LLVM | CPU0 Create Backend Machine
CPU0 是一個 LLVM 教學用的目標架構,主要用來展示 LLVM 從中間表示(IR)到目標機器碼的轉換過程。在這篇文章中,我們將介紹如何為 CPU0 架構創建 LLVM 後端。
Tutorial: Creating an LLVM Backend for the Cpu0 Architecture
1.1 Introduction
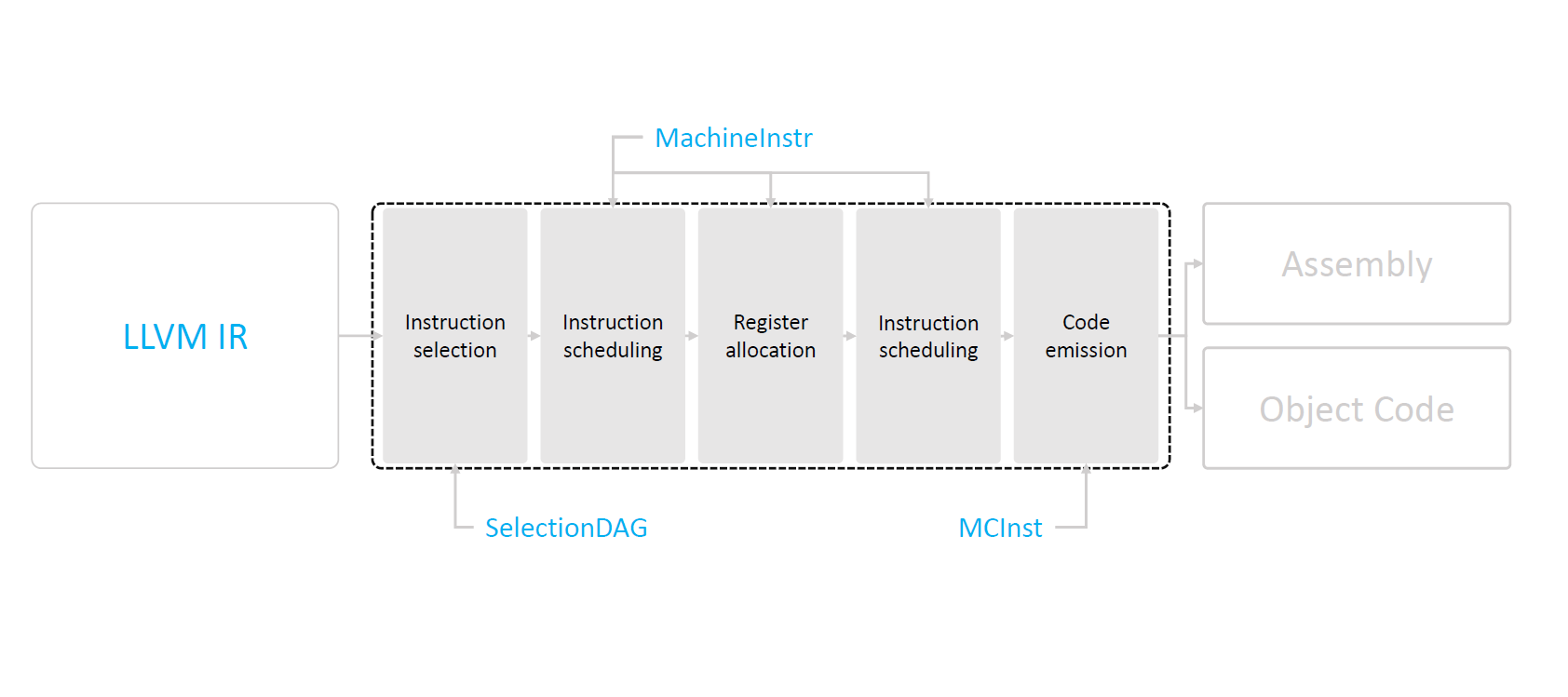
在 LLVM IR 之前,不管什麼語言都將轉換成 LLVM IR,然後再 LLVM IR 階段會進行與目標無關的最佳化,這些階段的輸入輸出都是 LLVM IR。在進入 Codegen 階段之後,就開始目標相關的最佳化。這個最佳化的過程我們可以簡單分成幾個步驟:
- Selection DAG Lowering
- 將 LLVM IR 轉換成 SelectionDAG
- 每個 Basic Block 都會產生一個 SelectionDAG
- Instruction Selection
- 對於 IR 中的每個 Basic Block 都會產生一個 SelectionDAG
- Instruction Scheduling
- 在 2 的階段 SelectionDAG 會被轉換成 MachineInstr
- 在此階段 Physical Register 仍未分配,可以做 Pre-RA Scheduling
- Register Allocation
- 將 Virtual Register 分配到 Physical Register
- Instruction Scheduling (Again)
- 在 Register Allocation 後,會再次進行 Instruction Scheduling
- 此處才能根據 Pipeline 的特性來進行 Scheduling
- Code Emission
- 此處將 MachineInstr 轉換 MCInst
- 最後將 MCInst 轉換成 Assembly Code 或 Machine Code
CPU0
CPU0 是一個 32bit 的 RISC 架構,具有簡單的指令集和固定長度的指令格式。詳細的 CPU0 架構規格可以參考 CPU0 Architecture。主要有三種指令類型,分別是 R-Type、I-Type 和 J-Type 指令。
- L-type instructions: Primarily used for memory operations.
- A-type instructions: Designed for arithmetic operations.
- J-type instructions: Typically used for altering control flow (e.g., jumps).
1.2 Cpu0 Backend Machine ID and Relocation Records
這些修改的目的是讓 LLVM 認識 CPU0 架構,並能夠正確處理與 CPU0 相關的機器碼和重定位資訊
在 CPU0 的教學中,首先要為 CPU0 定義 Backend Machine ID 和 Relocation Records。這些檔案位於 lbdex/llvm/modify 在編譯過程中會直接替換 LLVM Source Code 中對應的檔案。其中包含以下檔案:
- llvm/config-ix.cmake
- LLVM Cmake 的配置檔案,負責 LLVM_NATIVE_ARCH 依照 Host 的系統來設定在什麼架構下編譯
- 它決定了 LLVM 自己在建置階段該使用哪個目標架構,例如啟用哪些最佳化或平台特定的邏輯
- 此設定只影響 LLVM 本身的建置行為,不影響 LLVM 是否支援其它平台
- llvm/CMakeLists.txt
- LLVM 的主要 CMake 配置檔案,負責定義 LLVM 的建置過程和模組
- 將
Cpu0加入LLVM_ALL_TARGETS列表後,才會觸發編譯lib/Target/Cpu0目錄下的後端模組
- llvm/include/llvm/ADT/Triple.h
Triple是 LLVM 中用來表示目標平台的標準格式,格式為arch-vendor-os-abi- x86_64-pc-linux-gnu
- cpu0-unknown-none
- LLVM 會依照 Triple 來選擇合適的 TargetMachine、TargetLowering、TargetInstrInfo 等元件
- llvm/lib/Support/Triple.cpp
- 實作 Triple 的 string, enum 的查詢邏輯
- llvm/include/llvm/Support/ELF.h
- 這裡說明了 CPU0 的 ELF 中的 Machine ID, e_flags, relocation types
- llvm/include/llvm/Support/ELFRelocs/Cpu0.def
- 定義 CPU0 架構的 ELF 重定位類型,例如:
ELF_RELOC(R_CPU0_32, 2) ELF_RELOC(R_CPU0_LO16, 6)
- 定義 CPU0 架構的 ELF 重定位類型,例如:
- llvm/include/llvm/Object/ELFObjectFile.h
- 定義解析 ELF object file 的功能,例如:
- getArch() 透過 ELF header 取得 Machine ID
- getFileFormatName() 取得 ELF file format name
- 輸出像
"ELF32-cpu0"的格式名
- 輸出像
- 定義解析 ELF object file 的功能,例如:
- llvm/lib/Object/ELF.cpp
- 實作 ELF relocation 的編號與名稱對應邏輯
- 在 CPU0 中這裡是在 switch case 中 include Cpu0.def 來處理 CPU0 的 relocation types
- llvm/lib/MC/MCSubtargetInfo.cpp
- 處理 subtarget 的 CPU 名稱與 feature string 的對應
- llvm/lib/MC/SubtargetFeature.cpp
- 實作了 LLVM SubtargetFeature 的 string 處理邏輯
這個階段的修改目標是讓 LLVM 能識別 Cpu0 架構,必須做到以下幾點:
- 註冊 triple 名稱
cpu0-unknown-none - 註冊它的 ELF Machine ID (EM_CPU0) 與 Relocation 類型
- 支援 llvm-objdump, llvm-mc 等工具能正確處理 ELF32-cpu0 格式
- 否則只會出現 “unknown file format” 的錯誤訊息
- 避免報錯(例如 feature string 沒定義時跳出 unrecognized 警告)
這些修改在目前的階段只要完全照著做就可以了,如果想要深入這部分的研究,要補充 ELF format、LLVM Triple、LLVM MC layer、Relocation types 等相關知識
1.3 Cpu0.td Files
LLVM’s Target Description Files: .td
TableGen Overview 官方的文件介紹了 TableGen 的基本概念
詳細的 TableGen 介紹可以參考 TableGen Introduction
LLVM 使用 TableGen (.td) 文件來描述目標架構的指令集、寄存器和其他相關資訊。這些文件定義了 CPU0 的指令格式、操作數類型以及指令的語義。這些描述檔案通常放在 LLVM 的目標目錄下,在 llvm-project/llvm/lib/Target 下,我們可以找到這些不同目標的檔案,如 RISCV, ARM, X86 等等。實際上要在 LLVM 中新增一個目標架構,主要就是撰寫這些 TableGen 檔案。
CPU0 td 檔案的主要入口是 Cpu0Other.td,在此之前需要先完成 CmakeLists.txt 的設定,讓 LLVM 能夠編譯 Cpu0 後端模組。CPU0 是一個章節式的教學範例,可以透過更改 Cpu0SetChapter.h 中的 #define CH CH2 來選擇哪個章節的功能要被編譯進去,更改完後重新編譯 LLVM。
1.3.1 Cpu0.td
完整的程式碼請參考 CPU0 Cpu0 Architecture and LLVM Structure 章節,接下來逐小節說明該檔案的內容
SubtargetFeature
def FeatureChapter3_1 : SubtargetFeature<"ch3_1", "HasChapterDummy","true", "Enable Chapter instructions.">;
- SubtargetFeature: 是 LLVM TableGen 中用來定義子目標特性的類型
- 這些特性可以用來描述目標架構的不同變體或功能
- 例如,某些 CPU 可能支援特定的指令集擴展,這些擴展可以透過 SubtargetFeature 來表示
- SubtargetFeature 的格式在
llvm/include/llvm/Target/Target.td中、是字串形式的表格class SubtargetFeature<string n, string f, string v, string d, list<SubtargetFeature> i = []> { string Name = n; string FieldName = f; string Value = v; string Desc = d; list<SubtargetFeature> Implies = i; } - CPU0 透過 SubtargetFeature 來定義不同功能的開啟與關閉,例如:
def FeatureCmp : SubtargetFeature<"cmp", "HasCmp", "true", "Enable 'cmp' instructions.">; ... def FeatureCpu032II : SubtargetFeature<"cpu032II", "Cpu0ArchVersion", "Cpu032II", "Cpu032II ISA Support (slt)", [FeatureCmp, FeatureSlt, FeatureChapterAll]>;FeatureCmp: 啟用 cmp 指令FeatureCpu032II: 啟用所有章節的內容與 Cmp、Slt 指令
Processor
class Proc<string Name, list<SubtargetFeature> Features> : Processor<Name, Cpu0GenericItineraries, Features>;
Processor是 LLVM TableGen 中用來定義處理器的類型- 它描述了一個具體的處理器模型,包含其名稱、行程安排、子目標特性、微架構最佳化特性
class Processor<string n, ProcessorItineraries pi, list<SubtargetFeature> f,list<SubtargetFeature> tunef = []>
- CPU0 定義了兩個 Processor,並加入
Cpu0GenericItinerariesPipelines:class Proc<string Name, list<SubtargetFeature> Features> : Processor<Name, Cpu0GenericItineraries, Features>; def : Proc<"cpu032I", [FeatureCpu032I]>; def : Proc<"cpu032II", [FeatureCpu032II]>;
Target
def Cpu0 : Target {
let InstructionSet = Cpu0InstrInfo;
}
- 最後 CPU0 定義了 Target,並指定它的 InstructionSet 為
Cpu0InstrInfo Target是 LLVM TableGen 中用來定義目標架構的類型,其中包含以下欄位:- InstructionSet: 指定該 Target 使用哪個 InstructionInfo
- AssemblyParsers: 指定該 Target 使用哪個 Assembly Parser
- 通常預留 DefaultAsmParser
- AssemblyParserVariants: 支援哪幾種 Assembly 變體如: AT&T, Intel Style
- AsmWriters: 此 Target 對應的 Assembly Writer 變體,用於 Assembly Code 的輸出
- AllowRegisterRenaming: 是否允許 Register Renaming,Default 為 0
以上的 SubtargetFeature、Processor、Target 都位於 llvm/include/llvm/Target/Target.td 中,可以參考該檔案了解更多細節。
1.4 Cpu0 Register
1.4.1 Cpu0RegisterInfo.td
Register
Cpu0RegisterInfo.td 定義了 CPU0 架構的 Register Set 和 Register Classes
// We have banks of 16 registers each.
class Cpu0Reg<bits<16> Enc, string n> : Register<n> {
// For tablegen(... -gen-emitter) in CMakeLists.txt
let HWEncoding = Enc;
let Namespace = "Cpu0";
}
// Cpu0 CPU Registers
class Cpu0GPRReg<bits<16> Enc, string n> : Cpu0Reg<Enc, n>;
// Co-processor 0 Registers
class Cpu0C0Reg<bits<16> Enc, string n> : Cpu0Reg<Enc, n>;
- 在 CPU0 中定義了兩種 Register 類型:
Cpu0GPRReg: General Purpose Registers (GPRs)- R0 ~ R15 共 16 個通用暫存器
Cpu0C0Reg: Co-processor 0 Registers (C0Rs)- PC, EPC 協處理器暫存器
Register是 LLVM TableGen 中用來定義寄存器的類型class Register<string n, list<string> altNames = []>
- 位址同樣位於
llvm/include/llvm/Target/Target.td中,其包含以下重要欄位:string namespace: 命名空間- “Cpu0”, “X86”
list<string> AltNames: 別名清單- MIPS
a0, r4
- MIPS
AsmName: 實際在 Assembly code 中使用的名稱bits<16> HWEncoding: 此 Register 在機器碼中的硬體編碼,- RISC-V 為 5 bits
DwarfNumbers: DWARF Debugging 用的 Register 編號CostPerUse: 指令使用該 Register 的額外代價,與 Codesize 有關、影響 Register AllocationisArtificial: 若表示為 true,表示此 Register 是虛擬的、非實體存在的- x86 的
EFLAGS、RIP等特殊用途的 Register
- x86 的
SubRegs: 定義此 Register 的子 Register- x86 的
RAX有EAX,AX,AL,AH等子 Register
- x86 的
SubRegIndices: 對應SubRegs的 Indexsub_16bit_hi,sub_lo等
Aliases: 與此 Register 記憶體位置相同的其他 RegisterSP可能 alias 某個 General Purpose Register
CoveredBySubRegs: 若為 true,表示此 Register 的值完全由其 sub-registers 決定- x86 的
RAX為 true,因為其值由EAX,AX,AL,AH決定
- x86 的
// The register string, such as "9" or "gp" will show on "llvm-objdump -d"
//@ All registers definition
let Namespace = "Cpu0" in {
//@ General Purpose Registers
def ZERO : Cpu0GPRReg<0, "zero">, DwarfRegNum<[0]>;
def AT : Cpu0GPRReg<1, "1">, DwarfRegNum<[1]>;
def V0 : Cpu0GPRReg<2, "2">, DwarfRegNum<[2]>;
def V1 : Cpu0GPRReg<3, "3">, DwarfRegNum<[3]>;
def A0 : Cpu0GPRReg<4, "4">, DwarfRegNum<[4]>;
def A1 : Cpu0GPRReg<5, "5">, DwarfRegNum<[5]>;
def T9 : Cpu0GPRReg<6, "t9">, DwarfRegNum<[6]>;
def T0 : Cpu0GPRReg<7, "7">, DwarfRegNum<[7]>;
def T1 : Cpu0GPRReg<8, "8">, DwarfRegNum<[8]>;
def S0 : Cpu0GPRReg<9, "9">, DwarfRegNum<[9]>;
def S1 : Cpu0GPRReg<10, "10">, DwarfRegNum<[10]>;
def GP : Cpu0GPRReg<11, "gp">, DwarfRegNum<[11]>;
def FP : Cpu0GPRReg<12, "fp">, DwarfRegNum<[12]>;
def SP : Cpu0GPRReg<13, "sp">, DwarfRegNum<[13]>;
def LR : Cpu0GPRReg<14, "lr">, DwarfRegNum<[14]>;
def SW : Cpu0GPRReg<15, "sw">, DwarfRegNum<[15]>;
def PC : Cpu0C0Reg<0, "pc">, DwarfRegNum<[20]>;
def EPC : Cpu0C0Reg<1, "epc">, DwarfRegNum<[21]>;
}
Register 命名原則幾乎與 MIPS 相同,因為 CPU0 是基於 MIPS 架構設計的。
AT = Assembler Temporary, V = Value registers, A = Argument registers, T = Temporary registers, S = Saved registers, GP = Global Pointer, FP = Frame Pointer, SP = Stack Pointer, LR = Link Register, SW = Status Word
DwarfRegNum
- CPU0 的 Register 同時繼承了
DwarfRegNum,用來指定 DWARF Debugging 中的 Register 編號- 例如
ZERORegister 在 DWARF 中的編號為 0
- 例如
DwarfRegNum定義在llvm/include/llvm/Target/Target.tdclass DwarfRegNum<list<int> Numbers>
DWARF 是一套廣泛使用的除錯資訊格式標準,用於在 object/executable 中描述符號、型別、source line、變數位置等除錯所需資訊。
RegisterClass
def CPURegs : RegisterClass<"Cpu0", [i32], 32, (add
// Reserved
ZERO, AT,
// Return Values and Arguments
V0, V1, A0, A1,
// Not preserved across procedure calls
T9, T0, T1,
// Callee save
S0, S1,
// Reserved
GP, FP,
SP, LR, SW)>;
//@Status Registers class
def SR : RegisterClass<"Cpu0", [i32], 32, (add SW)>;
//@Co-processor 0 Registers class
def C0Regs : RegisterClass<"Cpu0", [i32], 32, (add PC, EPC)>;
- RegisterClass 用於分類和組織 Register Set
- 其定義同樣位於
llvm/include/llvm/Target/Target.tdclass RegisterClass< string namespace, list<ValueType> regTypes, int alignment, dag regList, RegAltNameIndex idx = NoRegAltName > : DAGOperand - Cpu0RegisterInfo.td 定義了三個 RegisterClass:
CPURegs: 包含所有通用暫存器SR: 包含狀態暫存器 SWC0Regs: 包含協處理器 0 的暫存器 PC 和 EPC
以上就是 Cpu0RegisterInfo.td 的主要內容,這些定義讓 LLVM 能夠識別和操作 CPU0 架構的 Register
1.4.2 Cpu0RegisterInfoGPROutForOther.td
同一個 Register 可以有多個 RegisterClass 的定義
其中,GPROut 這個 Register Class 定義於 Cpu0RegisterInfoGPROutForOther.td,其內容包含 CPURegs 中除了 SW 以外的所有暫存器。這樣的設計可確保在 Register Allocation 階段中,SW 不會被配置為輸出暫存器( output register )。
def GPROut : RegisterClass<"Cpu0", [i32], 32, (add (sub CPURegs, SW))>;
sub: is subtraction operation for DAG or listadd: is addition operation for DAG or list
SW 通常不是作為顯式的 Register 使用,而是用於保存 CPU 狀態的特殊 Register。因此,在某些情況下,我們希望避免將 SW 分配為輸出暫存器,以防止不必要的干擾或錯誤。
CMP r1, r2 ; implicit-def SW
BEQ label ; implicit-use SW
ADD r3, r4 ; explicit-def r3, implicit-def SW
SW 通常是與 ALU 操作相關聯的,因此更接近於 GPR 而不是 C0Reg (Co-processor 0 Register)
1.5 Cpu0 Instruction
1.5.1 Cpu0InstrFormats.td
首先第一步要定義的是 CPU0 的指令格式 (Instruction Formats),這些格式定義了每種指令的結構和操作數類型。CPU0 有三種主要的指令格式: R-type、I-type 和 J-type。
Custom Format
// Format specifies the encoding used by the instruction. This is part of the
// ad-hoc solution used to emit machine instruction encodings by our machine
// code emitter.
class Format<bits<4> val> {
bits<4> Value = val;
}
def Pseudo : Format<0>;
def FrmA : Format<1>;
def FrmL : Format<2>;
def FrmJ : Format<3>;
def FrmOther : Format<4>; // Instruction w/ a custom format
Format是 Cpu0 自訂義的欄位,用來表示指令的格式類型- 利用該欄位可以在指令編碼和解碼時區分不同的指令格式
Instruction
一條具體的 Instruction 是從上自下從 Base Class -> Instruction Type -> Instruction 來繼承實現的
Instruction位於llvm/include/llvm/Target/Target.td欄位眾多,此處直接講解 Cpu0Inst 設計
// Generic Cpu0 Format
class Cpu0Inst<dag outs, dag ins, string asmstr, list<dag> pattern,
InstrItinClass itin, Format f>: Instruction
{
// Inst and Size: for tablegen(... -gen-emitter) and
// tablegen(... -gen-disassembler) in CMakeLists.txt
field bits<32> Inst;
Format Form = f;
let Namespace = "Cpu0";
let Size = 4;
bits<8> Opcode = 0;
// Top 8 bits are the 'opcode' field
let Inst{31-24} = Opcode;
let OutOperandList = outs;
let InOperandList = ins;
let AsmString = asmstr;
let Pattern = pattern;
let Itinerary = itin;
//
// Attributes specific to Cpu0 instructions...
//
bits<4> FormBits = Form.Value;
// TSFlags layout should be kept in sync with Cpu0InstrInfo.h.
let TSFlags{3-0} = FormBits;
let DecoderNamespace = "Cpu0";
field bits<32> SoftFail = 0;
}
field 是 TableGen 中的可變欄位,可以被多次修改與覆蓋
Cpu0Inst是所有 CPU0 指令的基類,定義了指令的基本結構和屬性- 包含輸入輸出操作數、組合語言表示、指令模式、行程安排類別和格式等欄位
field bits<32> Inst;: 定義 Instruction 的 32 位元編碼- LLVM 沒有內建 Inst 這樣的欄位,並不會刻意提供 Instruction 的 bit layout 這種欄位, 因為 LLVM 必須支援任何 ISA 的形狀
Format Form = f;: 指定指令的格式類型,此為 Cpu0 自訂義的欄位let Size = 4;: 定義指令的大小為 4 bytesbits<8> Opcode = 0;: 定義指令的 Opcode 欄位為 8 bitslet Inst{31-24} = Opcode;: 指定 Opcode 在指令編碼中的位置,這裡是最高的 8 位元let OutOperandList = outs;定義指令的輸出操作數列表,也就是 Register Class- 常見寫法如:
(outs R32:$rd, R32:$rs),表示 $dst 必須從 GPROut 類別挑 physical reg
- 常見寫法如:
let InOperandList = ins;定義指令的輸入操作數列表,也是 Register Classlet AsmString = asmstr;指定指令的組合語言表示let Pattern = pattern;定義指令的模式,用於指令選擇和生成- 在 Instruction Selection 階段會用到
let Itinerary = itin;指定指令的行程安排類別,用於指令調度let TSFlags{3-0} = FormBits;定義指令的目標特定標誌,這裡用於存儲指令格式資訊Target-Specific Flags是每條指令可以攜帶的額外資訊,LLVM 並不了解這些標誌的意義
field bits<32> SoftFail = 0;定義一個可變欄位,用於指示指令是否允許軟失敗
以上定義了 Cpu0Inst 的基本結構,接下來可以基於此類別定義 Instruction Type
SoftFail 是提供給 disassembler 使用的機制,用於標示「編碼合法,但語意或 operand 組合不完全合法」的情況,不影響執行階段行為,也不涉及程式是否崩潰
Instruction Type
此處僅以 Type A 為例,其他 Type 類似
class FA<bits<8> op, dag outs, dag ins, string asmstr,
list<dag> pattern, InstrItinClass itin>:
Cpu0Inst<outs, ins, asmstr, pattern, itin, FrmA>
{
bits<4> ra;
bits<4> rb;
bits<4> rc;
bits<12> shamt;
let Opcode = op;
let Inst{23-20} = ra;
let Inst{19-16} = rb;
let Inst{15-12} = rc;
let Inst{11-0} = shamt;
}
A-type (Arithmetic type) 指令格式,主要用於算術運算指令。以 3 地址運算的指令模板, 同時包含一個 shift amount 欄位 (shift amount)。其餘 L-type、J-type 都是類似的定義方式。
| Type | Instruction Encoding (Bits) | |||||
|---|---|---|---|---|---|---|
| A-type | Op | Ra | Rb | Rc | Shamt | |
| 31–24 | 23–20 | 19–16 | 15–12 | 11–0 | ||
| L-type | Op | Ra | Rb | Cx (16 bits) | ||
| 31–24 | 23–20 | 19–16 | 15–0 | |||
| J-type | Op | Cx (24 bits) | ||||
| 31–24 | 23–0 | |||||
透過上述定義,我們定義了 Cpu0 指令的格式和結構,這些定義將用於後續的指令實現和編碼過程中
1.5.2 Cpu0InstrInfo.td
Cpu0InstrInfo.td 定義了 CPU0 架構的具體指令
SDTypeProfile
def SDT_Cpu0Ret : SDTypeProfile<0, 1, [SDTCisInt<0>]>;
SDTypeProfile的作用是在 SelectionDAG 層級檢查 SDNode 的型別與結構是否合法- 其定義位於
llvm/include/llvm/Target/TargetSelectionDAG.td// SDTypeProfile - This profile describes the type requirements of a Selection // DAG node. class SDTypeProfile<int numresults, int numoperands, list<SDTypeConstraint> constraints> { int NumResults = numresults; int NumOperands = numoperands; list<SDTypeConstraint> Constraints = constraints; }numresults: 指定 SDNode 的 Result 數量numoperands: 指定 SDNode 的 Operand 數量SDTypeConstraint: 是用於描述每個 Result 和 Operand 的型別約束
在 CPU0 雖然定義了 SDTypeProfile,但目前並沒有實際應用在指令定義中,後續將使用 SDTNone 來跳過檢查
SDTNone: 是一個特殊的 SDTypeProfile,表示不對 SDNode 的型別和結構進行任何檢查def SDTNone : SDTypeProfile<0, 0, []>;- 在
llvm/include/llvm/Target/TargetSelectionDAG.td中有許多預設的 SDTypeProfile,例如:SDTisInt: 用於表示整數型別的 SDNodeSDTisFloat: 用於表示浮點型別的 SDNodeSDTisVector: 用於表示向量型別的 SDNode
SDNodeProperty
SDNodeProperty 是用來描述 SDNode 行為的 flag,是 SDNode 的第三個參數。例如:
SDNPHasChain: 表示該 SDNode 有 chain 輸入輸出、不能被重新排序- 常見於 load, store, call, ret 或具有 branch with side effect 的指令
SDNPInGlue: 表示該 SDNode 有 glue 輸入輸出,用於指令調度階段的依賴管理- 常見於需要緊密相鄰執行的指令,例如 compare 與 branch 指令
例如以下的指令:
CMP r1, r2 ; implicit-def SW
BEQ label ; implicit-use SW
如果只有 chain 而沒有 Glue 則只能保證 BEQ 在 CMP 之後執行,但無法保證 BEQ 一定要在 CMP 之後的下一個指令執行,可能會被插入其他的指令。因此要加入表示 CMP -- glue --> BEQ 來確保 BEQ 一定緊接在 CMP 之後執行。
branch with side effect 代表這個 branch 不只是「決定控制流往哪走」,它本身還具有可觀察的副作用。例如會影響 Memory 中的值,因此不能隨意移動、排序或者刪除
SDNode
之後會另外寫一篇專門介紹 SDNode 的文章,再詳細說明 SDNodeProperty 的使用,可以先參考 LLVM后端技术浅谈-自定义SDNode
def Cpu0Ret : SDNode<"Cpu0ISD::Ret", SDTNone,
[SDNPHasChain, SDNPOptInGlue, SDNPVariadic]>;
此處定義了 Cpu0Ret 的 SDNode,表示 CPU0 的返回 SDNode。大多數 ISA 都會自訂義 Ret SDNode 來表示函式返回,而不是使用預設的 ISD::RET。因為 Ret 幾乎完全是 ABI 相關的行為,不同架構的 Ret 行為差異很大,因此 ISD::RET 很少被直接使用。
Ret 通常涉及 Return address、Calling convention、Delay slot、Stack adjustment 等等,這些都是與 ABI 密切相關的行為
Operand
Operand 用於定義 Instruction 的操作數 (Operand) 類型
操作數 (Operand) 是指令中的參數,可以是寄存器、 立即數 (immediate) 或記憶體地址 (memory address) 等, 但 Register 已經由 RegisterClass 隱式提供, 因此在 Operand 中需要額外定義的是立即數和記憶體地址。
// Signed Operand
def simm16 : Operand<i32> {
let DecoderMethod= "DecodeSimm16";
}
// Address operand
def mem : Operand<iPTR> {
let PrintMethod = "printMemOperand";
let MIOperandInfo = (ops GPROut, simm16);
let EncoderMethod = "getMemEncoding";
}
Operand是 LLVM TableGen 中用來定義指令操作數的類型class Operand<ValueType ty> : DAGOperand- 定義位於
llvm/include/llvm/Target/Target.td
- 此處介紹在 CPU0 中所使用到的 field:
PrintMethod: 指定用於打印操作數的函式名稱- 例如
printMemOperand用於打印記憶體操作數
- 例如
MIOperandInfo: 定義操作數的組成部分,例如記憶體操作數由 GPROut 和 simm16 組成DecoderMethod: 指定用於解碼操作數的函式名稱EncoderMethod: 指定用於編碼操作數的函式名稱
在 Cpu0 中定義了兩個額外的 Operand:
simm16: 定義了一個 16 位元的有號立即數操作數- 使用
DecodeSimm16函式來解碼該操作數
- 使用
mem: 定義了一個記憶體地址操作數,由 GPROut 和 simm16 組成- 使用
printMemOperand函式來打印該操作數 - 由 GPROut 和 simm16 組成
- 代表該記憶體地址是由一個 GRPOut Register 和一個 16 位元的有號立即數偏移量組成
- 使用
getMemEncoding函式來編碼該操作數
- 使用
Zero 同樣包含在 GPROut 中,並且可以被用於記憶體地址計算,代表從地址 0 開始偏移,通常使用於絕對地址存取
PatLeaf
PatLeaf 用於在 Instruction Selection 階段中 DAG pattern matching 時的過濾條件
// Node immediate fits as 16-bit sign extended on target immediate.
// e.g. addi, andi
def immSExt16 : PatLeaf<(imm), [{ return isInt<16>(N->getSExtValue()); }]>;
PatLeaf 是用於在 Instruction Selection 階段中表示指令操作數的類型。這裡將 imm 作為過濾條件,
imm是 SelectionDAG 中的 Immediate 節點def imm : SDNode<"ISD::Constant", SDTIntLeaf, [], "ConstantSDNode">;
- 其位置於
llvm/include/llvm/Target/TargetSelectionDAG.td
因此 immSExt16 的作用是在 imm 上進行過濾,isInt<N> 是 LLVM 的輔助 Template 函數,
用於檢查一個整數值是否能夠被表示為 N 位元的有號整數。
/llvm/include/llvm/Support/MathExtras.h中定義了這個函式:/// Checks if an integer fits into the given bit width. template <unsigned N> constexpr inline bool isInt(int64_t x) { return N >= 64 || (-(INT64_C(1)<<(N-1)) <= x && x < (INT64_C(1)<<(N-1))); }getSExtValue()是ConstantSDNode的成員函式,用於取得該節點的有號擴展值
因此 immSExt16 定義表示,檢查一個 Immediate 節點的值是否能夠被表示為 16 位元的有號整數。
ComplexPattern
在 PatLeaf 處理時通常只看 SDNode,但在 ComplexPattern 中則需要去顯式聲明 SDNode 的內部欄位
def addr : ComplexPattern<iPTR, 2, "SelectAddr", [frameindex], [SDNPWantParent]>;
- ComplexPattern 用於處理更複雜的情況,先觀察 ComplexPattern 的定義:
- 定義位於
llvm/include/llvm/Target/TargetSelectionDAG.td:// Complex pattern definitions. // // Complex patterns, e.g. X86 addressing mode, requires pattern matching code // in C++. NumOperands is the number of operands returned by the select function; // SelectFunc is the name of the function used to pattern match the max. pattern; // RootNodes are the list of possible root nodes of the sub-dags to match. // e.g. X86 addressing mode - def addr : ComplexPattern<4, "SelectAddr", [add]>; // class ComplexPattern<ValueType ty, int numops, string fn, list<SDNode> roots = [], list<SDNodeProperty> props = [], int complexity = -1> { ValueType Ty = ty; int NumOperands = numops; string SelectFunc = fn; list<SDNode> RootNodes = roots; list<SDNodeProperty> Properties = props; int Complexity = complexity; } ValueType ty: 這個 Pattern 所期待的結果型別int numops: 該 Pattern 所產生的 Operand 數量- CPU0 address 為 base + offset = 2
- X86 address 為 base + index * scale + displacement = 4
string fn: 真正進行 Pattern match 後的處理函式名稱- 這個函式會在 C++ 端實作,這裡會呼叫該函式來進行匹配
list<SDNode> roots: 允許的根節點類型列表- 例如
[add, frameindex],該 SDNode opcode 必須是 add 或 frameindex
- 例如
list<SDNodeProperty> props: 該 Pattern 所需的 SDNodeProperty 列表- 例如
[SDNPWantParent],代表 fn 函式需要父節點作為額外參數
- 例如
int complexity: 多個 ComplexPattern 時的優先順序,數值越小優先匹配- 同一個根節點可能會有多個 ComplexPattern,透過 complexity 來決定優先匹配哪一個
這樣我們回頭去看 Cpu0 中的 addr ComplexPattern:
iPTR: 表示該 SDNode 的 ValueType 為指標型別2: 該 Pattern 處理後會產生兩個 Operand (base, offset)"SelectAddr": 用於處理該 Pattern 的函式名稱[frameindex]: 只允許根節點為 frameindex 的 SDNode[SDNPWantParent]: 將父節點傳遞給 SelectAddr 函式
PatLeaf 和 ComplexPattern 都是用於 Instruction Selection 階段的 Pattern matching,但 PatLeaf 通常用於較簡單的過濾條件,而 ComplexPattern 則用於處理更複雜的情況
PatFrag
class AlignedLoad<PatFrag Node> :
PatFrag<(ops node:$ptr), (Node node:$ptr), [{
LoadSDNode *LD = cast<LoadSDNode>(N);
return LD->getMemoryVT().getSizeInBits()/8 <= LD->getAlignment();
}]>;
class AlignedStore<PatFrag Node> :
PatFrag<(ops node:$val, node:$ptr), (Node node:$val, node:$ptr), [{
StoreSDNode *SD = cast<StoreSDNode>(N);
return SD->getMemoryVT().getSizeInBits()/8 <= SD->getAlignment();
}]>;
// Load/Store PatFrags.
def load_a : AlignedLoad<load>;
def store_a : AlignedStore<store>;
要理解這段 TableGen 代碼,首先需要了解 PatFrag 的概念。PatFrag 是用於定義可重用的模式片段 (pattern fragments),這些片段可以在多個指令定義中被引用,以避免重複定義相同的模式。
PatFrag的定義位於llvm/include/llvm/Target/TargetSelectionDAG.td:class PatFrag<dag ops, dag frag, code pred = [{}], SDNodeXForm xform = NOOP_SDNodeXForm>dag ops: 定義該 PatFrag 將會有哪些參數dag frag: 該 PatFrag 應該匹配的模式code pred: 一個可選的條件,用於在匹配後以 C++ 代碼做進一步的過濾SDNodeXForm xform: 用於在匹配後對 SDNode 進行轉換的函式
這樣我們先回頭看 Cpu0 中的 AlignedLoad:
(ops node:$ptr): 定義了該 PatFrag 接受一個參數 node,名稱為 $ptr(Node node:$ptr): 定義了該 PatFrag 應該匹配的模式,這裡是匹配由使用者傳入的 PatFrag Node[{ ... }]: 這段 C++ 代碼用於在匹配後進行進一步的過濾LoadSDNode *LD = cast<LoadSDNode>(N);- 將匹配到的 SDNode N 強制轉換為 LoadSDNode
return LD->getMemoryVT().getSizeInBits()/8 <= LD->getAlignment();- 檢查該 Load 指令的記憶體型別大小是否小於等於其對齊要求
- 例如左側為 load i32 (4 bytes), 則右側的記憶體對齊至少也要 4 bytes
- 存取大小 <= 對齊要求,表示該 Load 是對齊的
因為 LLVM IR 的 Load/Store 包含多種存取/對齊方式,因此需要在 PatFrag 中進行過濾,確保只匹配符合對齊要求的 Load/Store 指令
SD 基本上與 LD 是相同的,差別是 SD 在 DAG 中是有兩個 Operand (val, ptr) 所以需要兩個參數,而 LD 只有一個參數 (ptr) 剩下的是 Result
1.6 Instructions Specific Format
在完成了上述基礎設置後,接下來定義的是指令的具體格式,雖然指令可以被分為 R-type、I-type 和 J-type,但還是有許多指令具有特殊的格式需求,因此需要進一步細分成更具體可重用的格式。
Arithmetic & Logical
算數和邏輯指令的模板,使用之前定義好的 FL 來定義算術和邏輯指令的模板:
// Arithmetic and logical instructions with 2 register operands.
class ArithLogicI<bits<8> op, string instr_asm, SDNode OpNode,
Operand Od, PatLeaf imm_type, RegisterClass RC> :
FL<op, (outs GPROut:$ra), (ins RC:$rb, Od:$imm16),
!strconcat(instr_asm, "\t$ra, $rb, $imm16"),
[(set GPROut:$ra, (OpNode RC:$rb, imm_type:$imm16))], IIAlu> {
let isReMaterializable = 1;
}
/// Arithmetic Instructions (ALU Immediate)
// IR "add" defined in include/llvm/Target/TargetSelectionDAG.td, line 315 (def add).
def ADDiu : ArithLogicI<0x09, "addiu", add, simm16, immSExt16, CPURegs>;
ArithLogicI 相對來說比較簡單,我們觀察 ArithLogicI 的設計一共有六個參數:
bits<8> op: 指令的 Opcodestring instr_asm: 指令的組合語言表示,以 String 形式傳入SDNode OpNode: 指令對應的 SDNode,用於指令選擇階段Operand Od: 立即值運算元的 Operand 類型,用於在 MachineInstr 中表示立即值PatLeaf imm_type: 立即值的 PatLeaf 類型,用於在 Instruction Selection 階段過濾立即值RegisterClass RC: 來源暫存器所屬的暫存器類別
在 ArithLogicI 的定義中:
FL<...>: 繼承自之前定義的 FL (Format L-type)(outs GPROut:$ra): 定義指令的輸出操作數為 GPROut 類別的暫存器 $ra(ins RC:$rb, Od:$imm16): 定義指令的輸入操作數為 RC 類別的暫存器 $rb 和 Od 類別的立即值 $imm16!strconcat(instr_asm, "\t$ra, $rb, $imm16"):- 傳入的 instr_asm 格式化輸出為
instr_asm $ra, $rb, $imm16
- 傳入的 instr_asm 格式化輸出為
[(set GPROut:$ra, (OpNode RC:$rb, imm_type:$imm16))]: 匹配模式IIAlu: 指令的行程安排類別,在之後小節會介紹let isReMaterializable = 1;: 指示該指令是可重構的 (rematerializable),表示該指令的結果可以在需要時重新計算,而不需要保存到暫存器或記憶體中
rematerialization 代表如果這個值在之後很長一段時間沒有被使用到,compiler 可以選擇不保留這個值,而是在之後需要使用的時候重新計算它,這樣可以節省 register 或 memory 的使用。但如果是 side-effect 指令 (例如 store),就不能 rematerialize,因為它改變了程式的狀態必須透過保存來維持正確性
這樣我們來看 ADDiu 的定義:
0x09: 指令的 Opcode 為 0x09"addiu": 指令的組合語言表示為 “addiu”add: 指令對應的 SDNode 為 ISD::ADDsimm16: 立即值運算元的 Operand 要透過 simm16 來表示在 MachineInstr 中immSExt16: 立即值的 PatLeaf 類型為 immSExt16,用於過濾 16 位元有號立即值CPURegs: 來源暫存器所屬的暫存器類別為 CPURegs
Load & Store
class FMem<bits<8> op, dag outs, dag ins, string asmstr, list<dag> pattern,
InstrItinClass itin>: FL<op, outs, ins, asmstr, pattern, itin> {
bits<20> addr;
let Inst{19-16} = addr{19-16};
let Inst{15-0} = addr{15-0};
let DecoderMethod = "DecodeMem";
}
// Memory Load/Store
let canFoldAsLoad = 1 in
class LoadM<bits<8> op, string instr_asm, PatFrag OpNode, RegisterClass RC,
Operand MemOpnd, bit Pseudo>:
FMem<op, (outs RC:$ra), (ins MemOpnd:$addr),
!strconcat(instr_asm, "\t$ra, $addr"),
[(set RC:$ra, (OpNode addr:$addr))], IILoad> {
let isPseudo = Pseudo;
}
class StoreM<bits<8> op, string instr_asm, PatFrag OpNode, RegisterClass RC,
Operand MemOpnd, bit Pseudo>:
FMem<op, (outs), (ins RC:$ra, MemOpnd:$addr),
!strconcat(instr_asm, "\t$ra, $addr"),
[(OpNode RC:$ra, addr:$addr)], IIStore> {
let isPseudo = Pseudo;
}
//@ 32-bit load.
class LoadM32<bits<8> op, string instr_asm, PatFrag OpNode,
bit Pseudo = 0>
: LoadM<op, instr_asm, OpNode, GPROut, mem, Pseudo> {
}
// 32-bit store.
class StoreM32<bits<8> op, string instr_asm, PatFrag OpNode,
bit Pseudo = 0>
: StoreM<op, instr_asm, OpNode, GPROut, mem, Pseudo> {
}
/// Load and Store Instructions
/// aligned
def LD : LoadM32<0x01, "ld", load_a>;
def ST : StoreM32<0x02, "st", store_a>;
這裡定義了多層次的 Load 和 Store 指令模板,首先是 FMem 類別,然後是 LoadM 和 StoreM 類別,最後是 LoadM32 和 StoreM32 類別。
- FMem (Load/Store Memory 的基礎類別):
- 繼承自之前定義的 FL (Format L-type)
- 定義了記憶體地址欄位 addr,並指定其在指令編碼中的位置
let DecoderMethod = "DecodeMem";: 指定用於解碼記憶體操作數的函式名稱
- LoadM (Load 指令模板):
- 繼承自 FMem,定義了 Load 指令的模板
- 定義了輸出操作數為 RC 類別的暫存器 $ra,輸入操作數為 MemOpnd 類別的記憶體地址 $addr
let isPseudo = Pseudo;: 指示該指令是否為偽指令let canFoldAsLoad = 1;: 指示該 Load 指令可以被折疊 (folded) 成其他指令- 例如如果 addiu 支援記憶體存取,則可以將 load + addiu 折疊成一條 addiu 指令
addiu $rd, 0($addr), imm直接從記憶體做加法運算,省略 load 指令
- LoadM32 (32 位元 Load 指令模板):
- 繼承自 LoadM,專門用於 32 位元的 Load 指令
- 預設使用 GPROut 作為暫存器類別,mem 作為記憶體操作數類別
- 最後定義了具體的 Load 指令 LD:
0x01: 指令的 Opcode 為 0x01"ld": 指令的組合語言表示為 “ld”load_a: 使用之前定義的 load_a PatFrag 來過濾記憶體地址模式
設計多層次的 Load 和 Store 指令模板,其目的是為了提高指令定義的靈活性和可重用性。通過這種方式,可以透過更改 RegisterClass 或 Operand 類型來輕鬆定義不同變體的 Load 和 Store 指令,而不需要重複定義相同的指令結構。
例如要擴展為 i8 load/store,只要改變以下定義: 1. 定義新的 memory Operand (例如 mem8) 2. 重新定義對應的 PatFrag 3. 建立新的 LoadM8/StoreM8 類別繼承自 LoadM/StoreM 4. 定義具體的 LB/ SB 指令
這種設計的好處是最後的具體指令定義變得非常簡潔,只需要指定 Opcode、組合語言表示和 PatFrag。
Jump
//@JumpFR {
let isBranch=1, isTerminator=1, isBarrier=1, imm16=0, hasDelaySlot = 1,
isIndirectBranch = 1 in
class JumpFR<bits<8> op, string instr_asm, RegisterClass RC>:
FL<op, (outs), (ins RC:$ra),
!strconcat(instr_asm, "\t$ra"), [(brind RC:$ra)], IIBranch> {
let rb = 0;
let imm16 = 0;
}
//@JumpFR }
def JR : JumpFR<0x3c, "jr", GPROut>;
Jump 雖然是 FL 但通常只使用一個 Register 作為目標地址,因此定義了一個 JumpFR 類別來表示這種情況。
- 以下是 TableGen Instruction 的欄位:
isBranch=1: 指示該指令是一個分支指令isTerminator=1: 指示該指令是一個 Basic Block 的終止指令isBarrier=1: 指示該指令是一個屏障指令,在此之後的指令不會被執行到hasDelaySlot = 1: 指示該指令具有延遲槽 (delay slot)isIndirectBranch = 1: 指示該指令是一個間接分支指令,跳轉地址由 Register 提供
imm16,rb是在 FL 中定義的欄位,這裡將它們設為 0,因為 JumpFR 不需要這些欄位- 最後定義 JR 指令:
0x3c,"jr",GPROut
delay slot 是允許執行在分支指令之後的下一條指令,無論分支是否被採取都會執行該指令,如果要跳轉則直接改變 PC,否則繼續執行下一條指令
Return
// Return instruction
class RetBase<RegisterClass RC>: JumpFR<0x3c, "ret", RC> {
let isReturn = 1;
let isCodeGenOnly = 1;
let hasCtrlDep = 1;
let hasExtraSrcRegAllocReq = 1;
}
def RET : RetBase<GPROut>;
- 定義了一個 RetBase 類別,繼承自 JumpFR,表示返回指令的基類
let isReturn = 1;: 指示該指令是一個返回指令let isCodeGenOnly = 1;: 指示該指令僅在程式碼生成階段使用,最終的 ASM 不會包含該指令- 例如直接以
jr $ra來實現返回,而不需要額外的 RET 指令
- 例如直接以
let hasCtrlDep = 1;: 指示該指令具有控制依賴let hasExtraSrcRegAllocReq = 1;: 指示該指令在暫存器分配階段有額外的來源暫存器需求- 最後定義 RET 指令,使用 GPROut 作為暫存器類別
No Operation (NOP)
/// No operation
let addr=0 in
def NOP : FJ<0, (outs), (ins), "nop", [], IIAlu>;
空操作指令 (NOP) 的定義非常簡單,使用 FJ 類別來表示沒有任何操作的指令。
Pat
def : Pat<(i32 immSExt16:$in),
(ADDiu ZERO, imm:$in)>;
最後這段用於定義一個 Pat (Pattern),表示將一個 16 位元有號立即值的 i32 型別映射到 ADDiu 指令,並將結果存入 ZERO 寄存器。因為 CPU0 沒有設計專門的 load immediate 指令,因此使用 ADDiu ZERO, imm 來實現載入立即值的功能。
Last Edit
11-21-2025 22:13