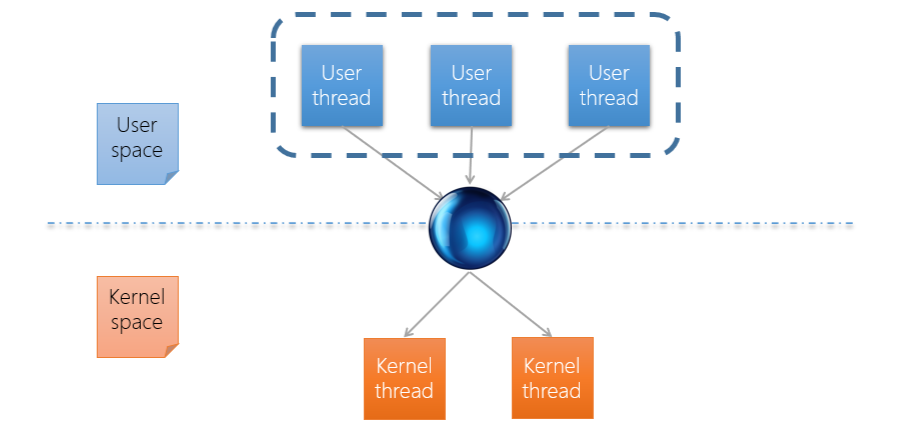
- 看起來是最有彈性的 Thread
- Sun Solaris 9 之前支援 Many to Many Model
- Sun Solaris 10 之後改為主要支援 One to One Model
Last Edit
10-21-2023 18:52