OS | Synchronization (Unfinished)
Operating System: Design and Implementation course notes from CCU, lecturer Shiwu-Lo.
這個章節主要講的是 Linux 中如果有多個 Task 同時存取記憶體,要怎麼去處理 Synchronization 的問題。
- 多個 Task 如果同時存取 Memory 會發生彼此複寫的問題
- 同時 Peripheral devices 在 MMIO 中也是一塊 Memory
- 要保護 Memory 最直覺的想法是不要讓會存取同一份 Memory 的 Task 同時執行
- 設計 Critical Section,避免 Task 同時執行
- Critical Section 還必須是有效率,公平的
- 具有啟發性的方法 Peterson’s solution
- 假設 read, write 是 atomic operation
- 證明 Peterson’s solution 滿足 Critical Section 三個條件
Critical Section 三個條件: Mutual Exclusion, Progress, Bounded Waiting
- C11 實現 Peterson’s solution
- 挑選合適的保護機制
- Mutex( /semaphore) = spinlock + sleep + wakeup
- 預期等待的時間很短,使用 spinlock,例如: (Peterson’s solution)
- 需要等待一段時間,使用 mutex 或 semaphore
- 上述的 sleep 與 wakeup 在 Linux 中由 system call
futex實現
spinlock 與 peterson’s solution 都類似於使用 while loop 來做 busy waiting
- 常見的問題形式
- Producer-Consumer Problem(生產者與消費者問題),例如: 驅動程式與周邊設備的溝通
- Dining Philosophers Problem(哲學家就餐問題),例如: 多個 Task 之間的資源交換
- Reader-Writer Problem(讀者與寫者問題),例如: 只有閱讀檔案而不修改檔案的 Task
- Multi-Process 同時存取時,要依照哪個 Process 的時間
- 或者如何保證分散式系統之間也能保證存取的正確性(版本概念)
最後討論一些深入的問題
- 從硬體的角度來看 atomic operation 的實現
- 了解軟體使用的 atomic operation 的代價
- 以 Linux kernel 為例說明應用技巧
- 多種的 spinlock(C11 實現),semaphore(以驅動程式為例)
- 更深入的討論 memory order
- Atomic 在多處理器上要做到多少的保證
5.1 Multi-Process processing one data at the same time
這裡用一個簡單的例子來說明同時處理一筆資料會產生的問題,可以看到輸出結果並不是我們預期的,這是因為兩個 thread 同時存取 global 變數,造成彼此複寫的問題。
#include <pthread.h>
int global=0;
void thread(void) {
for (int i=0; i<1000000000; i++)
global+=1;
}
int main(void) {
pthread_t id1, id2;
pthread_create(&id1,NULL,(void *) thread,NULL);
pthread_create(&id2,NULL,(void *) thread,NULL);
pthread_join(id1,NULL);pthread_join(id2,NULL);
printf("1000000000+1000000000 = %d\n", global);
}
// 1000000000+1000000000 = 1037054916
使用 gcc -o exam1.exe exam1.c -g - 之後使用 gdb 來查看程式碼,使用 disassemble \m thread 來反組譯觀察問題在哪,
\m 代表把 c 跟 assembly code 一起顯示。
gdb ./exam1.exe
(gdb) disassemble /m thread
Dump of assembler code for function thread:
4 void thread(void) {
0x0000000000001159 <+0>: push %rbp
0x000000000000115a <+1>: mov %rsp,%rbp
5 for (int i=0; i<1000000000; i++)
0x000000000000115d <+4>: movl $0x0,-0x4(%rbp)
0x0000000000001164 <+11>: jmp 0x1179 <thread+32>
0x0000000000001175 <+28>: addl $0x1,-0x4(%rbp)
0x0000000000001179 <+32>: cmpl $0x3b9ac9ff,-0x4(%rbp)
0x0000000000001180 <+39>: jle 0x1166 <thread+13>
6 global+=1;
0x0000000000001166 <+13>: mov 0x2ec0(%rip),%eax # 0x402c <global>
0x000000000000116c <+19>: add $0x1,%eax
0x000000000000116f <+22>: mov %eax,0x2eb7(%rip) # 0x402c <global>
7 }
0x0000000000001182 <+41>: nop
0x0000000000001183 <+42>: nop
0x0000000000001184 <+43>: pop %rbp
0x0000000000001185 <+44>: ret
End of assembler dump.
假設 global 的初始值為 0,在這個程式中有可能會依照這樣執行,CPU1 做完加法後寫入 %rip,CPU2 也做完加法後寫入 %rip,這樣就會造成彼此複寫的問題。
CPU1 CPU2
1. mov 0x2ec0(%rip),%eax 1.
2. 2. mov 0x2ec0(%rip),%eax
3. add $0x1,%eax 3.
4. mov %eax,0x2eb7(%rip) 4.
5. 5. add $0x1,%eax
6. 6. mov %eax,0x2eb7(%rip)
Atomicity 的意思就是當我們在對一個 Data struct 做操作時,要保證整個 struct 是一次性的更新,這裡的 global variable 是一個非常簡單的例子,但是在實際的程式中可能會有很複雜的 Data struct, 因此要保證整個 struct 是一次性的更新是非常困難的。
- Definition correct solution
- 一個正確的 Multi-thread program 應該要跟其對應的 Single-thread 的 program 有相同的行為
Critical Section
5.2 Race condition problem
5.3 Critical section three conditions
5.4 Peterson’s solution
5.5 Proof peterson’s solution
5.6 C11 implementation
Critical section 其實就是一套協定,這套協定使多個 Task 之間可以互相合作
5.2 Race condition problem
Race condition(競爭條件)是指軟體系統的行為,當操作是基於無法控制順序的事件或時間,當這些事件沒依照 Programer 意圖的順序發生時,就會出現 bug。
- Race condition 的其中一種解決方式就是
- 引入 Critical section,讓 Task 之間互相合作
- 注意 Critical section 所保護的是程式碼
5.3 Critical section three conditions
- Mutual Exclusion(互斥, 基本條件)
- 如果有一個 Task 在執行 Critical section,那麼其他 Task 就不能執行 Critical section
- Progress(進展, 有效率)
- 如果沒有 Task 在執行 Critical section,只有不在 Remainder section 的 Task 才能決定誰可以執行 Critical section,並且不能無限期的等待
- Bounded Waiting(有界等待, 公平性)
- 如果有一個 Task 想要執行 Critical section,那麼就不能讓這個 Task 被無期限的等待
- 例如: 有 A, B 兩個 Task,但故意永遠只讓 A 執行 Critical section,這樣 B 就會無限期的等待
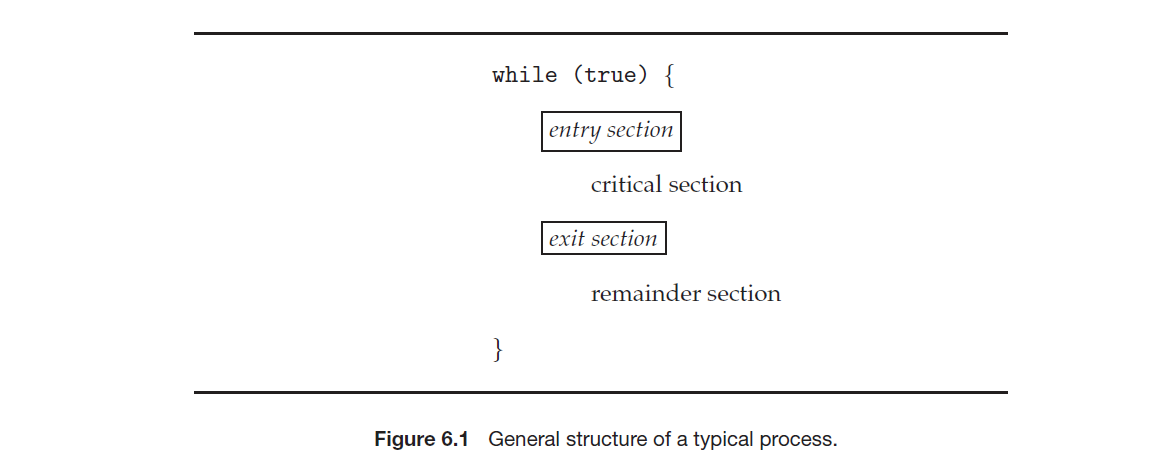
libc 其實並沒有滿足 Bounded Waiting 的條件,在某些情況下會造成 starvation
5.4 Peterson’s solution
Peterson’s solution 是一個完全解決 Race condition 的純軟體演算法
- 假設只有 P0, P1 兩個 Task
- 對於硬體有一些基本假設
read,writeis atomic operation- shard memory system
- 因為假設是 shard memory system,所以無法用在 distributed system
- Peterson’s solution 可以擴展到 N 個 Task
- 假設 P0, P1 共享兩個變數
boolean flag[2] = {false, false}; /* Represents who wants to enter the Critical section */ int turn; /* 0 means P0, 1 means P1 has priority when entering the critical area */ - P0 source code
while (1) { flag[0] = true; /* P0 wants to enter the critical section */ turn = 1; /* IF P1 wants to enter the critical section, P1 has priority */ while (flag[1] && turn == 1) ; /* busy waiting */ /* critical section */ flag[0] = false; /* exit section */ /*remainder section */ } - 注意 P0 會在 turn 優先讓 P1 進入 Critical section,同樣的 P1 也會在 turn 優先讓 P0 進入 Critical section
- 對方想進入 Critical section,那麼自己就讓對方進入 Critical section
- 沒有人想進入 Critical section,那麼就自己進入 Critical section
- 對方離開 Critical section 後,自己就可以進入 Critical section
5.5 Proof peterson’s sol to satisfy critical section three conditions
Proof:
- Mutual Exclusion
- Shard memory 中,Task 都能修改 turn, 所以 turn 只會有兩個值,0 或 1
write必須是 atomic operation,否則 P0, P1 有可能讀到不同的值
- Progress
1. flag[0] = true; 1. flag[1] = true; 2. turn = 1; 2. turn = 0; 3. while (flag[1] && turn == 1) 3. while (flag[0] && turn == 0)- 假設 P0 想進入 CS,P1 沒有想進入 CS,
flag[1] = false,這樣可以直接進入 CS - 假設 P0 想進入 CS,P1 只執行到 flag[1] = true,這樣 P0 會進入 busy waiting,但是 P1 會在 turn = 0 再次禮讓 P0 進入 CS
- 假設 P0, P1 都同時執行到 while loop,但是 turn 會確保至少有一個 Task 會進入 CS
- 假設 P0 想進入 CS,P1 沒有想進入 CS,
- Bound Waiting
1. flag[0] = true; 1. flag[1] = true; 2. turn = 1; 2. turn = 0; 3. while (flag[1] && turn == 1) 3. while (flag[0] && turn == 0) 4. flag[0] = false; 4. while (flag[0] && turn == 0) 5. flag[0] = true; 5. while (flag[0] && turn == 0) 6. turn = 1; 6. while (flag[0] && turn == 0) 7 while (flag[1] && turn == 1) 7. while (flag[0] && turn == 0)- 這裡的重點其實在於 turn,不是 flag,因為 flag 只是代表誰想進入 CS,但是 turn 代表誰有權利進入 CS
- 假如 P0 把 flag 設為 false 的時候,剛好 P1 被 ctx 這樣也並不會錯過進入 CS 的機會
- 所以在 P0 禮讓的情況下,P1 一定會在下次進入 CS
在這裡會覺得好像 flag, turn 的順序如果調換也會有一樣的效果,但是記住 flag 只是代表誰想進入 CS,但是 turn 代表誰有權利進入 CS,如果調換會有以下情況
1. while(1) { 1. while(1) {
2. turn = 1; 2.
3. 3. turn = 0;
4. 4. flag[1] = true;
5. 5. while (flag[0] && turn == 0)
6. flag[0] = true; 6. /* Critical Section */
7. while (flag[1] && turn == 1) 7.
8. /* Critical Section */ 8.
9. 9. flag[1] = false;
10. flag[0] = false; 10. /* Remainder Section */
11. /* Remainder Section */ 11. }
12. } 12.
- P1 進入 CS 但是是因為 flag[0] = false,而實際上 P0 也想進入 CS 只是還沒有執行到
- P0 進入 CS 但是是因為 turn = 0,對方禮讓但其實對方還在 CS 中只是還沒將 flag 設置為 false
- 這樣就會造成 P0, P1 同時進入 CS,違反
Mutual Exclusion
- 這樣就會造成 P0, P1 同時進入 CS,違反
Proof flag must before turn:
- P0 和 P1 同時執行,都有可能去執行 turn,因此 turn 不是 0 就是 1
- 這裡的前提是一定會有
flag[0] == flag[1] == 1代表兩者都想進入 CS- 這個步驟是必須的,必須先確認要進入 CS,之後才能去禮讓對方
理解這部分是為了如果之後要設計 spinlock,即使有很多已經寫好的演算法,但是依然有可能在特別的情況下需要自己設計,此時理解這部分的證明就非常重要
5.6 C11 implementation
在 C11 實作的時候要注意的是使用
peterson’s-sol.c, P0 的程式碼如下,注意到要使用 atomic_store 進行操作,並且在 atomic_thread_fence() 來保證編譯器最佳化不會修改程式碼的順序。
atomic_int turn=0;
atomic_int flag[2] = {0, 0}
void p0(void) {
printf("start p0\n");
while (1) {
atomic_store(&flag[0], 1);
atomic_thread_fence(memory_order_seq_cst);
atomic_store(&turn, 1);
while (atomic_load(&flag[1]) && atomic_load(&turn)==1)
;
/* Critical Section */
in_cs++;
nanosleep(&ts, NULL);
if (in_cs == 2) fprintf(stderr, "p0及p1都在critical section\n");
p0_in_cs++;
nanosleep(&ts, NULL);
in_cs--;
/* Remainder Section */
atomic_store(&flag[0], 0);
}
}
這個程式的執行將會如下,可以看到無論多少次執行這兩個 Task 進入 CS 的次數都在 1 的範圍內。
./peterson
start p0
start p1
p0: 3333, p1: 3332
p0: 6684, p1: 6684
p0: 10046, p1: 10046
p0: 13401, p1: 13400
p0: 16768, p1: 16768
atomic_sotre()隱含需要使用atomic_thread_fence()- 如果想要更高效率的 code 應該使用:
atomic_store_explicit(address, memory_order)atomic_load_explicit(address, memory_order)- memory_order 指定使用哪一種記憶體模型
- 另外要注意在
signalhandler 中不應該使用printf()這部粉可以參考系統程式設計
Peterson’s solution conclusion
- Peterson’s solution 提供一個滿足 Critical section 三個條件的純軟體演算法
- 如果 Critical section 很長,CPU 會浪費大量時間在 Busy waiting
- 例如: P0 進入 CS 後要執行約 1 分鐘,P1 會在這段時間一直在 Busy waiting,如果是這樣 P1 應該要釋放 CPU 給其他 Task 先使用,
等到時間到了再去檢查是否可以進入 CS,例如:
mutex使用 adaptive 的方式
- 例如: P0 進入 CS 後要執行約 1 分鐘,P1 會在這段時間一直在 Busy waiting,如果是這樣 P1 應該要釋放 CPU 給其他 Task 先使用,
等到時間到了再去檢查是否可以進入 CS,例如:
mutex 後面參數的
PTHREAD_MUTEX_ADAPTIVE_NP代表使用 adaptive 的方式,這樣就可以避免 busy waiting
Semaphore & Mutex
5.7 Definition of Semaphore
5.8 Mutex
5.9 Mutex in libc
5.10 Futex in Linux
這裡來介紹與 Peterson’s solution 不太一樣的機制 Mutex 與 Semaphore,最主要的差異是有可能產生 context switch,並且跟 spinlock 不同的應用場景有哪些。 實際上 Mutex 與 Semaphore 都有 spinlock, sleep, wakeup 這三個機制所實作。
The difference between Mutex and Spinlock
- Mutex lock 不成功時,幾乎都會去做 context switch
- context switch 需要去耗費一些 CPU time,所以除非要等很久否則使用 semaphore 會比較好
- Spinlock lock 不成功時,會一直做 busy waiting(Loop)
- loop 會讓 CPU 不斷嘗試進入 CS,但如果等待太久會造成 CPU 資源的浪費
等待時間長應該使用 Mutex,等待時間短應該使用 Spinlock
- Spinlock 通常效能比 Mutex 好,所以 Database 等大型軟體會使用 Spinlock
- 但如果 task 持有 lock 但被 scheduleout,會造成其他 task 一直在 busy waiting
- Semaphore, Mutex 中等待的 task 都被 scheduleout,所以不會造成 busy waiting
5.7 Definition of Semaphore
Semaphore 的定義:
- 假如現在有 P1 - P4 要進入 CS 都執行到 while(S <= 0)
- 此時持有 lock 的 task 發出 signal,S++
- P1 - P4 一定會有一個人離開 while loop,執行 S–;
- 在這裡必須假設這個步驟是一次執行完畢,所以不會有其他 task 同時離開 while loop
- 要注意這裡只是一個定義,而不是實現的方式

Semphore 的實作樣貌:
- wait: 想要進入 CS 的 task 呼叫 wait()
- value–, 如果 value < 0 就進入 list 等待
- sleep(), 呼叫 scheduler context switch
- signal: 離開 CS 的 task 呼叫 signal()
- value++, 如果 value <= 0 代表有 task 在等待
- wakeup(), 從 list 中取出一個 task 並且喚醒從 sleep() 往下執行

Semphore 的使用方式:
- Semphore 的 value 可以是:
- 0<: 代表有多個 task 在等待
- =0: 沒有 task 在等待,通常是初始化的狀態
- >0: 代表一次最多有 X 個 task 可以進入 CS
- 例如: 一次最多 3 個 task 可以進入 CS,value 的初始值就是 3,進入 3 台後 value = 0,此時下一個 task 執行 value– 就會進入 list 等待
- 通常會有一個 Struct 來管理 Semphore,value 是無法直接修改的,必須使用他設計的函數
5.8 Mutex
相較於 Semphore,Mutex 可以有更多特色
- 可以判斷是誰 Lock 住 Mutex (owner)
- 可以支援 Priority inheritance
- 可以支援或不支援 Nested lock
- 可以支援 Adaptive lock
- 假如我不知道應該使用 spinlock 還是 mutex,可以使用 adaptive lock,這樣就可以自動選擇
Adaptive Mutex
如果 p 和 q 競爭 Mutex(lock),這裡討論 p 的情況
- Mutex 沒上鎖,p 獲得 lock
- Mutex 已上鎖,q 持有 lock
- q 在另一顆 CPU,並且 q 在 OS 的 waiting queue 中,例如: q 在等待 I/O
- p 會進入 sleep 等待 mutex(context switch)
- q 既然已經進入了 waiting queue 那代表可能在這一個 epoch 內都不會再執行,那麼 p 也就不需要再去痴痴等待了
- q 在另一顆 CPU,但是 q 不在 OS 的 waiting queue 中,代表 q 在運算
- p 會進入 busy waiting,直到 q 釋放 lock
- q 因為在執行,所以代表 q 會在短時間內釋放 lock,因此 p 去 spinlock 等待或許比 ctx 更有效率
- q 和 p 在同一顆 CPU,則 p 進入 sleep 等待 mutex(context switch)
- 既然在同一顆 CPU,那麼 p 跑去做 busy waiting 也沒有意義,反而去搶奪 CPU 資源造成 q 也變慢, q 變慢代表 q 釋放 lock 的時間也會變慢,因此 p 進入 sleep 等待 mutex 會比較好
- 這裡可以藉由硬體的支援,來使用例如 pause(), mwait() 這樣的指令來讓 p 的 vcore 變慢,讓 q 有機會釋放 lock
- q 在另一顆 CPU,並且 q 在 OS 的 waiting queue 中,例如: q 在等待 I/O
以上的這些情境都代表 p 必須要知道 mutex 持有者的狀態,這樣才能決定自己要進入 sleep 還是 busy waiting
這邊介紹的 Adaptive Mutex 出自於 Sun Solaris,Adaptive 還有很多實作方式
5.9 Mutex in libc
glibc/nptl/pthread_mutex_lock.c glibc 中的 Adaptive Mutex 實作則是去依照過去等待這個 lock 所釋放的時間來設定 spinlock 的 loop 次數, 如果超過次數還無法成功,那就釋放 CPU 資源,並且進入 sleep。
- LLL_MUTEX_LOCK(mutex)
如果需要使用 Lock 的時候,如果對系統不熟悉,盡量避免隨便去使用 spinlock,可以使用 Adaptive Mutex
signal-wait-adptive-mutex.c 我們來執行這個範例程式:
- 在這個程式中使用了 semaphore 來確保 p 會比 q 先執行
- 去觀察 p 是否執行 usleep()
- 有,context switch 的次數變多,因為 q 等不到 p 釋放 lock,所以 q 會去做 context switch
- 沒有,context switch 的次數變少,因為程式很短,所以 q 會去做 busy waiting 等 p 釋放 lock

Performance counter stats for './exam3.exe':
6.45 msec task-clock # 0.598 CPUs utilized
200 context-switches # 31.027 K/sec
0 cpu-migrations # 0.000 /sec
57 page-faults # 8.843 K/sec
<not supported> cycles
0 stalled-cycles-frontend
0 stalled-cycles-backend # 0.00% backend cycles idle
<not supported> instructions
<not supported> branches
<not supported> branch-misses
0.010775604 seconds time elapsed
0.000000000 seconds user
0.010204000 seconds sys
Performance counter stats for './exam3.exe -s':
11.75 msec task-clock # 0.529 CPUs utilized
400 context-switches # 34.055 K/sec
0 cpu-migrations # 0.000 /sec
60 page-faults # 5.108 K/sec
<not supported> cycles
0 stalled-cycles-frontend
0 stalled-cycles-backend # 0.00% backend cycles idle
<not supported> instructions
<not supported> branches
<not supported> branch-misses
0.022206888 seconds time elapsed
0.000000000 seconds user
0.018481000 seconds sys
上面是去執行 perf 的結果,與預期的結果相符
Pthread mutex function
pthread_mutex_init(): Initialize mutexpthread_mutex_destroy(): Destroy mutexpthread_mutex_lock(): Lock mutex(blocking)pthread_mutex_trylock(): Lock mutex(non-blocking), if mutex is unlocked, lock it and return 0, else return EBUSY.pthread_mutex_unlock(): Unlock mutexpthread_mutexattr_(): Mutex attribute
5.10 Futex in Linux
Spinlock 可以直接在 userspace 實作,與 Kernel 無關,但想去實作 Semaphore, Mutex 就需要 Kernel 的支援,因為這兩個機制都需要去做 context switch, futex 就是 Linux kernel 提供的一個機制,可以在 userspace 實現 Semaphore, Mutex。
- futex 會透過 futex_op 來決定 mutex 的行為
long syscall(SYS_futex, uint32_t *uaddr, int futex_op, uint32_t val,
const struct timespec *timeout, /* or: uint32_t val2 */
uint32_t *uaddr2, uint32_t val3);
// Note: glibc provides no wrapper for futex(), necessitating the use of syscall(2).
注意 glibc 中並沒有去實作 futex(),因為這是一個僅限於 Linux 的系統呼叫,所以要使用 syscall() 來呼叫
syscall(SYS_futex, uaddr, FUTEX_WAIT, val, timeout, uaddr2, val3);
futex - fast user-space locking
- 以下的 Function 都只是把
int futex_op來當作 Pseudo code 來看 - Main fuctions
- futex_wait(&expected, desired, timeout)
- 等待 expected == desired,timeout 代表等待的時間,如果 timeout == NULL 代表無限期等待
- futex_wake(&val, newVal, maxWakeup)
- 把 val 設為 newVal,並且喚醒 maxWakeup 個等待該 val 變為 newVal 的 task
- futex_wait(&expected, desired, timeout)
- Priority Inheritance(優先權繼承): 這是為了避免 Priority Inversion(優先權反轉)所設計的
- futex_wait_pi(&expected, desired, timeout)
- futex_wakeup_pi(&val, newVal, maxWakeup)
- 如果正在等待的 task 中有比自己優先權高的 task,持有 lock 的 task 在持有 lock 的期間會把自己的優先權提升到跟等待的 task 同等
- Unlock 後優先權最高的 task 會優先取得 lock
Priority Inversion 是指低優先權的 task 持有 lock,但是高優先權的 task 此時也想持有 lock,導致高優先權的 task 等待低優先權的 task 釋放 lock
Use Semaphore to Solve Common Problems
5.11 Producer-Consumer Problem
5.12 Readers-Writers Problem
5.13 Dining Philosophers Problem
5.14 What is the correct
5.11 Producer-Consumer Problem
- 比較簡單的情況是「一個 Producer」、「一個 Consumer」
- 這種情況下使用 atomic_write, atomic_read 來創造一個 out, in 的 Circular queue 來解決
- 「多個 Producer」、「多個 Consumer」,例如: 多個 Produer 同時要修改 in
- 如果有 read + modify(compare) + write 可以用一個硬體指令來解決,是否是比較有效率的方式?
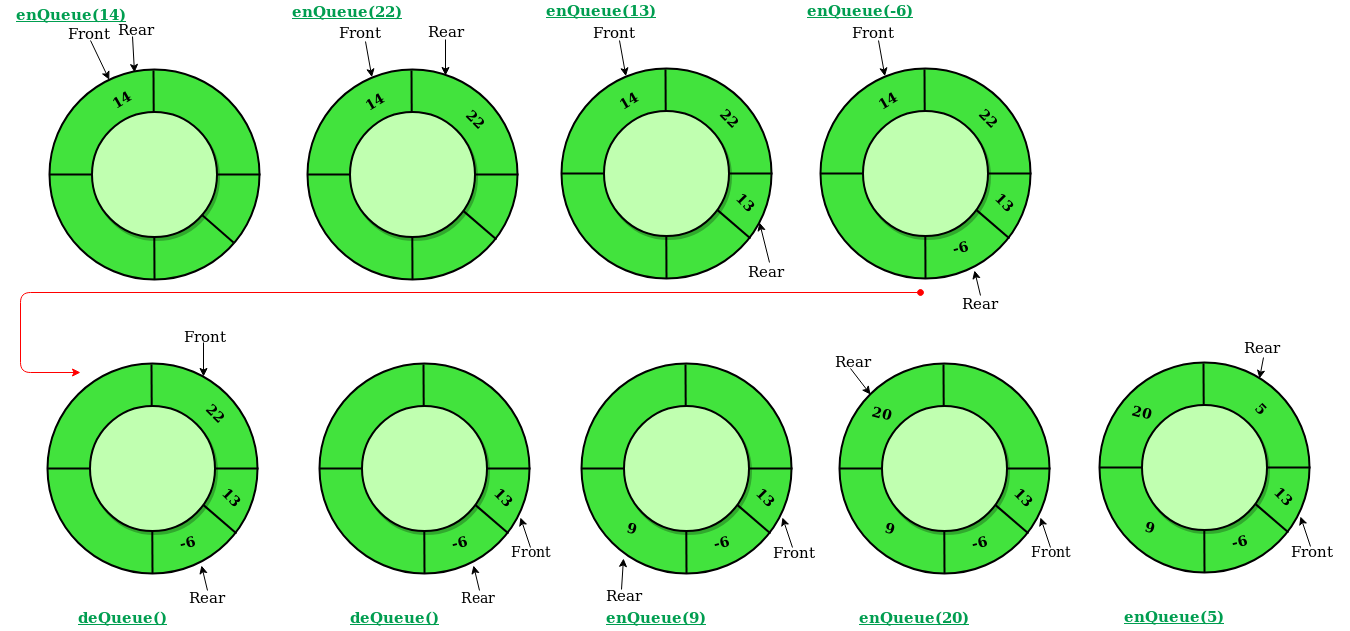
上圖是 Circular queue 的概念,這裡的 in, out 代表的是 index,而不是實際的資料
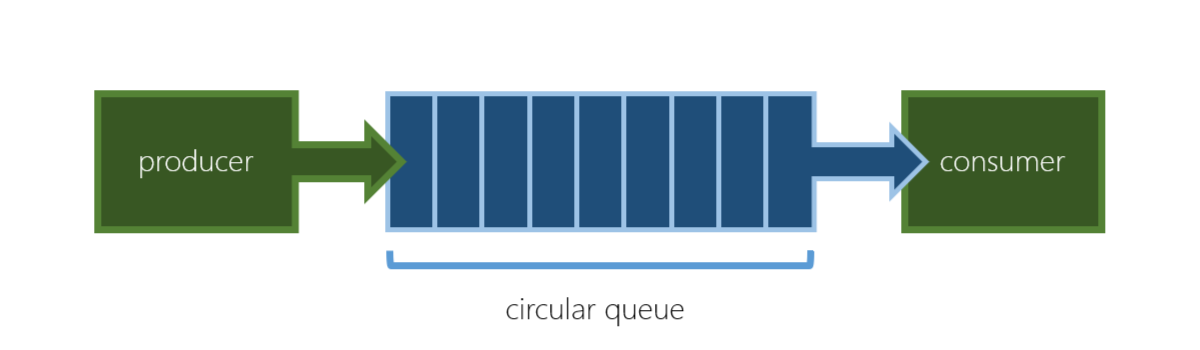
以上是一個範例,假設 Producer 是 NIC,Consumer 是 OS
- Queue 儲存的可能是一個 pointer,指向儲存資料的記憶體
- NIC 透過 DMA 把資料寫入記憶體,並且修改 in
- OS 取完資料後,修改 out
- 假如此時是一對一的情況,解決方法如下,注意這裡其實應該要使用 atomic 來實作:
- Producer 會執行 insert() 寫入資料
insert() { while (true) { item = input(); /* Produce an item */ while (((in + 1) % BUFFER_SIZE) == out) /* Only read in and out */ ; /* Busy waiting, because no free buffer */ buffer[in] = item; /* Insert item */ in = (in + 1) % BUFFER_SIZE; /* Update in */ } } - Consumer 會執行 remove() 讀取資料
remove() { while (true) { while (in == out) /* Only read in and out */ ; /* Busy waiting, because no free buffer */ item = buffer[out]; /* Remove item */ out = (out + 1) % BUFFER_SIZE; /* Update out */ output(item); /* Consume the item */ } } - 在這個例子裡面 in, out 都只有一個 task 會去修改,所以只要使用 atomic_write, atomic_read 就可以解決
- Producer 會執行 insert() 寫入資料
要注意上面的例子都使用了 Busy waiting,如果程式並沒有高速的讀寫,那麼這樣的做法會造成 CPU 資源的浪費
5.12 Readers-Writers Problem
- Reader-Writer Problem 的定義如下:
- Reader 只可以讀,Writer 可以讀也可以寫
- Reader 可以同時多個 Reader 一起讀同一個資料結構
- Writer 同一時間內只能有一個去存取資料結構
- 實作上我們假設有一系列的 Writer, Reader 進入排序準備進入 CS:
rrrwrr- 把
rrrwrr轉換成rrrrrw優先處理 Reader- 但這樣的問題是,假如同一時間內不斷有 r 進入,那麼 w 就會一直等待,必須設計一個機制處理 w
rrrwrr,r跟 w 之間必須 FIFO,但連續的 r 可以同時進入 CS- 所以執行順序會變成
rrr->w->rr
- 所以執行順序會變成
- 把
- 這裡的目標是盡量提高平行度,讓多個 Reader 同時進入 CS

假如有以上範例程式:
- writer 只需要去 wait(rw_mutex) 也就是 lock,跟 signal(rw_mutex) 也就是 unlock 就可以
- reader:
- 最開頭的 wait(mutex) 到 signal(mutex) 是為了 lock CS 讓此時只有 reader 可以進入
- readcount == 1 代表這是第一個 reader,所以要去 lock CS 不讓 writer 進入
- 離開要檢查 readcount == 0 代表最後一個離開的 reader,unlock 讓 writer 此時可以進入
- 最開頭的 wait(mutex) 到 signal(mutex) 是為了 lock CS 讓此時只有 reader 可以進入
- 假設現在有一個 writer 正在 CS 中,此時有 r0, r1, r2 要進入 CS
- r0 會先進入 wait(rw_mutex),此時 writer 正在 CS 中,所以 r0 會進入 sleep
- r1, r2 會進入 wait(mutex),lock 被 r0 拿走,所以 r1, r2 會進入 sleep
- writer 離開 CS 並且 signal(rw_mutex),此時 r0 會 singal(mutex),讓 r1, r2 可以依序進入 Reading
在實際使用時,可以使用 pthread 內建的 rwlock
5.13 Dining Philosophers Problem
如下圖所示,一群哲學家坐在圓桌上,每個哲學家面前都有一個盤子,而盤子之間交錯著刀叉
- 哲學家吃飯時必須拿起左右兩邊的刀叉才能吃飯
- 有什麼方法讓所有的哲學家都能吃到飯?
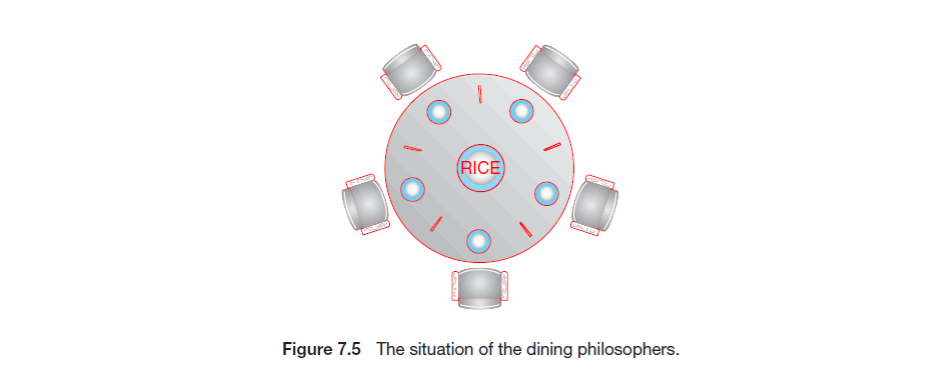
可能的解決方法:
- 所有人都先拿左邊的餐具,再拿右邊的餐具
- 可能所有人都拿到左邊的餐具,都等不到右邊的餐具,造成死結
- 對所有人編號,奇數先拿左邊的餐具,偶數先拿右邊的餐具
- 有可能有人運氣很差,一直拿不到餐具,不符合 Bound waiting
- 輪流獲得高優先權,拿到餐具的人可以吃飯然後放下餐具,直到所有人都吃完
- 輪流獲得高優先權,可能會造成效能瓶頸
The Dining Philosophers Problem in Linux Kernel
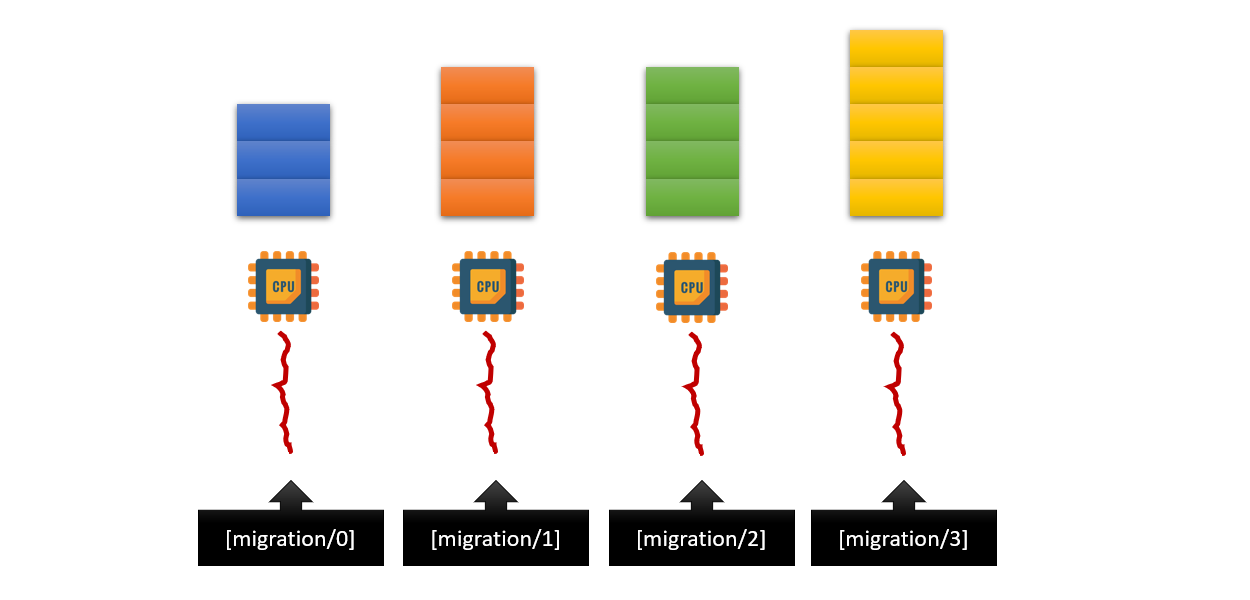
- 每顆 CPU 上都有一個 migration thread,當 CPU 有空閒時,migration thread 會去檢查有沒有 task 想要執行
- pull: migration/0 發現我的工作量太少,所以去搬移 migration/3 的工作
- push: migration/3 發現我的工作量太多,所以把工作搬移給 migration/0
- 此時就要避免 migration/0, migration/3 重複了搬移工作,例如:
- 依照 CPU 編號,優先鎖編號小的 CPU,這樣就只有一個 migration thread 會先執行
- 搬移結束後此時工作量會平均,所以不會再有 migration thread 去搬移工作
在這個例子 Linux 並沒有去考慮 bound waiting,因為 0 成功了的話 1 也就不用執行了
5.14 What is the correct
當多個 Process 同時在執行,在修改的時候要怎麼去確保資料的正確性,什麼是正確的?
假如有 Task1, Task2 同時要修改一個資料 A
- Task2 先讀取 A,然後以 A 為基礎做一些運算
- Task1 在 Task 讀取後,才讀取 A 並修改 A,然後 Task2 才結束運算
- 這樣的情況下 Task2 最後運算的結果是錯誤的,因為 Task2 以 A 為基礎做運算,但是 A 已經被 Task1 修改了
同樣兩個 Task,但是這次 Task2 在 Task1 讀取前就做完運算
- 但是實際上這兩次 Task2 最後的結果都是一樣的
- 因此如果以 Task2 的結果來判斷正確性,那麼可以說這兩次情景是等價的

是否可以把平行化以後的正確性定義為「其結果等價於某個依序執行的狀況」
Atomic Operation
前面會先介紹 Computer Orangization 的一些基礎,後面介紹使用 Atomic Operation 所產生的成本
5.15 Mesh-Architecture
5.16 DMA with Cache Coherence
5.17 Cache coherence vs Atomic operation
5.18 Atomic operation
5.19 Atomic operation in c11
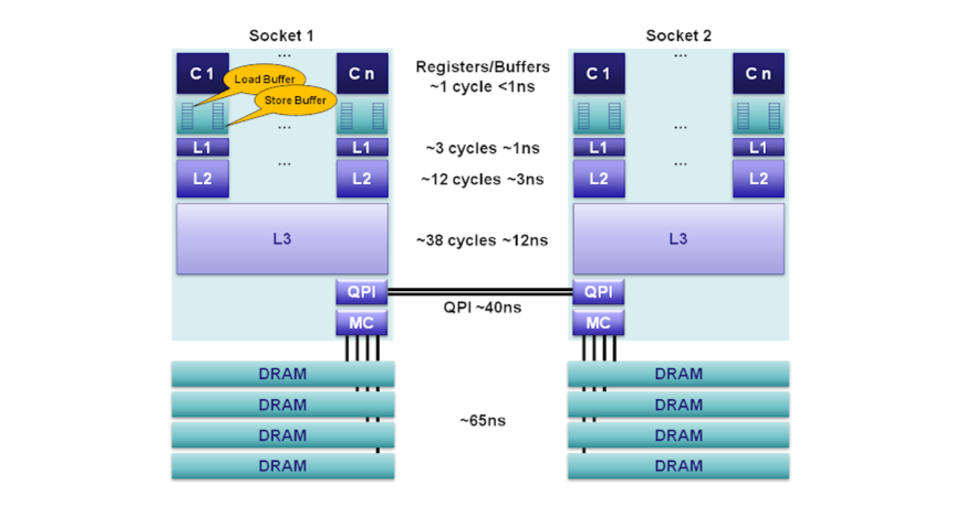
使用 Atomic operation 所產生的成本跟一般的指令不太一樣,並且會依照受影響的 CPU 的個數而有所不同。並且在 SMP 上如果所有 CPU 每次存取資料都要到 DRAM, 那 DRAM 就會是一個 Bottleneck,所以會有 Cache 的機制,但是 Cache 就要去處理 Cache coherence 的問題。
在同步機制上,不同的指令會影響到的 CPU 數量不同,所以成本也不同
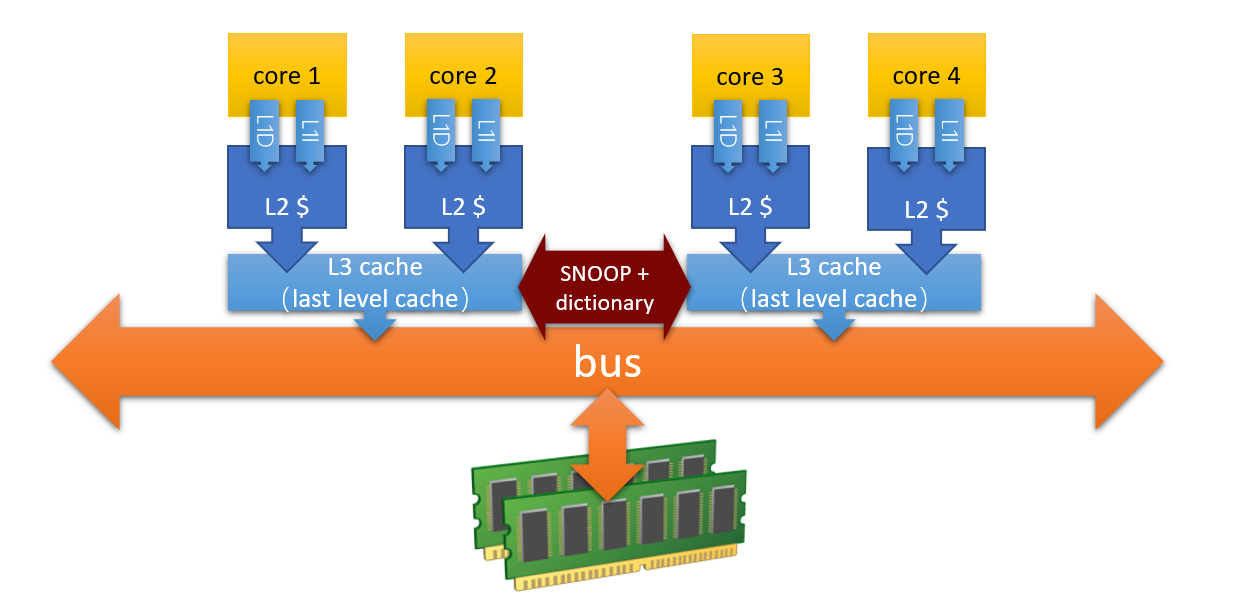
上圖中 L2 cache 之間會有一些同步機制,而 L3 chache 也會有一些同步機制,例如: SNOOP + dictionary
Bus Bus 也有各種各樣的類型
5.15 Mesh-Architecture
這裡以 Intel® Xeon® Processor Scalable Family Technical Overview 為例,來了解 Coherence 的代價
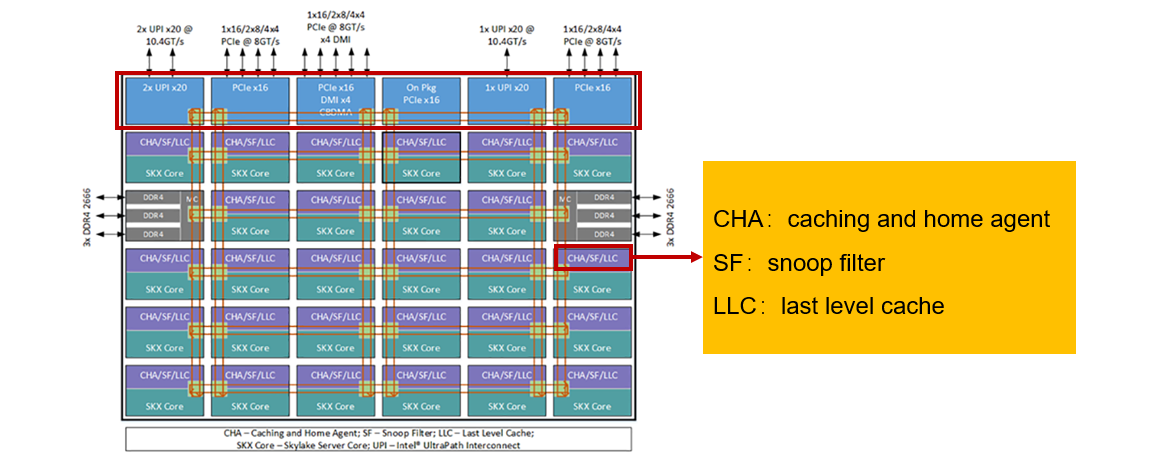
- Core 傳遞資料的方式是透過 Mesh,先走 X 再走 Y
- CHA(Cache Home Agent): 類似 directory,記錄資料在那些 Core
- SF(Snoop Filter): 監聽 Bus 上的廣播,是否與自己有關
- LLC(Last Level Cache): 最後一層的 Cache
- 最上層就是對外的通訊介面,例如: PCIe, UPI
- 左右各有一個通道,用來連接 DDR4,所以左右的 Core 會優先使用自己側的 DDR4
Ultra Path Interconnect(UPI)
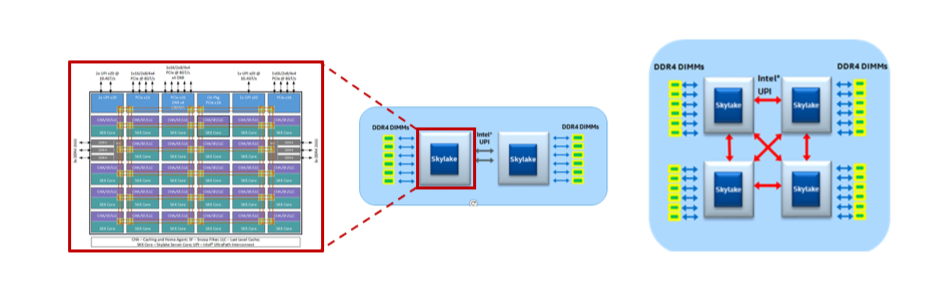
- UPI 是一種擴展系統的一致性協定,讓多個處理器可以共享資料,並且在同一個 Memory space
- 支援 UPI 的 Intel Xeon 處理器會提供 2~3 個 UPI 通道,來連接到其他 Xeon 處理器
- UPI 之間使用 Directory-based home snoop coherency protocol 來維持一致性
Cache Coherence
CPU 必須用一些方法保證所有的 Core 看到的資料都是一致的,否則 Shared Memory 就沒有意義
- Cache coherence problem: 不同 CPU 有不同的 Cache,所以可能會有新舊資料的問題
- Cache coherence protocol: 一種機制,用來確保所有 CPU 看到的資料都是一致的
- Snooping: 以廣播的方式來維持一致性,修改資料時會通知其他 CPU
- Directiory: 在每個 Cache line 上都有一個 Directory,紀錄最新的資料在那些 Cache,這樣就只需要通知有關的 CPU
- 但是如果核心數多起來,Directory 會變得很大,所以會有一些機制來減少 Directory 的大小,例如: Group,把一些 Core 分組, 這樣就不用紀錄所有的 Core,通知 Group 就可以了
- 目前通常會使用 Snooping + Directory 的做法
對 OS 來說這些方法不重要,重點是 CPU 保證所有的 Core 最終看到的資料都是一致的。
如果要保證所有的 Core 在 LLC 看到的資料都是一致的,他的成本會很高,因此現在許多的 CPU 僅僅保證「部分指令」對於記憶體系統的存取是 Atomic operation
5.16 DMA with Cache Coherence
能夠去修改記憶體的裝置有 CPU 還有周邊的 Device,例如: NIC, GPU
之前談的 Cache coherence 都是針對 CPU,但是實際上有去修改 Memory 的裝置都應該要去考慮同步的問題,因為 DMA 通常比較慢的原因, 因此要確保 DMA 搬移到 Memory 後,CPU 也能看到最新的資料,有軟硬體的方式可以來做到。因為是 OS 的課程,所以這裡要討論的是對於我們寫程式會有什麼影響。
- 以軟體的方式來做的話
- Linux 中 CPU 把資料寫入到 DMA 會搬移的資料時,會讓 Cache 的資料 flush 到 DRAM,確保 Device 拿到的資料是最新的
- DMA 寫入 DRAM 後,CPU 要取這筆資料時會去把 Cache 的資料清除,並且重新從 DRAM 讀取,確保 CPU 拿到的資料是最新的
- 以硬體來說,要寫入時可以去找尋最新資料的位置在哪
- 在 DRAM: 就直接寫入 DRAM 更新資料
- 在 Cache:
- 硬體去主動把 Cache 的資料取消
- 直接寫入 Cache
5.17 Cache coherence vs Atomic operation
從 Linux Kernel 5.4 之後支援 C11 的 atomic,在 5.4 之前的版本,Linux Kernel 會使用自己的 atomic
這裡要提出一個疑問,如果已經有 cache coherence 的機制,那為什麼還需要 atomic operation?
假如有以下的情況可能發生:
- 如果某個瞬間,兩個 core 同時對一個變數做了修改,其他 core 是否會看到同步中間的狀態,例如: alignment
- alignment: 可能一次修改要更新兩條 cache line,此時有可能看到只更新一半的狀態
- 非常多核心的處理器中,不能保證一個 core 做出修改後會不會有傳遞的延遲
- core1 修改 A,但還沒傳遞到 core2 的時候 core2 又修改了 A
- core 數量越多,資料交換的頻寬就越是效能瓶頸
- write buffer, read buffer: 在進行操作時有沒有可能造成 write, read 沒有按照順序執行,例如: 有 cache miss 所以先執行的 write task 被 context switch
- 這裡要牽涉到的是 Memory order 的問題,因為在 write buffer, read buffer 中是沒有 cache coherence 演算法的,必須要確定順序才能保證正確性
- 如果要嚴格執行順序的話,要在這些操作之間插入 mfence
可能的解決方法:
- 讓所有對記憶體的操作都是 atomic 的,此時去 lock bus,讓其他 core 無法存取記憶體,直到這個 core 完成操作
- 在一個實際的運算中可能每 3-4 個指令就會有 load, store,這樣的話等於要頻繁的去 lock bus 不太現實
- 部分指令對於一個記憶體區間內是 atomically,這樣會比較好設計
- 軟體與硬體工程師設計好哪些指令去解決問題
Kaby Lake - Microarchitecture Intel
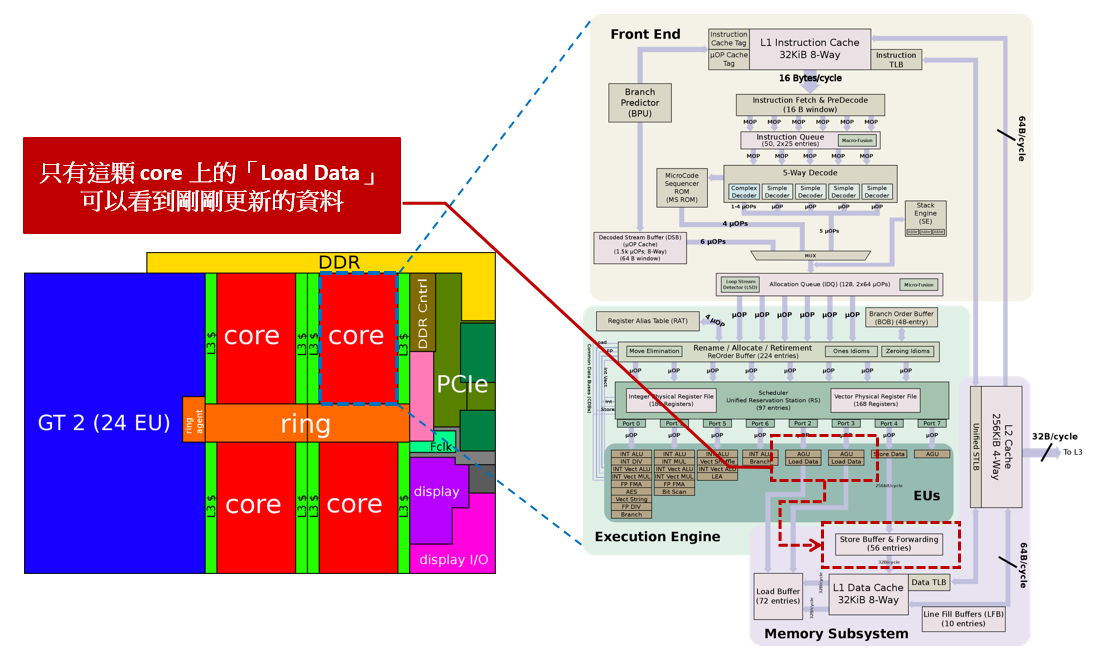
Load buffer & Store buffer in x86
5.18 Atomic operation
因為想要使所有的 load, store 都是 atomic 實在太難設計,因此只保證部分指令是 atomic
- 傳統上會有 test_n_set, swap 這樣的 Assembly
- test_n_set: 回傳舊的值,並且把新的值寫入,swap: 交換兩個值
- 這兩個程式相當於以下 c 程式,register 相當於 CPU 內部真實的暫存器
int test_n_set(int *value) {
register tmp = value;
*value = 1; /* Update memory */
return tmp;
}
void swap (int *a, int *b) {
register tmp;
tmp = *a;
*a = *b; /* Update memory */
*b = tmp; /* Update memory */
}
while(test_n_set(&lock))- 一個簡單的 spinlock 這樣實作,但是他會不斷去更新 value,觸發 cache coherence
- 另外這兩個指令都是 read-modify-write,會讓 cache coherence 變得沒有效率
bool atomic_compare_exchange_strong (volatile atomic_int* obj, int* expected, int desired )是改進的方式- 如果 obj 等於 expected,那麼就會更新 obj 並且回傳 true
- 如果 obj 不等於 expected,那麼就會把 obj 的值更新到 expected,並且回傳 false
bool atomic_compare_exchange_strong (volatile atomic_int* obj, int* expected, int desired );{
if (obj == expected) {
/* Only obj equals expected to lock and write obj */
obj = desired; return true;
} else {
expected = obj; return false; /* Only read obj */
}
}
- 這樣的寫法不會去不斷更新 value,因此也只會觸發一次 write 造成 cache coherence
- 但是這裡並沒有保證誰會先發現 obj == expected,這部分要軟體去設計
5.19 Atomic operation in c11
c11 提供了一個類似 test_n_set 的支援,把 obj 與 desired swap,並且回傳舊的值
int atomic_exchange(atomict_int *obj, int desired) {
register tmp = *obj;
*obj = desired;
return tmp;
}
同樣也有 atomic_compare_exchange_n,的支援,對於 strong, weak 的差別:
- 在 x86 平台上的時候,strong, weak 沒有差別,因為 x86 會保證誰先發現 obj == expected
- strong: 保證一定會更新 obj,只有在 obj != expected 時才會回傳 false
- weak: 不保證一定會更新 obj,有可能因為平台造成 obj == expected 時回傳 false
- 此時可以使用 while loop 來包裝使用 weak,直到成功為止
應用上如果只需要執行一次,那就使用 strong,如果需要重複執行,那就使用 weak
例如說一個 Initialize 的操作,只需要執行一次並且不會重置 initialized 為 0,所以只有一個 process 會成功
void initialize_once() {
if (atomic_compare_exchange_strong(&initialized, &expected, 1)) {
/* If this line is executed, the process is the first to successfully initialize */
resource = 100;
}
/* Resource was already initialized by another process */
}
一個簡單的範例,在於如何實現多個 thread 對於同一個變數做 +1 的操作,compare-exchange-spinlock.c
void* Counter() {
int expected;
for (int i = 0; i < 10000000; ++i) {
do {
expected = counter;
} while (!atomic_compare_exchange_weak(&counter, &expected, expected + 1));
}
}
上面會在每次 while 之前都去先把 expected 更新成 counter,然後去比較 counter == expected,如果是的話就更新 counter,並且回傳 true,否則回傳 false
Spinlock
5.20 Spinlock Concept and Advanced
5.20 Spinlock Concept and Advanced
- Spinlock 的設技巧:
- 「檢查 -> 鎖住」這樣的方法是不對的,在檢查和進入之間有其他 task 做「檢查」,導致多個 task 同時進入
- 「鎖住 -> 檢查 -> 進入」:
- 「鎖住」的目的是先讓別人進不去,再去檢查能否進入
- 如果改變完發現不能進入,那就把「鎖住」的狀態改回來
- 「檢查和鎖住」用同一個 atomic operation,例如:
- swap, test_n_set (效率最差)
- compare_exchange_weak, compare_exchange_strong (比較好,但效率還是不好)
5.21 lockfreeQueue.c
如果使用 Lock-free 的方式會比使用 Semaphore 快上數倍,但程式的複雜度也會提高
volatile int in = 0, out = 0;
void put() {
static int item=1; /* Using to debug, Ensure that the numbers are an increasing sequence */
while ((in+1)%bufsize == out) ; /* busy waiting */
buffer[in]=item++; /* put item into buffer */
/* A memory fence should be added here to ensure that get() reads the data after item++ */
in = (in + 1)%bufsize; /* The next position to put */
}
void get() {
int tmpItem; /* temporary variable to store the item */
while (in == out) ; /* busy waiting */
tmpItem=buffer[out]; /* get item from buffer */
out = (out + 1)%bufsize; /* The next position to get */
}
Last Edit
12-08-2023 16:03