Computer Organization | Pipelines Hazards
雖然 Pipeline 可以提升指令吞吐量,但在實作上會遇到各種 hazards 問題,必須透過硬體與編譯器的合作來解決這些問題,才能真正發揮 Pipeline 的效能。
這篇文章是從 Organization 的角度去思考 Pipeline Hazards,因此著重在硬體層面的解決方法。
1.4 Overview of Hazards
Pipeline processors 在控制指令於 pipeline 上順暢且高效率地執行時,會遇到數種相關問題。這些問題通常統稱為 hazards,主要可分為以下三種類型:
- Structural Hazards
- 不同指令在 Pipeline 的同一 Segment 需要使用相同的硬體資源,導致衝突
- 此類 hazard 可以透過發生衝突的 Segments 中配置重複的硬體資源來緩解
- 也可以透過插入 Stalls 或 Re-Ordering 指令來避免衝突
- Data Hazards
- 指令之間存在資料相依性,導致後續指令需要等待前一指令完成才能繼續執行
- 最簡單的解決方式是在執行序列中插入 Stalls (但會降低效能)
- 另一種方法是使用 Forwarding (Bypassing),提前將 ALU 的結果 Forward 給需要的指令,避免等待
- 在特定情況下可以 Re-Ordering 指令順序以避免 Data Hazards
- Control Hazards
- Control Hazards 通常由 Branch instructions 引起,因為在 Branch 指令執行期間,處理器無法確定下一條要執行的指令是哪一條
- 最簡單的解決方式是在 Branch 指令後插入 Stalls,做局部的等待事件直到 Branch 結果確定 (但會降低效能)
- 另一種方法是使用 Branch Prediction,預測 Branch 的結果並提前載入預測的指令 (但實作上相當困難)
- 或者 Delay Branch,將 Branch 指令的效果延後到後續的指令執行完畢後再決定 (需要編譯器支援)
接下來我門會針對每一種 Hazard 類型進行詳細說明,並介紹相應的解決方法。
在上述的三種 Hazards 中,Data Hazards 是最常見且影響最大的,因為指令之間的資料相依性非常普遍,而有效地解決 Data Hazards 可以顯著提升 Pipeline 的效能。
而從編譯器的角度來看實際上可以處裡的只有 Data Hazards 與 Control Hazards,Structural Hazards 通常需要硬體層面的支援來解決。
1.5 Data Hazards
Definition:
如果我們需要前一條指令的結果,但 Pipeline 中沒有足夠的 Segments 能在目前 Instruction 讀取該結果之前完成計算並寫回 Register,就會發生 Data Hazard。
通常使用以下三種方式來解決 Data Hazards:
- Forwarding (Bypassing)
- 為了處理 Dependency Hazard,可以在 Pipeline 中加入特殊電路,由 wires 與 switches 組成,將所需要的值 Forward 給該值進行計算的 Pipeline Segment。但這會增加硬體與控制電路的複雜度,但此方法有效,時間上遠小於完成 Pipeline 所需的時間。
- Code Re-Ordering
- 由 Compiler 來重新排序 Source code 的 Statements,或者由 Assembler 重新排序 Object code。將一條或多條 Instruction 插入到兩條有 Data Hazard 的 Instruction 之間,讓 Pipeline 有足夠的時間完成前一條 Instruction 的計算並寫回 Register,避免 Data Hazard 的發生。
- 這需要一個強大的 compiler 或 assembler,其必須具備 pipeline 結構與時序的詳細資訊,才能判斷 data hazard 可能發生的位置。我們將這類軟體稱為 hardware-dependent compiler。
- Stalls
- 最簡單的解決方式是在發生 Data Hazard 的地方插入 NOP 指令,讓 Pipeline 有足夠的時間完成前一條 Instruction 的計算並寫回 Register,避免 Data Hazard 的發生。但這會降低 Pipeline 的效能。
- 這種方法是最後手段,只有 Compiler 無法處理或者 Hardware/Software 不支援 Forwarding 時才會使用。
Example:
0 sub x2, x1, x3 // Register x2 set by sub
1 and x12, x2, x5 // 1st operand(z2) set by sub
2 or x13, x6, x2 // 2nd operand(x2) set by sub
3 add x14, x2, x2 // 1st(x2) & 2nd(x2) set by sub
4 sd x15, 100(x2) // Index(x2) set by sub
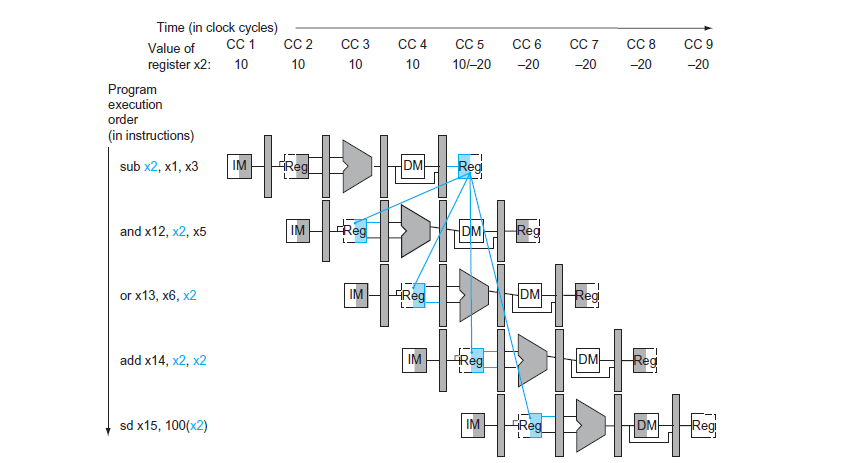
- 以上的問題出在 sub 指令在 CC 5 才會將 x2 的結果寫回 x2,如果未使用任何解決方法則所有要使用 x2 的指令都必須在 CC 6 之後才能執行
- 這裡的解決方式是使用 Forwarding,將 ALU 的結果直接 Forward 給需要的指令,避免等待寫回 Register 的時間,這樣 and, or, add 三個使用 x2 的指令就可以在 CC 6, 7, 8 執行,而不需要等待到 CC 5 之後才能執行
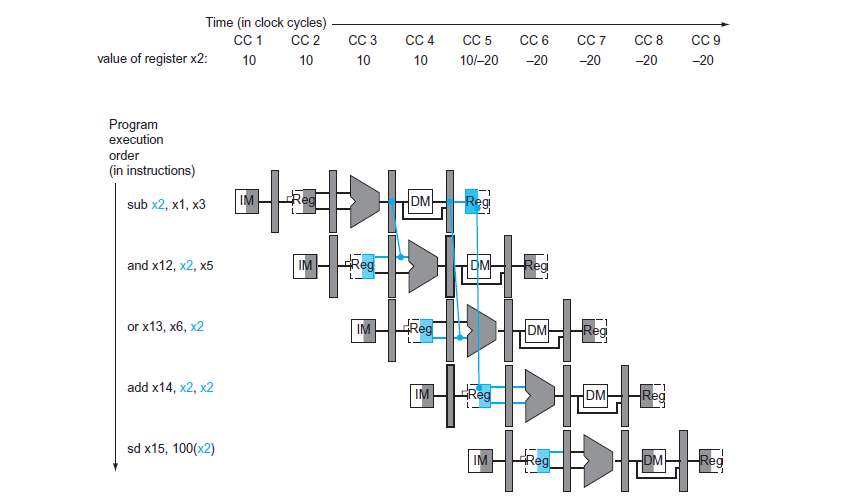
1.6 Structural Hazards
Definition: 在某一個 Pipeline Segment 中,如果有兩條或以上的指令同時需要使用同一個硬體資源,就會發生 Structural Hazard。
這裡我們使用相同的程式碼來說明 Structural Hazard 的問題:
- 在 0 sub x2, x1, x3 指令的 CC 5 時間需要將結果寫回 Register
- 在 3 add x14, x2, x2 指令的 CC 5 時間也需要從 Register 讀取 x2 的值
也就是說在 CC 5 的時間點,write back 與 read 兩個動作同時需要使用 Register x2 這個硬體資源,導致 Structural Hazard 的發生。在某一個 clock cycle 中,Register 可能產生不同的值,這種不一致是不可以被接受的。
- 修改 Register File 的設計,例如在 clock cycle 的前半段進行讀取,後半段進行寫入,這樣就可以避免 read 與 write 同時發生的問題。但這會增加 Register File 的複雜度與成本。
- 硬體設計者有時會在 write 與 read 之間插入相對於 clock cycle 很短的延遲,以確保 write 完成後 read 才會發生
- 另一種 Hazard 可能發生在 Branch Instructions 的執行期間,例如只有一個 ALU 但必須同時進行 BTA (Branch Target Address) 計算與條件判斷。這必須要至少有兩個 adder 才有辦法解決這個問題。( 新增硬體資源 )
- 同樣的如果 instruct 與 data 共用同一個 memory,可能會發生 Instruction Fetch 與 Data Memory Access 同時需要使用 memory 的情況。
- 第一種方法是跟 1 的解決方式類似,在同一個 clock cycle 中分開進行 read 與 write,讓 read 與 write 可以在一個 clock cycle 中分別完成。
- 第二種方法是使用兩個 High speed Cache,一個用於 instruction,一個用於 data,兩者都存取同一個 Memory。
第三種作法就是 I-Cache 與 D-Cache 分開設計,這樣就可以避免 Instruction Fetch 與 Data Memory Access 同時需要使用同一個 memory 的問題。
現代計算機的處理方式大多是後者,CPU 使用兩種 Cache 來分別處理 Instruction 與 Data,這樣可以大幅提升記憶體存取的效率,並且避免 Structural Hazards 的發生。
1.7 Control Hazards
Definition: Control Hazards 發生在 Branch Instructions 的執行期間,因為在 Branch 指令執行期間,處理器無法確定下一條要執行的指令是哪一條。
Control Hazards 是 Pipeline 中最難解決的問題之一,因為它涉及到指令流的改變,這會影響到整個 Pipeline 的運作。
Branch 的問題在於我們無法知道哪一種結果會發生,直到 Branch condition 被計算完成,並且往往 Branch 指令會依賴前面的指令結果,這使得預測變得更加困難。
主要有四種策略來處理 Control Hazards:
1.7.1 Assume Branch Not Taken
這個策略就是無論如何都假設 Branch 不會發生,繼續往下執行下一條指令。如果 Branch 最終被採取,則必須清除 Pipeline 中已經載入的錯誤指令,並重新載入正確的指令。 很顯而易見的這樣的策略就是 50% 的機率會成功,另外 50% 的機率會失敗,失敗的代價是清除 Pipeline 中的錯誤指令,並重新載入正確的指令,這會導致 Pipeline Stalls。
1.7.2 Reducing Branch Delay
另一種策略是將 Branch condition 的計算提前,例如在 ID 階段就計算 Branch condition,這樣已經跑入 ID 之後階段的 Instructions 被 Flush 的指令數量就可以減少。
以下圖為例,假如我們要到 WB 才寫回 Register,那麼在 CC 5 時才知道 Branch 的結果,這樣至少要有 4 個 Stalls 才能重新載入正確的指令。
| Cycle | IF | ID | EXE | MEM | WB |
|---|---|---|---|---|---|
| CC1 | beq | ||||
| CC2 | stall₁ | beq | |||
| CC3 | stall₂ | stall₁ | beq | ||
| CC4 | stall₃ | stall₂ | stall₁ | beq | |
| CC5 | add | beq |
- 這裡把 beq 提前到 ID 階段就計算 Branch condition,這樣就可以提前知道 Branch 的結果,減少 Stalls 的數量。
- 以 beq 為例只要加入 XOR 與 Zero 檢測器就可以在 ID 階段計算 Branch condition,這樣在 CC 3 時就可以知道 Branch 的結果,減少 Stalls 的數量。
- A xor B -> if Zero -> Branch Taken else Branch Not Taken
- 只加入專用的硬體來計算 Branch condition,不需要完整的 ALU 來計算
Xor 為零代表兩個輸入相等,因此 Branch condition 為真,Branch Taken
這種方法需要再 ID 加入一些額外的硬體來計算 Branch condition,但可以顯著減少 Control Hazards 的影響。
即使有可能 Branch 的值須要其他 Instruction 的結果才能計算出來,這樣我們就有可能造成 Data Hazard,但將 Branch condition 提前到 ID 階段計算,依然是一種改進。
1.7.3 Dynamic Branch Prediction
如果可以預測大多數 Branch 是 Taken 或 Not Taken,將會很有幫助。這可以透過 Software ( Compiler ),也可以在 Runtime ( Hardware ) 進行。這邊會先看軟體的方法,因為軟體方法實作成本相當低。
0 add x5, x5, x6 # One of the registers used in the beq comparison is modified here
1 sub x4, x3, x6 # Nothing important to the branch here
2 and x7, x8, x6 # Nothing important to the branch here
3 and x9, x6, x6 # Nothing important to the branch here
4 beq x5, x6, target # Branch compares the updated x5 with x6
Pre-executing the branch condition
Branch 會比較 x5, x6 的值,但這兩個 Register 最後一次修改是在 add 指令中,因此可以事先計算 sub x10, x5, x6 並檢查 x10 是否為零,來預測 Branch 的結果。
History-based prediction
這種作法的一種實作方式,是 branch prediction buffer 或 branch history table,這是一個小型的 Cache,記錄每個 Branch 指令的歷史結果,並使用這些結果來預測未來的 Branch 結果。通常會使用 Branch Instruction 的低位元作為 index 去查詢 Branch History Table,並根據歷史結果來預測 Branch 的結果。
這個 cache 通常稱為 Branch History Table (BHT),它會記錄每個 Branch 指令的歷史結果,並使用這些結果來預測未來的 Branch 結果。
這種預測方式當然有可能遇到該 Bit 是由另一個相同低位元的 Branch 指令所更新,但 Prediction 只是希望去猜測 Branch 的結果,如果該次錯誤刪除預測並更新 BHT 即可,這樣保證長期來看 BHT 的準確率會提升。
算盤本上會介紹 1-bit predictor 與 2-bit predictor:
- 1-bit predictor:
- 使用一個 Bit 來記錄上一次 Branch 的結果,0 代表 Not Taken,1 代表 Taken。每次 Branch 執行後,根據實際結果更新該 Bit。
- 優點是實作很簡單
- 缺點是容易受到單一錯誤預測的影響,導致連續錯誤預測
- 2-bit predictor:
- 使用兩個 Bit 來記錄 Branch 的歷史結果,形成四個狀態:
- 00: Strongly Not Taken
- 01: Weakly Not Taken
- 10: Weakly Taken
- 11: Strongly Taken
- 2-bit 可以讓預測器在遇到單一錯誤預測時不會立即改變預測結果,必須連續兩次錯誤預測才會改變狀態,這樣可以減少錯誤預測的影響,並且成本不會比 1-bit predictor 高太多。
- 使用兩個 Bit 來記錄 Branch 的歷史結果,形成四個狀態:
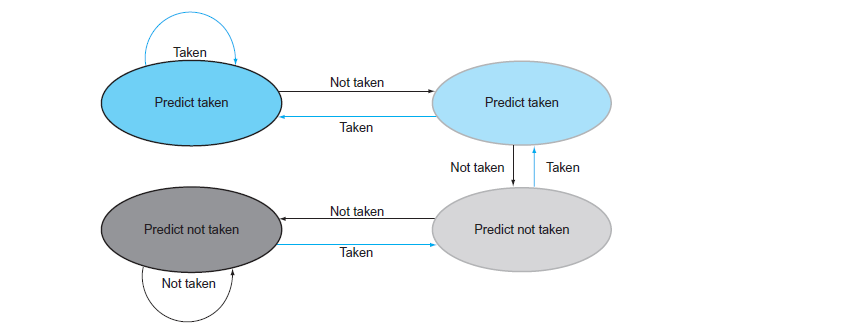
尤其是在 Loop 結構中,往往 Branch 會連續多次被採取直到 Loop 結束,Dynamic Branch Prediction 可以有效提升這類情況的預測準確率。
Last Edit
剩下 Exception Hazards 的部分之後再補充,Hazards 的內容先 focus 在 Compiler 比較關注的部分。
11-14-2025 00:42