OS | CPU Scheduler
Operating System: Design and Implementation course notes from CCU, lecturer Shiwu-Lo.
本章節會主要介紹 Linux Scheduler,Linux Scheduler 現在的的目標是: 如何從「好變為更好」
- Noun, Concept definition
- 2.4 Scheduler
- 2.6 O(1) Scheduler
- 2.6 - 5.3 Complete fair scheduler(CFS)
Linux Kernel 2.4 是一個非常長壽的版本,持續了大約 10 年左右,但即便這樣一個這麼長壽、穩定的 Scheduler, Linux Kernel 設計者仍然在考慮如何讓她變得更好。
Noun, Concept definition
4.1 Task
4.2 Scheduler Types
4.3 Cooperative multitasking - Novell-Netware
4.4 Preemptable OS
4.5 Scheduler & Context switch
4.6 Scheduling Criteria
4.1 Task
- 在 Linux 中,Process 和 Thread 都是 Task
- Process 之間不會共用任何資源,尤其是 Memory
- Thread 則是幾乎共用所有資源,尤其是 Memory
- Task 的生命週期中分為兩種情況
- Using CPU
- Waiting,例如: Waiting mutex, I/O …
- Task 在使用 CPU 時分為: 執行於 User mode/Kernel mode
在 Linux Task 可以執行在 User/Kernel mode,改變模式稱作 Mode change,而 Kernel Thread 專指只有 Kernel mode 的 Task,例如: Device Driver
Task & Scheduling
以下是一個 Task 的生命週期,這裡從 Scheduler 角度來看的話主要影響的是兩個部分:
- Waining(semaphore): 怎麼在 Waiting 時,讓 Task 的使用率最大化
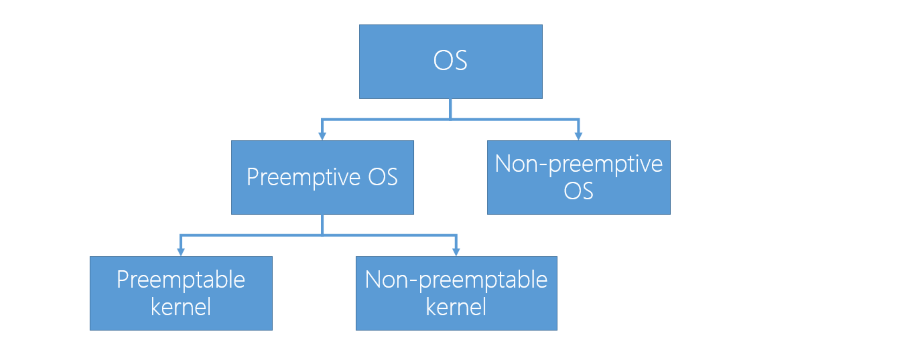
- OS 可以分成兩大類:
- Cooperative multitasking(Non-preemptive, 協同運作式多工)
- Preemptable OS(Preemptive, 搶占式多任務處理)
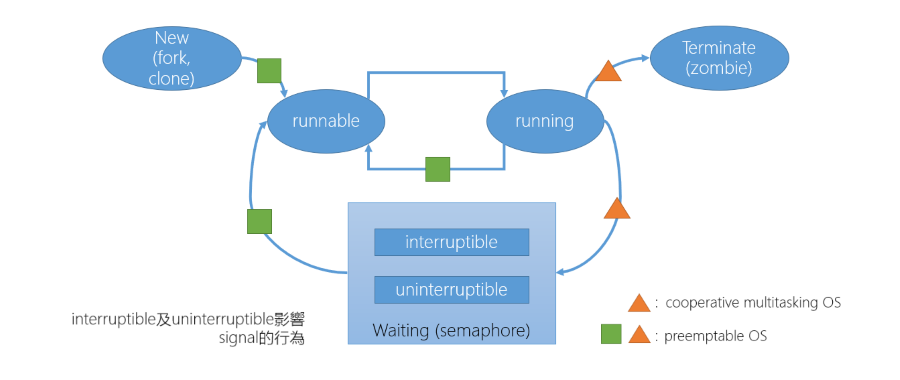
4.2 Scheduler Types
- Non-preemptive OS(△): 就是指只有 Task 自己放棄 CPU 使用權,才會交出 CPU 使用權
- Task 執行結束,這樣當然就交出 CPU 使用權
- Task 發出 Blocking I/O request 因為要等待 I/O 完成,因此也會交出 CPU 使用權
- 當然也有 Async I/O,Vectored I/O 等方法,這裡先不討論
- Preemptive OS(☐△):
- 每個 Task 會有一個 Time slice 執行,例如: 1/1000 Sec,執行結束就要做切換
- 從 Wating 等待完畢 I/O 後,返回 Runtable 時要不要馬上切回該 Task
- 新的 Task 也可以給予高優先權,讓他馬上執行
- Preemptive OS 又分為:
- Preemptable Kernel, Non-preemptable Kernel
4.3 Cooperative multitasking - Novell-Netware
- Netware 所有的程式都在 ring 0 執行,但是這樣就要確保所有的程式都是由 Novell 來控制, 這樣才能確保所有的程式都是可信任的,沒有惡意程式
- 但是當 CPU 效能變強之後,這樣的設計就不太好,因為所有的程式都要由 Novell 來提供,這不太可能,因此最後由 Windows NT 勝出
4.4 Preemptable OS
Preemptive OS:
- 如果一個 Task 執行過久,OS 會主動將 CPU 控制權交給下一個 Task
- 如果要設計 Preemptive OS 必須要有 Hardware support,例如: Timer, Interrupt
- Timer: 用來計算 Task 執行的時間
- Interrupt: 使 OS 能獲得 CPU 控制權
- 所有版本的 Linux 都是 Preemptive OS
Preemptive Kernel
- Non-preemptive Kernel(throughput):
- 在 2.6 Kernel 之前,Linux 是 Non-preemptable Kernel
- 當 Task 執行在 Kernel mode 時,其優先權無限大
- Context switch 只會發生在 Task 由 Kernel mode 切換到 User mode 時
- Preemptive Kernel(latency):
- 在 2.6 Kernel 之後,Linux 可以設定為 Preemptable Kernel
- 當 Task 執行在 Kernel mode 時如果沒有任何的 Lock 就可能發生 Context switch
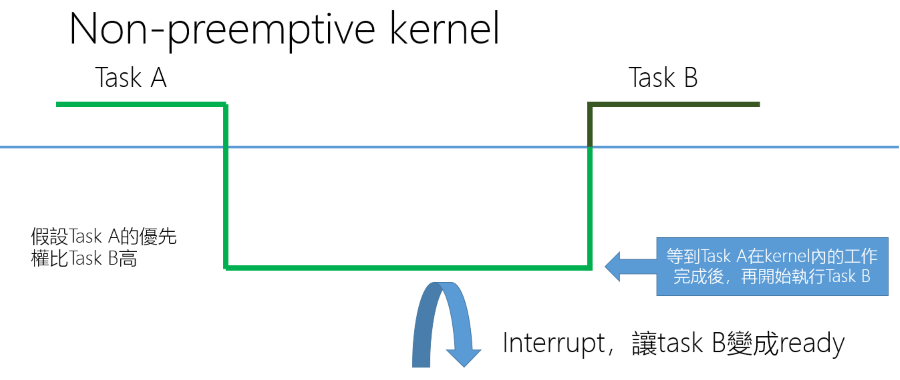
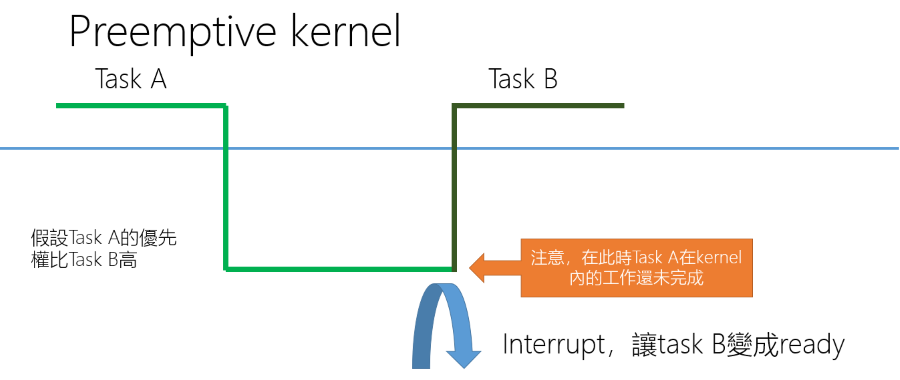
注意如果在 Kernel 中發生 Interrupt,下次 Task A 執行時會直接從 Kernel mode 中繼續執行, 因此在 2.6 Kernel 後編譯時可以選擇 Kernel 注重 throughput 還是 latency,
Form Non-preemprive kernel to Preemprive kernel
- 在 Non-Preemprive kernel 中,所有進入 Kernel 的 Task 可以假設自己不會被 Preempt,因此存取很多共用資料,不需要使用 Lock
- 在 Preemprive kernel 中,程式設計師需要仔細思考、改寫程式碼,所有存取到共用資料的程式碼都需要使用 Lock-UnLock 來保護
- 這是一件非常耗費人力的工作
4.5 Scheduler & Context switch
- Scheduler 決定接下來要執行哪一個 Task
- 使用 C language 撰寫
- Context switch
- 負責從一個 Task 切換到另一個 Task
- 主要切換的是普通 Register
- 如果 Task 使用到一些特別的 Register,例如: 浮點數運算器(Floating Point Unit, FPU),則需要額外處理(Lazy)
- Lazy: 只有新的 Task 需要使用到 FPU 時,才會切換 FPU 相關的 Register
- Context switch 隱含的切換
- 依照需求切換 Page Table(TLB)
- 切換 Cache 的內容
4.6 Scheduling Criteria
這裡介紹如何分析一個 Scheduler 的好壞
- CPU Utilization(使用率): CPU 維持在高使用率,Task 之間互相有等待的關係,要如何 Schedule?
- Throughput(吞吐量): 在單位時間內,CPU 可以執行多少 Task
- 例如: 讓 I/O Task 優先執行
- Turnaround time(往返時間): Task 從開始到結束的時間,與 Scheduler 及程式本身的執行程度相關
- Waiting time(等待時間): Task 在 Ready Queue 中等待的時間,通常高優先權的 Task 會等待較短的時間
- 只要一個 Task 能執行,但 OS 使其等待就要算入 Waiting time
- Response time(回應時間): Task 從發出 Request 到第一次回應的時間
- 例如: 程式需要輸出回應到螢幕,好的 Scheduler 可以讓 Progress bar 非常即時的反應
CPU Utilization
實際的 CPU 使用率會受到 Task 的高低優先權影響,因此 CPU 使用率會有兩種情況:
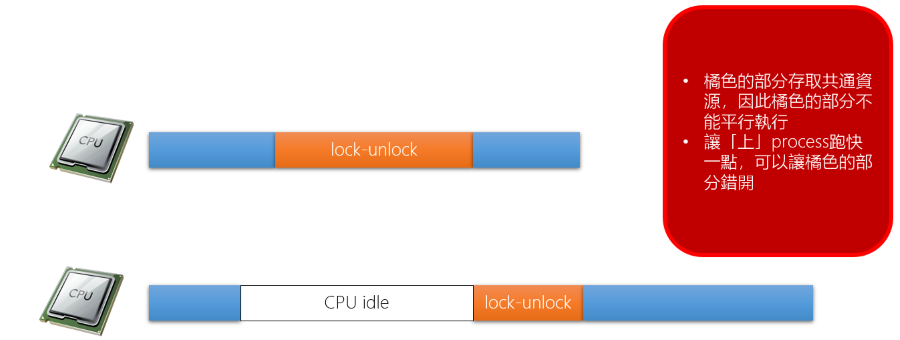
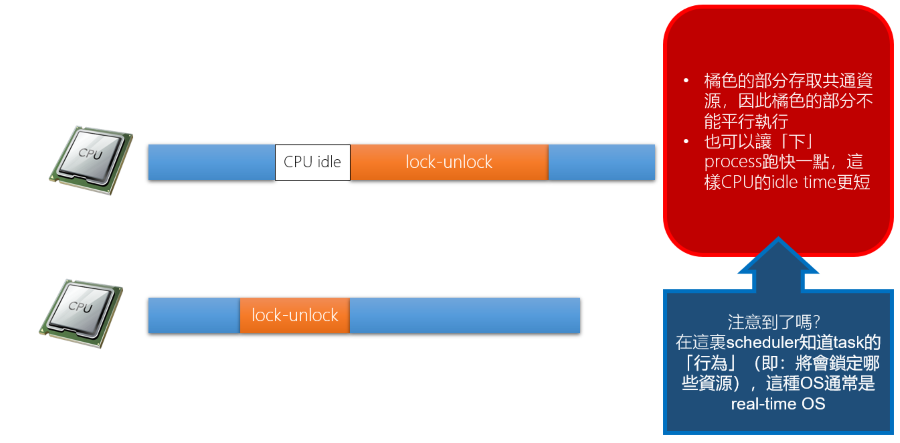
可以透過軟體的方式對 Lock-Unlock 做最佳化,例如: Intel vtune, kernelshark 之類的視覺化工具
Response time
假如系統中有 10 個 Task,這 10 個 Task 連接到 10 個 User,如果要讓執行感覺流暢的話,有以下做法:
- 單向互動:
- 假如 Task 是播放影片,那就安排適當的 Buffer,解碼後的影片放入 Buffer 供 User task 拿取
- 只要 Buffer 夠大,即使每 10 秒才輪到一次執行,使用者也不會覺得 Lag
- 雙向互動:
- 假如 Task 是語音通話,必須在 150ms 中輪到執行一次,否則會覺得通話品質不好
- 那每個 Task 一回合只能執行 15ms
Scheduler Concepts
4.7 Simple Scheduler
- FCFS(Fisrt Come First Serve)
- 依照 Task 的抵達順序,依照順序執行
- SJF(Shortest Job First)
- 依照 Task 的執行時間,執行時間短的 Task 優先執行
- RR(Round Robin)
- 在一群 Task 中輪流執行,每一個 Task 最多執行 X 個 Time slice
在 Linux 中可以看到上面三種方法的影子
FCFS
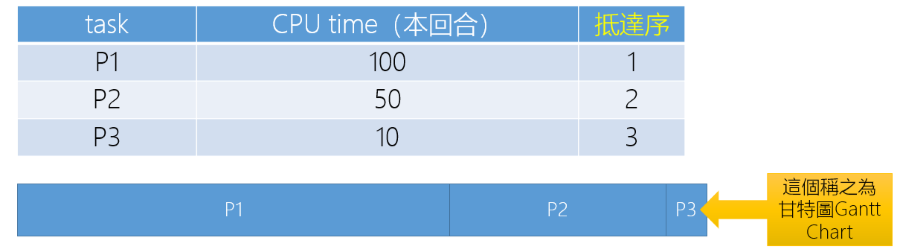
- Wating time: P1 = 0, P2 = 100, P3 = 150
- Average waiting time: (0 + 100 + 150) / 3 = 83.3
- 如果先抵達的 Task 執行時間很長,Average waiting time 就會變得比較長
SJF
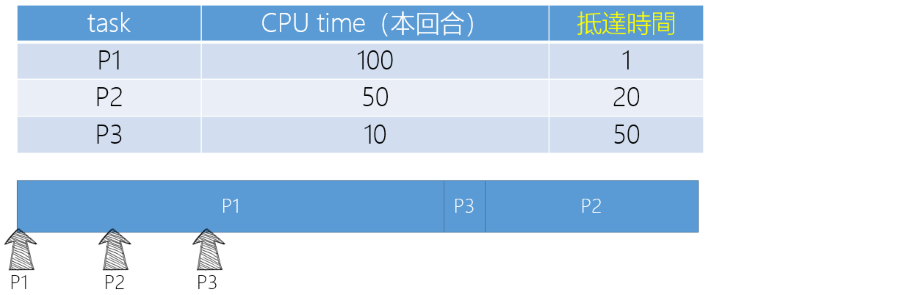
- 在 P1 執行中,P2、P3 抵達,放入 Ready Queue,然後依照執行時間排序
- Wating time: P1 = 0, P2 = 110, P3 = 100
- Average waiting time: (0 + 110 + 100) / 3 = 70
Preemptive SJF
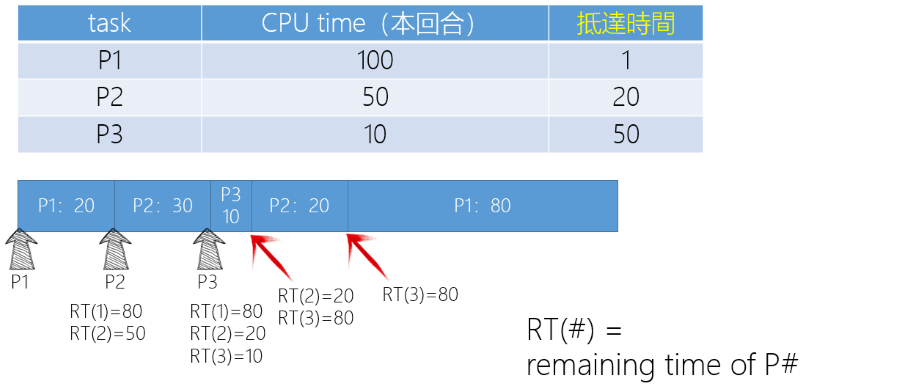
- 只要有工作進入 Ready Queue,或有工作結束就要決定執行的 Task
- Wating time: P1 = 60, P2 = 10, P3 = 0
- Average waiting time: (60 + 10 + 0) / 3 = 23.3
直觀上會覺得 Preemptive SJF 是比較好的演算法,但注意 Preemptive SJF 有 Context switch overhead
- 如果只是寫 SJF 通常指 Non-preemptive SJF
- Preemptive SJF 又稱作 SRTF(Shortest Remaining Time First)
- 在 Average waiting time 方面,SJF & SRTF 分別是 Preemptable scheduling & Non-preemptable scheduling 的最佳演算法
Estimate Execution Time
前面提到的 Scheduler 都是假設 Task 的執行時間是已知的,但實際上 Task 的執行時間是不知道的,因此需要估計 Task 的執行時間
- 一個 Task 的生命週期分為兩種情況
- Using CPU, Waiting
- 依照 Task 以前使用 CPU 使用時間的多寡,來預測這次使用 CPU 時間的多寡,例如以下公式
- tn: 上一次的 CPU time
- 𝜏x: 預測的第 x 次的 CPU time
- Linux Kernel 2.4 使用以下的方法,並且 𝛼 取 1/2 因為可以避免浮點數運算
- tn+1 = 𝛼 * tn + (1 - 𝛼) * 𝜏n
- 𝛼 是一個權重因子界於 0 ~ 1 之間
- 越靠近 1,表示越重視過去的 CPU time
- 越靠近 0,表示越重視預測的 CPU time
Round Robin
如果使用 RR 那麼 Time slice 要設定為多少?
- 太長: 會讓 Task 等待的時間變長
- 太短: 會讓 Context switch overhead 變大
- 通常 Time slice 會設定為一個 Task 可以在 Time slice 內執行完畢,變成 Waiting 狀態
- 也就是在 Time slice 中成功把 I/O request 發出去
目前 Linux 的設定為使用者需要多少的 Time slice,可以動態的調整 Time slice 的大小
Linux Scheduler
4.8 Linux 2.4 Scheduler
4.9 Linux 2.6 Scheduler
- Linux 共有 140 個優先權等級
- 0 ~ 99: Real-time priority
- 通常是一些需要 Real-time 的 Task,例如: 影片播放,聲音播放
- 100 ~ 139: Normal priority
- 對使用者而言是 -20 ~ +19,預設值為 0,稱作 Nice value
- 0 ~ 99: Real-time priority
- Nice value 是由 User 指定,Linux 當作參考用以計算 Dynamic priority,Dynamic priority 會因以下因素影響:
- 該 Task 是 I/O bound 還是 CPU bound
- 考慮 Core 的特性
- 考慮 Multi-thread 的特性
使用者在啟動 Task 時可以指定 Nice value,或在 Task 執行時使用 renice 指令來調整 Nice value
4.8 Linux 2.4 Scheduler
- 在 2.4 Scheduler 中如何對 I/O 進行優化
- 思考在 2.4 在 Multi-processor 的環境下欠缺什麼?
- Non-preemptible kernel
- Set p->need_resched if schedule() should be invoked at the ‘next opportunity’(kernel -> user mode).
- 所以一個正在 Kernel 中運行的 Task 要進行 Context switch 時就會將 need_resched 設為 1
- Round-Robin
- task_struct->counter: number of clock ticks left to run in this scheduling slice, decremented by a timer.
- 這是一個 Task 執行的 counter,每個 time tick 就 -1,用完了就不能在這個回合內使用 CPU
2.4 Scheduler - SMP:
當有 CPU 進入 Idle 時,2.4 Scheduler 會從 Ready Queue 中 Search & Estimate,找出最佳的 Task 來執行
- Search: 會依照這個 Task 對這個 CPU 有多適合

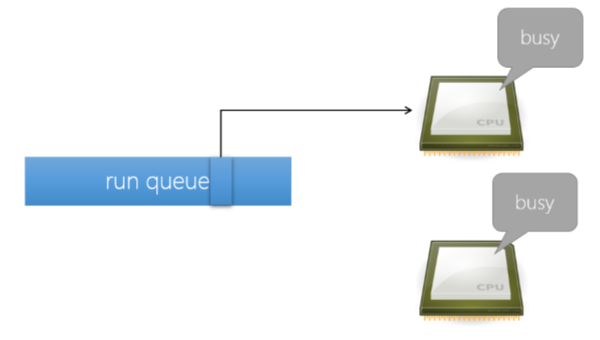
2.4 Scheduler - Run-Queue:
在 2.4 中所有人都是使用同一個 Run-Queue:
- Use spin_lock_irq() to lock “runqueue_lock”
- 因為 2.4 Scheduler 僅有一個 Run-Queue,要在運算時 Lock 然後運算完 Unlock,自然會造成效能瓶頸
- Check if a task is “runnable”
- in TASK_RUNNING state
- in TASK_INTERRUPTIBLE state and a signal is pending
- Examine the “goodness” of each process
- 檢查所有 Task 的 Goodness,並且選出最好的 Task
- Context switch
2.4 Scheduler - Goodness:
- “goodness”: identifying the best candidate among all processes in the runqueue list.
- “goodness” = 0: the entity has exhausted its quantum.
- 0 < “goodness” < 1000: the entity is a conventional process/thread that has not exhausted its quantum; a higher value denotes a higher level of goodness.
if (p->mm == prev->mm)
return p->counter + p->priority + 1;
else
return p->counter + p->priority;
A small bonus is given to the task p if it shares the address space with the previous task.
Examine the processor field of the processes and gives a consistent bonus (that is PROC_CHANGE_PENALTY, usually 15) to the process that was last executed on the ‘this_cpu’ CPU.
例如: 一個 Multi-thread 程式的 Task,如果有一個 Thread 執行在一個 CPU 上,那麼其他的 Thread 就會有一個加分,讓他們可以在同一個 CPU 上執行。 同樣的如果一個 Process 最後是在這 this_cpu 上運行,那麼他在這顆 CPU 上計算分數時也會有獎勵加分。
2.4 Scheduler 的問題是 Scheduler 要對所有的 Task 計算 goodness,每次都要重算。但其實大多數時間每次計算出的 goodness 都是差不多的, 真的有需要每次都重算嗎?
Linux 2.4 Scheduler - Improve I/O performance
Defintion:
- I/O-bound processes: spends much of its time submitting and waiting on I/O requests
- Processor-bound processes: spend much of their time executing code
Linux 傾向於支援 I/O-bound processes,這樣會提供好的 Process response time,但是怎麼對 Process 進行分類?
- 將 Run time 分為無數個 epoch
- 當沒有 task 可以執行時就換到下一個 epoch
- 此時可能有些 task 的 time slice 還沒用完,但這些 task 正在 waiting
- 2.4 Scheduler 假設所有的 waiting 就是在 waiting I/O
- 進入下一個 epoch 的時候,補充所有 task 的 time slice
- 如果是 I/O-bound task,因為在上一個 epoch 在 waiting I/O,還有一些 time slice 沒用完, 因此補充後這些 task 會有較多的 time slice
- 在 Linux 2.4 中,time slice 就是 dynamic priority
- 因此 I/O-bound task 會有較高的 dynamic priority
從上面的圖來看:
- Epoch1: CPU bound 都已經用完 time slice,此時剩下 I/O bound slice,必須進入下一個 epoch 否則會進入 idle
- Epoch2: 使用 timeSlicenew = timeSliceold / 2 + baseTimeSlicep[nice] 的公式來補充 time slice
- 依照這樣的運算 Epoch2 的 I/O bound task 一定會比 CPU bound 有更高的 Priority
注意 Kernel 中不會使用 FPU,因此不會有 float point
Cauclate time Slice
timeSlicenew = timeSliceold / 2 + baseTimeSlicep[nice]
為什麼要除以 2,假如有一個惡意的程式如下:
int main() {
sleep(65535);
while(1)
;
}
每次拿到 CPU time 就去 sleep,因此在 sleep 中會被視為一個 I/O bound task,因此拿到很高的 time slice, 這樣醒來時就是一個 CPU bound task 同時也有很高的 time slice,可以搶佔 CPU 造成其他的 I/O bound task 也無法獲取 CPU time。
Main disadvantages of 2.4 Scheduler
- 計算 goodness 太耗費時間,就算某個 Task goodness 一直沒變,每次還是要重新計算
- 所有 CPU 共用同一個 Run queue,這個 Run queue 會變成系統的效能瓶頸,因為每次都要 Lock & Unlock
- Wating 不一定是 I/O,例如: sleep()
- 在 2.4 Scheduler 中只針對 I/O 做提高優先權
- 例如 waiting child process 也是一種 waiting,也可以被考慮在內
4.9 Linux 2.6 Scheduler
- O(1) Scheduler
- CFS(Complete Fair Scheduler)
2.6 Scheduler Architecture
2.6 Scheduler 首先在架構的改善就是使每一顆 CPU 有自己的 Run queue
- 即使這樣 CPU 要去 Run queue 拿資料時也要做 Lock & Unlock
- 因為是 Lock 自己的 Run queue,因此 Lock & Unlock 通常都會成功,不會有競爭的情況發生
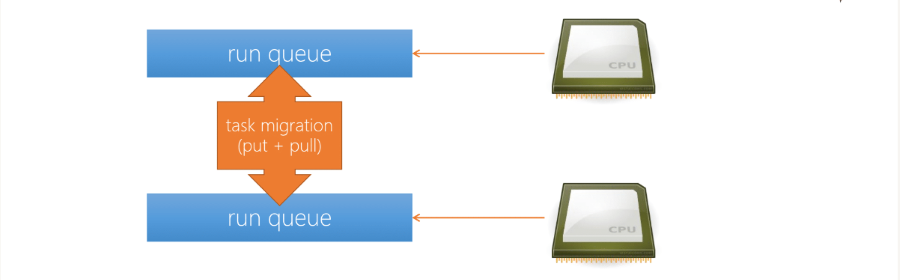
當自己有自己的 Run queue 後要考慮的就是 Load balancing(負載平衡)
- 系統去檢查 Run queue 是否 Loading 過重,如果是就會將 Task 搬移到另一個 Run queue
- 因此才需要 Lock & Unlock,是為了避免 CPU 在搬移 Task 時出現錯誤
- Put: 當 CPU 覺得自己的 loading 太重,將 task 塞給另一顆 CPU
- Pull: 覺得自己的 loading 太輕,從別的 CPU 拉 task 過來
- 如何評估 Loading 輕重
- 比較簡單的方式,查看每個 CPU 的 Task 數量跟 runnable task 數量
每一顆 CPU 上都會有一個 thread 來觀察是否要做 Load balancing,這個 thread 稱作 Balance thread
但假如 A, B 兩顆 CPU 同時要搬移 Task 要給予對方,同時鎖定對方的 Run queue,就會造成互相等待,造成 Deadlock,這部分後面會說明
CPU Affinity
- 由於每一顆 CPU 都有自己的 Run queue,通常除非 Loading unbalance,否則不會去觸發 Task migration
- 因此 2.6 Scheduler 可以更有效的使用 Cache
Fully Preemptible Kernel
2.6 Kernel 之後,Linux 中每一個 Task 執行於 Kernel mode 時會有一個變數 preempt_count,用於記錄該 Task 是否可以被 Preempt
- 每當 Lock 一個 Resource 時,
preempt_count++ - 每當 Unlock 一個 Resource 時,
preempt_count-- - 如果
preempt_count == 0,Kernel 可以做 Context switch- Kernel 要做 Context switch 通常是因為 interrupt,例如: 一個高優先權的 task 正在等這個 interrupt
- 每次
preempt_count從 1 變為 0,Kernel 都會檢查一下是否要 Context switch
- 如果 Kernel 直接執行 schedule(),無論
preempt_count是多少,都會做 Context switch
schedule() 是在 Linux kernel 中的重要函數,會直接進行 scheduler 調度,並且切換到下一個 Task 執行
O(1) & CFS scheduler
4.10 O(1) Scheduler
4.11 CFS Scheduler
- 2.5 ~ 2.6.22: O(1) Scheduler
- Time complexity: O(1)
- Using Run queue(an active Q and an expired Q) to realize the ready queue
- 2.6.23 ~ : CFS Scheduler
- Time complexity: O(log N)
- the ready queue is implemented as a red-black tree
4.10 O(1) Scheduler
- 每顆 CPU 有自己的 Run queue,每個 Run queue 由兩個 Array 組成
- active array: time quantum 還沒用完的 task
- expired array: time quantum 用完的 task
- Time complexity: O(1)
- 能在 O(1) 的時間內 access, search, insert, delete
- 每次用完 time quantum 的 task 被移到 expired array 並在此時計算下一回合的 Dynamic priority
- 選出最高 Priority 的 Task,就使用求 min 的演算法
對一個 array 求 min 的演算法最佳 time complexity 為使用 heap 建立資料結構,time complexity 為 O(log N), 但是因為 Linux 的優先權只有 140 種,因此可以使用一些方法來優化到 O(1)
struct prio_array {
unsigned int nr_active;
unsigned long bitmap[BITMAP_SIZE]; // BITMAP_SIZE = 140
struct list_head queue[MAX_PRIO]; // MAX_PRIO = 140
};
typedef struct prio_array prio_array_t;
struct runqueue {
/* ... */
struct mm_struct *prev_mm; // prev task's mm_struct
prio_array_t *active, *expired;
prio_array_t arrays[2];
/* ... */
};
- prio_array
- nr_active: 紀錄 active array 中有多少 task
- bitmap: 用來快速查詢至少有一個 task 的 priority
- queue: 用來存放相同 priority 的 task
- runqueue 中維護了兩個 prio_array,分別是 active, expired
- *prev_mm: 如果 task 是同一個程式的 thread 那麼 mm_struct 指向的位置會是一樣,這樣就可以不用做 Memory context switch
延伸閱讀: Linux 核心設計: O(1) Scheduler, Linux 核心設計: 不只挑選任務的排程器: O(1) Scheduler
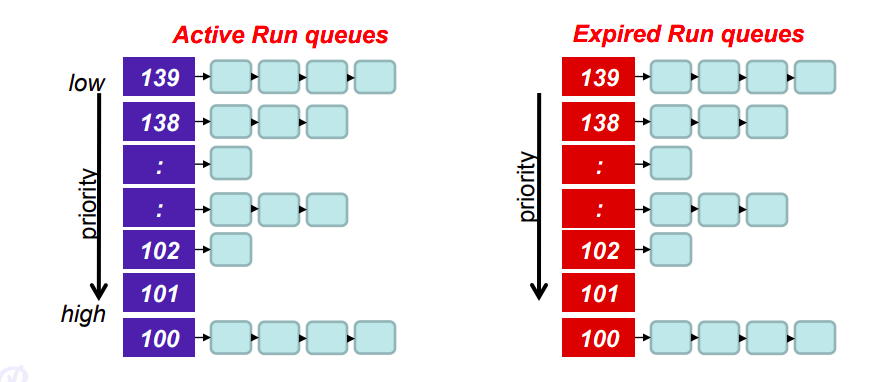
- 在這兩個 Queue 中每個 Task 可以拿到的 Time quantum 大約等於 1 / priority
- 在 Linux 中 Priority 高有兩個好處:
- 有較高的 Time quantum(Time slice)
- 可以更快的搶到 CPU
- 在 Active queue 中較高優先權的 task 除非放棄或是 time quantum 用完,否則後面的 task 都不會執行
- 在同一個 priority 中,會依照 Round-Robin 的方式來輪流執行
- 如果進行 I/O bound 也就是放棄,那麼就會被移到 expired queue,並且在此時計算下一回合的 Dynamic priority
- 如果是 I/O bound 那就會獲得比較高的 Priority
- 等到 Active queue 中的所有的 task 都被移到 expired queue 後,就會將兩個 queue 交換
4.10 O(1) Scheduler - bitmap

- 在 bitmap 中每個 bit 代表一個 priority,如果為 1 表示至少有一個 task
- Insert, Delete 的演算法如下:
- Y = priority / 32, X = priority % 32
- 例如: 編號 9 的 Priority,9 / 32 = 0, 9 % 32 = 9, 即可存取 bitmap[0][9] 設定為 0 或 1
- Min(尋找最高優先權的 Task):
- 從 0 開始找顯然要 O(N) 的時間,不是 O(1)
- 有硬體支援的話就能直接使用一個 Function ffs() 就能做到 O(1)
- 在 include/asm-generic/bitops 中有一系列 ffs() 的實作
Disadvantages of O(1) Scheduler
- 跟 2.4 Scheduler 一樣,使用 Epoch 來區分 I/O bound & CPU bound
- 因此每個 Task 都要再使用完 Time slice 以後,經過一個 Epoch 才能獲得更多的 Time slice
- 對於某些需要更頻繁的獲取 CPU time 的 Task 來說,無論 Priority 多高都要等待一個 Epoch 才能獲得更多的 Time slice
- 例如: 遊戲、多媒體
延伸閱讀: 谈谈调度 - Linux O(1)
4.11 CFS Scheduler
CFS source code 目前存在於: linux/kernel/sched/fair.c
CFS (Completely Fair Scheduler) 在 2.6.23 之後取代 O(1) Scheduler,但是 O(1) Scheduler 獨特的設計與簡單的算法, 影響了很多系統的設計。CFS 雖然在性能上比 O(1) Scheduler 差,但是在公平性上比 O(1) Scheduler 好。
- CFS 獨特的地方在於回填 Time quantum
- 相較於前面兩種 Scheduler,Priority 高的 Task 回填速度會更快
- 因此高 Priority 的 Task 會有更多的 Time slice,更好的 Response time
Design Concept
- 將一顆 Physical CPU 依照目前正在執行的 Task 分成多個 Virtual CPU
- 假如這些 Task 的 Priority 都一樣,那麼每個 Virtual CPU 的效能為 Physical CPU 效能的 1 / N
- 這表示如果 Task 的優先權越低,那麼他的 Time slice 就會越小
- 但是每次的執行時間也有下限,不可能依照 Task 的數量無限制的分割 1 / N,所以會有一個臨界值 λ
- λ = 「希望達到的反應時間」/「# of task」
- 這個 λ 是可以由使用者設定的
前兩個 Scheduler 都是等到所有 Ready queue 裡面的 Task 都用完 Time slice,Scheduler 才會去計算下一回合的 Time slice, 稱作 Epoch。
- 藉由 Epoch 可以看 Task 在上一個 Epoch 的行為來判斷他是 I/O bound 還是 CPU bound
- 但是在 CFS 中,是依照 waiting time 來決定執行順序,waiting time 越長的 Task 優先執行
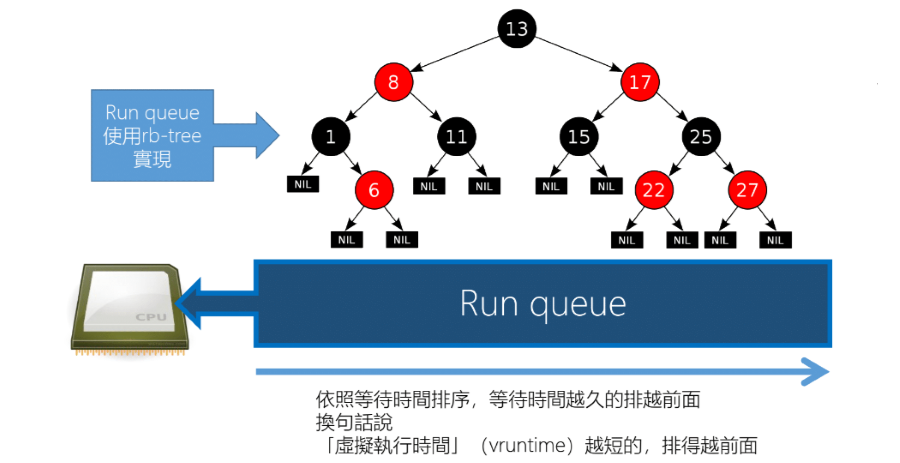
CFS Architecture
- 這裡使用 rbtree 來實作 Ready queue,依照 Task 的 vruntime 來排序
- vruntime 表示的是一個 task 真正在 CPU 上的執行時間
- vruntime 越小表示 Task 在 CPU 上執行的時間越少,因此從公平的角度來看優先權越高
- 每次執行就取出 rbtree 中最左邊的 Task 執行
- 執行完畢後就計加上 delta_exec,然後重新放回紅黑樹中因此 Time Complexity 為 Θ(log N)
- 這樣可以確保每個 Task 都有機會在 rbtree 的最左邊,也就是最優先執行的位置
delta_exec 如何計算的 source code 目前存在於: linux/kernel/sched/fair.c 中的
__calc_delta()
Virtual Time
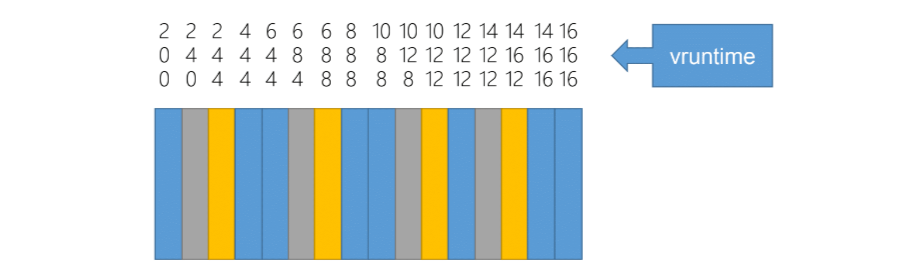
在之前的 Scheduler,Time slice 是不固定的,優先權越高的 Task Time slice 越長,但是在 CFS 中,Time slice 是固定的, 這個 Time slice 是依照系統希望的 Response time 來計算的。
例如下面的例子,如果將 CPU 模擬為 3 個 CPU,分別為 1/2(藍色), 1/4, 1/4 的效能,那麼每次當藍色的 Task 執行完畢後, 計算出的 vrutime 會比 1/4 的還要小,因此在同一個時間單位內,藍色的 Task 會執行更多次。
CFS - I/O
- 如果有從 Waiting queue 回來的 I/O Task 怎麼把他放到 rbtree 最左邊
- 將他設定為最小的 vruntime 這樣就能強制 Scheduler 馬上進行 Context switch 執行 I/O Task
- min_vruntime: CFS 會去維護一個 min_vruntime,表示目前 rbtree 中最小的 vruntime
- min_vruntime - Δ 設定為從 waiting queue 回來的 Task 的 vruntime 這樣就能馬上執行
也因為這樣的設計,假如有一個 CPU bound Task 在這樣的設計下即使 Priority 最高 -19,也會被搶走 CPU time。
CFS - New Task
將新進入系統的 Task 都設為 min_vruntime 插入到 rbtree 的最左邊,但是如果有一個這樣的程式:
while(1) {
fork();
}
在 Linux 的解決方法是將剩餘的 CPU time 平均分配給 child, parent,另外也可以設定 ulimit 來限制一個 process 可以 fork 的次數, 超過這個次數就可以認為他是一個惡意的程式。
延伸閱讀: Fork bomb
Scheduler Problem
對於現在的 Linux Scheduler 來說還有什麼需求沒有被滿足:
- 對於 Real-time 的支援
- 對於 Power management 的支援(Power saving)
- 動態調整 CPU clock rate, voltage
- 讓 CPU 能進入省電模式,例如: ACPI 定義的 C0, C1, C2 …,Advanced Configuration and Power Interface
- 對於 BigLittle 等新的 CPU Architecture 的支援
- 優先權是否可以和 Time slice 拆開,以實現更好的 QoS(Quality of Service)
- 例如: 實現一個 system call 叫做 balance,可以調整 time slice 和 priority 的比例
Last Edit
12-02-2023 16:03